Resources
Find the latest news & updates on AWS

Cloudtech Has Earned AWS Advanced Tier Partner Status
We’re honored to announce that Cloudtech has officially secured AWS Advanced Tier Partner status within the Amazon Web Services (AWS) Partner Network!
We’re honored to announce that Cloudtech has officially secured AWS Advanced Tier Partner status within the Amazon Web Services (AWS) Partner Network! This significant achievement highlights our expertise in AWS cloud modernization and reinforces our commitment to delivering transformative solutions for our clients.
As an AWS Advanced Tier Partner, Cloudtech has been recognized for its exceptional capabilities in cloud data, application, and infrastructure modernization. This milestone underscores our dedication to excellence and our proven ability to leverage AWS technologies for outstanding results.
A Message from Our CEO
“Achieving AWS Advanced Tier Partner status is a pivotal moment for Cloudtech,” said Kamran Adil, CEO. “This recognition not only validates our expertise in delivering advanced cloud solutions but also reflects the hard work and dedication of our team in harnessing the power of AWS services.”
What This Means for Us
To reach Advanced Tier Partner status, Cloudtech demonstrated an in-depth understanding of AWS services and a solid track record of successful, high-quality implementations. This achievement comes with enhanced benefits, including advanced technical support, exclusive training resources, and closer collaboration with AWS sales and marketing teams.
Elevating Our Cloud Offerings
With our new status, Cloudtech is poised to enhance our cloud solutions even further. We provide a range of services, including:
- Data Modernization
- Application Modernization
- Infrastructure and Resiliency Solutions
By utilizing AWS’s cutting-edge tools and services, we equip startups and enterprises with scalable, secure solutions that accelerate digital transformation and optimize operational efficiency.
We're excited to share this news right after the launch of our new website and fresh branding! These updates reflect our commitment to innovation and excellence in the ever-changing cloud landscape. Our new look truly captures our mission: to empower businesses with personalized cloud modernization solutions that drive success. We can't wait for you to explore it all!
Stay tuned as we continue to innovate and drive impactful outcomes for our diverse client portfolio.


How does AWS cloud migration help SMBs outpace competitors?
Small and medium-sized businesses (SMBs) that moved to the cloud have reduced their total cost of ownership (TCO) by up to 40%. Before migrating, they struggled with high infrastructure costs, unreliable systems, limited IT resources, and difficulty scaling or switching vendors.
By moving to AWS, businesses not only cut costs but also gain the ability to launch faster, scale on demand, and build customer-centric features. This has been more efficient than the legacy-bound peers for SMBs. Services like Amazon EC2, Amazon RDS, AWS Fargate, Amazon CloudWatch, and AWS Backup enabled them to drive agility and resilience.
Today, some of the most competitive businesses are working with AWS partners to migrate their core workloads. This article covers the benefits of AWS cloud migration and how AWS partners can help SMBs maximize their return on investment and position themselves for long-term success.
Key takeaways:
- Migration is a modernization opportunity: Moving to AWS helps SMBs replace outdated infrastructure with scalable, secure, and cost-effective cloud environments that support long-term growth.
- Strategic execution maximizes benefits: Certified partners align each migration phase with business goals, ensuring the right AWS services are used, risks are minimized, and long-term value is realized.
- Data-driven planning ensures smarter outcomes: Tools like AWS Migration Evaluator reveal infrastructure gaps, compliance risks, and cost inefficiencies, enabling the development of an informed migration strategy.
- Security and scalability are built from the start: Architectures include multi-AZ deployments, automated backups, IAM controls, and real-time monitoring to ensure business continuity.
- Cloudtech simplifies the path to innovation: Along with cloud migration and modernization, Cloudtech helps SMBs adopt AI, improve governance, and continuously optimize for performance and cost.
Why should SMBs choose AWS cloud migration?
Among the available options, AWS Cloud migration is a top choice for SMBs. It offers the depth, flexibility, and reliability needed to modernize with confidence. AWS provides over 200 services across compute, storage, analytics, AI/ML, and IoT. This makes it the most comprehensive cloud platform on the market.
Its global infrastructure includes the highest number of availability zones and regions. This ensures low-latency performance and high availability for users worldwide. AWS also has a large partner network, including Advanced Tier partners like Cloudtech, who guide SMBs through tailored migration plans.
With flexible pricing, built-in cost optimization tools, and strong third-party integrations, AWS is more adaptable than many rigid, bundled alternatives.
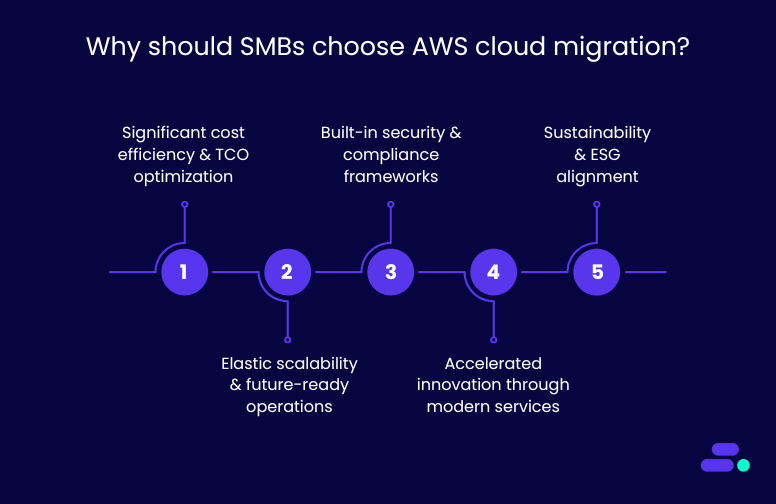
Here are some of the key reasons why businesses need AWS Cloud migration:
1. Significant cost efficiency and TCO optimization
Migrating to the AWS Cloud helps SMBs cut capital expenses tied to owning and maintaining on-premise hardware. It reduces costs related to servers, storage, power, cooling, security, and ongoing maintenance. Instead, businesses pay only for the resources they actually use.
AWS offers granular pricing options like reserved instances, savings plans, and auto-scaling. These help SMBs manage costs more effectively. Cloud migration also frees up IT teams from routine maintenance, so they can focus on innovation, product development, and improving customer experiences.
Take the example of a global IT staffing firm struggling with high Elastic licensing fees, frequent downtime, and a self-managed Elastic (ELK) stack that demanded eight engineers. With the help of Cloudtech, an advanced tier AWS partner, it migrated the log analytics to a managed architecture using Amazon OpenSearch Service, AWS Fagate, Amazon EKS, and Amazon ECR. This eliminated their maintenance overhead and improved reliability.
The result: 40% lower costs, 80% less downtime, and real-time insights that now power faster, data-driven business decisions.
2. Elastic scalability and future-ready operations
AWS allows SMBs to scale resources instantly based on demand, whether it’s a traffic spike, seasonal peak, or business growth. This flexibility keeps operations efficient and avoids unnecessary overhead.
Built-in tools like infrastructure-as-code, automated monitoring, and centralized dashboards give teams better control and visibility. They can track performance, spot issues early, and adjust resources in real time.
Migration also sets the stage for long-term modernization. SMBs can adopt containerization, DevOps, and AI-driven automation to stay competitive.
3. Built-in security and compliance frameworks
AWS invests billions in securing its infrastructure, offering SMBs access to enterprise-grade security capabilities, including:
- Encryption at rest and in transit
- Multi-Factor Authentication (MFA)
- Identity and Access Management (IAM)
- Automated threat detection via Amazon GuardDuty
Beyond these, AWS supports over 90 security and compliance standards globally (e.g., GDPR, ISO 27001, HIPAA), allowing SMBs in regulated industries to meet requirements without building capabilities from scratch.
AWS Security Hub centralizes findings across Amazon GuardDuty, IAM, and AWS Config, making it easier for lean SMB teams to maintain a secure posture without managing dozens of tools. Alerts are prioritized by severity, and GuardDuty detects threats like suspicious IP access, brute-force attempts, or exposed ports
Importantly, AWS operates on a shared responsibility model. While AWS secures the infrastructure, businesses maintain control over how they configure and protect their applications and data.
4. Accelerated innovation through modern services
AWS enables faster go-to-market and experimentation with modern services such as:
- Amazon Aurora for fully managed, scalable databases
- Amazon SageMaker for ML-based insights
- AWS Lambda for serverless computing
- Amazon QuickSight and Q Business for embedded analytics
For example, with Amazon Aurora, updates, failovers, and backups are handled automatically — no DBA needed. With Amazon SageMaker, you don’t need a dedicated ML team. Pre-built models and low-code tools let your developers build and deploy predictions using real business data.
These services empower SMBs to innovate with minimal upfront investment, enabling agile development cycles, real-time analytics, and intelligent automation.
5. Sustainability and ESG alignment
AWS’s energy-efficient, globally optimized data centers help SMBs cut operational costs and reduce their carbon footprint. With advanced cooling, efficient server use, and smart workload distribution, AWS consumes significantly less energy than traditional on-premise setups.
AWS achieves higher efficiency through advanced power utilization, custom hardware design, and global workload orchestration. For example, by shifting analytics workloads to regions powered by renewable energy, SMBs can directly reduce their compute-related emissions without changing their application code.
For SMBs aiming to meet ESG goals, migrating to AWS offers a clear path to sustainability without added complexity. AWS is on track to use 100% renewable energy by 2025, with many regions already powered by clean energy.
What You Get With AWS Cloud Migration
- Built-in automation (patching, failovers, scaling)
- Real-time visibility with Amazon CloudWatch and AWS Cost Explorer
- Security without headcount (MFA, AWS GuardDuty, AWS Security Hub)
- Smarter cost control (Savings Plans + tagging setup)
- Modern services, minus steep learning curves (Amazon SageMaker, Amazon Aurora)
- Cleaner ESG profile without re-architecting apps
However, implementing AWS Cloud migration is no easy task. It requires careful planning and strategic guidance for achieving the best results.
Strategies to maximize the benefits of AWS Cloud migration
Many SMBs still operate on aging on-prem servers, custom-built tools, and fragmented data systems. These environments are costly to maintain, difficult to scale, and limit innovation. Cloud migration offers a chance to rethink how IT drives growth and efficiency.
However, attempting this transition without expert support can lead to misconfigurations, downtime, or runaway costs. AWS partners bring deep technical expertise, proven frameworks, and real-world experience to guide SMBs through every step. They help ensure migrations are not only secure and smooth but also aligned with long-term business strategy.
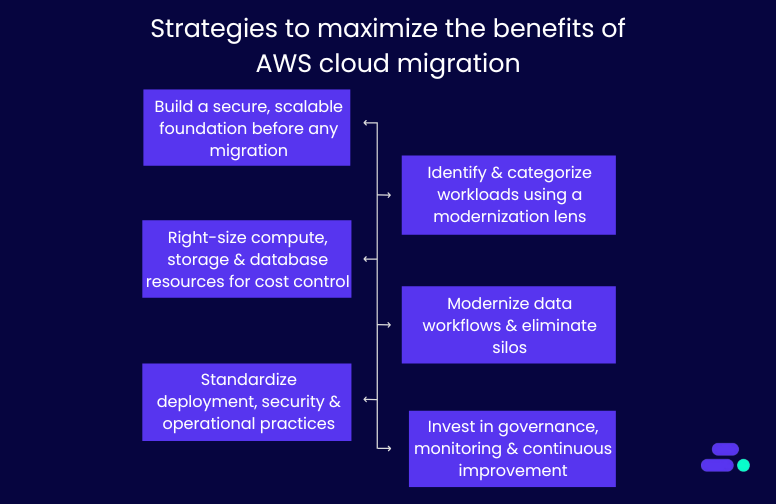
Let’s break down five core strategies AWS partners follow to help SMBs migrate to the cloud and prepare them to lead in their markets, not just survive:
1. Build a secure, scalable foundation before any migration
Unstructured cloud adoption often leads to fragmented environments, inconsistent access controls, and long-term governance issues. That’s why experienced AWS partners begin by setting up a foundational landing zone using AWS Control Tower and multi-account architecture.
Key technical components include:
- Account segmentation: Workloads are isolated into separate accounts (e.g., dev, staging, production) using AWS Organizations, improving security and cost tracking.
- Network design: Virtual private clouds (VPCs) are built across multiple availability zones for fault tolerance and high availability.
- Security baselines: Partners enforce least-privilege IAM policies, default encryption (via AWS KMS), and logging using AWS CloudTrail.
- Automated guardrails: Tools like AWS Config and service control policies (SCPs) ensure compliance and prevent misconfigurations.
This upfront setup prevents issues down the line and ensures your cloud environment scales without exposing security or operational risks.
2. Identify and categorize workloads using a modernization lens
Not every workload should be treated the same. SMBs often have legacy ERP systems, aging virtual machines, or custom scripts that are no longer efficient or scalable. AWS partners use various evaluation tools to profile and categorize each workload.
The strategy is to assess current infrastructure across dimensions, including resource usage (CPU, memory, disk I/O), software stack (OS, dependencies, licenses), system interdependencies, and compliance needs (HIPAA, PCI, GDPR). It also accounts for existing costs, including hardware, facilities, and support.
This analysis shapes a tailored cloud migration strategy using the 7 Rs framework:
- Rehost (lift-and-shift): Move applications as-is from on-premises to AWS without major changes. For example, a healthcare provider moves its legacy appointment scheduling software from local servers to Amazon EC2. No code changes are made, but the system now benefits from cloud uptime and centralized management.
- Replatform (lift-tinker-and-shift): Make minimal changes to optimize the app for cloud, often switching databases or OS-level services. For example, an SMB in financial services moves from an on-prem Oracle database to Amazon RDS for PostgreSQL, reducing licensing costs while maintaining similar functionality and improving automated backups and patching.
- Refactor (re-architect): Redesign the application to take full advantage of cloud-native features like microservices, containers, or serverless. For example, a patient intake form system is rebuilt using AWS Lambda, Amazon API Gateway, and Amazon DynamoDB, enabling the healthcare company to scale intake automatically without paying for idle resources.
- Repurchase: Switch from a legacy, self-managed system to a SaaS or AWS Marketplace alternative. For example, a retail business retires its in-house CRM and adopts Salesforce or Zendesk hosted on AWS to modernize customer support and reduce infrastructure maintenance.
- Retire: Shut down systems or services that are no longer useful. For example, during migration discovery, an SMB identifies two reporting tools that are no longer used. These are retired, reducing licensing fees and operational overhead.
- Retain: Keep certain applications or workloads on-prem temporarily or permanently, especially if they're not cloud-ready. For example, a healthcare firm retains its legacy PACS system (used for radiology imaging), due to latency and compliance requirements, while migrating surrounding services like scheduling, billing, and analytics to AWS.
- Relocate: Move large-scale workloads (e.g., VMware or Hyper-V environments) directly into AWS without refactoring. For example, an SMB with hundreds of virtual machines running internal applications uses VMware Cloud on AWS to relocate its existing virtualization stack into the cloud for faster migration and operational consistency.
Read More: AWS cloud migration strategies explained: A practical guide.
These 7 strategies are typically used together during the cloud modernization engagement. Each workload is evaluated and categorized to ensure a strategic, cost-effective, and business-aligned migration.
3. Right-size compute, storage, and database resources for cost control
SMBs often overspend on cloud when workloads are lifted without optimization. So, AWS partners right-size every component to match real-world usage and align with budget constraints.
Key tactics include:
- Amazon EC2 instance sizing based on actual utilization trends over time, not static estimations.
- Storage tiering using Amazon S3 Intelligent-Tiering, EBS volume optimization, and lifecycle policies for cold data.
- Relational database migration to Amazon RDS or Amazon Aurora, with automated backups, replication, and patching.
- Auto Scaling Groups (ASGs) to handle variable traffic without overprovisioning.
- Pricing models like Savings Plans and Spot Instances can reduce ongoing compute costs.
This ensures the environment is financially sustainable as workloads increase over time.
4. Modernize data workflows and eliminate silos
Many SMBs store customer, sales, and operations data across disconnected platforms, limiting visibility and adding manual overhead. Cloud migration offers a chance to rebuild data infrastructure for real-time insights and scale.
AWS partners introduce:
- Centralized data lakes on Amazon S3, partitioned and cataloged using AWS Glue Data Catalog.
- ETL pipelines using AWS Glue, AWS Lambda, and AWS Step Functions to automate data ingestion and transformation.
- Analytics layers via Amazon Athena, AWS Redshift, or Amazon QuickSight, replacing static reports with interactive dashboards.
- Data governance using Lake Formation and IAM roles to control who can access sensitive data.
This structure supports everything from executive reporting to compliance audits, AI workloads, and process automation.
5. Standardize deployment, security, and operational practices
Legacy environments often depend on manual scripts and ad hoc changes, increasing the risk of errors and downtime. Migration is the ideal time to implement standardization using DevOps and infrastructure-as-code (IaC).
Partners help implement:
- IaC templates with AWS CloudFormation to make infrastructure reproducible and auditable.
- CI/CD pipelines with AWS CodePipeline or AWS CodeBuild for automated deployments.
- Secrets management using AWS Secrets Manager to avoid storing sensitive data in code.
- Automated rollbacks, blue/green deployments, and health checks to reduce deployment risks.
This shift reduces downtime, accelerates time-to-market, and improves software reliability.
6. Invest in governance, monitoring, and continuous improvement
Once migrated, workloads require active governance and observability to avoid sprawl, overuse, or compliance issues. AWS Partners stay engaged post-migration to optimize the environment over time.
This includes:
- Cost governance using AWS Budgets, AWS Cost Explorer, and tagging policies for project- or team-level reporting.
- Observability through Amazon CloudWatch dashboards, AWS CloudTrail logs, and custom alarms for anomalies or failures.
- Security hygiene using AWS Security Hub, AWS GuardDuty, and vulnerability scanning tools.
- Change management with access controls, patching automation, and audit trails.
- Training sessions to upskill your internal team on managing AWS environments confidently.
In addition, AWS Partners help build roadmaps for future innovation, whether that’s rolling out Amazon SageMaker for ML, Amazon Q Business for conversational analytics, or expanding into new regions.
Each of these strategies utilized by AWS partners ensures that SMBs don’t just replicate legacy inefficiencies in the cloud.
Therefore, with the right AWS partner, businesses can build a secure, scalable, and future-ready foundation that evolves with their goals.
How can Cloudtech support SMBs with AWS Cloud migration?
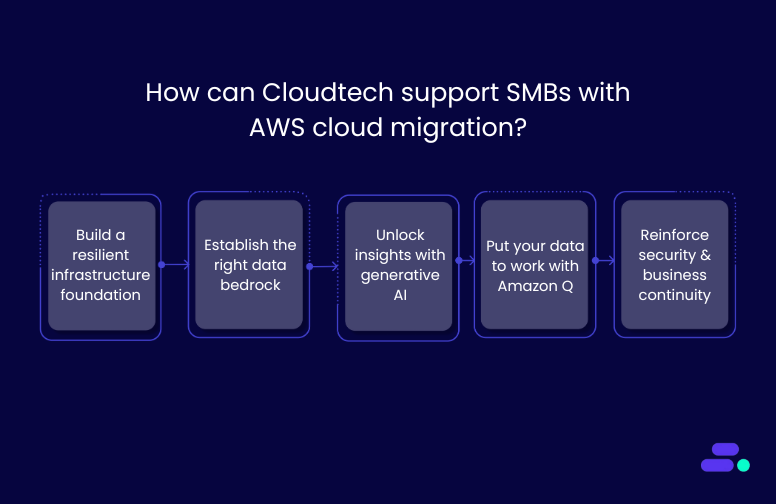
Cloudtech is an AWS Advanced Tier Partner that has helped multiple SMBs migrate from legacy systems to secure, scalable AWS environments with minimal disruption and maximum ROI. Their approach is tailored, efficient, and aligned with real business needs.
For businesses ready for AWS Cloud migration, Cloudtech can:
- Build a resilient infrastructure foundation: Cloudtech sets up the AWS environment with scalable compute and storage, account governance via AWS Control Tower, and baseline security controls. Through expert-led configuration and knowledge transfer, it creates a strong, adaptable foundation that grows with the business.
- Establish the right data bedrock: From database migrations to ETL pipelines and AWS Data Lake architecture, Cloudtech ensures data is ready for analytics and AI. This solid foundation improves accessibility, eliminates silos, and accelerates decision-making across teams.
- Unlock insights with AI: Cloudtech uses Amazon Textract to extract structured data from physical or handwritten documents. This extracted content can then be processed using tools like Amazon Comprehend to identify key insights, classify information, or detect entities. This eliminates manual entry and unlocks real business intelligence from previously unstructured documents.
- Put your data to work with Amazon Q: Cloudtech enables SMBs to use Amazon Q Business and Amazon Q in QuickSight to automate tasks, summarize data, and generate content. The result: faster decision-making, increased productivity, and better business outcomes through AI-powered intelligence.
- Reinforce security and business continuity: Cloudtech integrates cloud-native security best practices, proactive chaos engineering, automated backups, and disaster recovery strategies to enhance security and ensure business continuity. These tools help reduce downtime, safeguard data, and keep operations running, even in unpredictable scenarios.
Cloudtech doesn’t just migrate workloads. It equips SMBs with a secure, data-ready, and AI-optimized AWS environment—built for growth, efficiency, and long-term impact.
Conclusion
Migrating to AWS is more than a technology shift. It’s a strategic move toward building a scalable, secure, and future-ready business. With the right partner, SMBs can transform aging infrastructure into a flexible cloud environment that reduces costs, improves resilience, and unlocks innovation.
For SMBs ready to modernize with confidence, Cloudtech delivers tailored AWS migration services grounded in best practices and real-world impact. Whether you're moving a few workloads or re-architecting your entire IT landscape, Cloudtech helps you go further, faster. Get started now!
FAQs
1. What are the typical starting points for SMBs considering AWS migration?
Most SMBs begin with workloads that are costly to maintain or hard to scale on-premises, such as databases, file servers, or ERP systems. Cloudtech helps prioritize which workloads to migrate first based on business impact, cost savings, and technical feasibility.
2. How long does a cloud migration project take with Cloudtech?
Timelines vary by scope, but most SMB migrations can be completed in phases over 6 to 12 weeks. Cloudtech’s phased approach ensures minimal disruption by aligning migration waves with business operations and readiness.
3. What AWS tools are used to support a smooth migration?
Cloudtech uses AWS Migration Evaluator, AWS Application Migration Service (MGN), Database Migration Service (DMS), and the AWS Well-Architected Framework to ensure secure and efficient migration with minimal downtime.
4. Can Cloudtech help with compliance during and after migration?
Cloudtech builds AWS environments that follow security and compliance best practices aligned with standards like HIPAA, SOC 2, and PCI-DSS. While it does not perform formal audits or certification processes, Cloudtech ensures the infrastructure and automation it implements are audit-ready.
5. What happens after the migration is complete?
Cloudtech provides ongoing support, training, and optimization. This includes infrastructure monitoring, cost management, DevOps enablement, and roadmaps for adopting AI, serverless, and containerized applications in the future.

Building efficient ETL processes for data lakes on AWS
As data volumes continue to grow exponentially, small and medium-sized businesses (SMBs) face multiple challenges in managing, processing, and analyzing their data efficiently.
A well-structured data lake on AWS enables businesses to consolidate structured, semi-structured, and unstructured data in one location, making it easier to extract insights and inform decisions.
According to IDC, the global datasphere is projected to reach 163 zettabytes by the end of 2025, highlighting the urgent need for scalable, cloud-first data strategies.
This blog explores how SMBs can build effective ETL (Extract, Transform, Load) processes using AWS services and modernize their data infrastructure for improved performance and insight.
Key takeaways
- Importance of ETL pipelines for SMBs: ETL pipelines are crucial for SMBs to integrate and transform data within an AWS data lake.
- AWS services powering ETL workflows: Amazon Glue, Amazon S3, Amazon Athena, and Amazon Kinesis enable scalable, secure, and cost-efficient ETL workflows.
- Best practices for security and performance: Strong security measures, access control, and performance optimization are crucial to meet compliance requirements.
- Real-world ETL applications: Examples demonstrate how AWS-powered ETL supports diverse industries and handles varying data volumes effectively.
- Cloudtech’s role in ETL pipeline development: Cloudtech helps SMBs build tailored, reliable ETL pipelines that simplify cloud modernization and unlock valuable data insights.
What is ETL?
ETL stands for extract, transform, and load. It is a process used to combine data from multiple sources into a centralized storage environment, such as an AWS data lake.
Through a set of defined business rules, ETL helps clean, organize, and format raw data to make it usable for storage, analytics, and machine learning applications.
This process enables SMBs to achieve specific business intelligence objectives, including generating reports, creating dashboards, forecasting trends, and enhancing operational efficiency.
Why is ETL important for businesses?
Businesses and mostly SMBs typically manage structured and unstructured data from a variety of sources, including:
- Customer data from payment gateways and CRM platforms
- Inventory and operations data from vendor systems
- Sensor data from IoT devices
- Marketing data from social media and surveys
- Employee data from internal HR systems
Without a consistent process in place, this data remains siloed and difficult to use. ETL helps convert these individual datasets into a structured format that supports meaningful analysis and interpretation.
By utilizing AWS services, businesses can develop scalable ETL pipelines that enhance the accessibility and actionability of their data.
The evolution of ETL from legacy systems to cloud solutions
ETL (Extract, Transform, Load) has come a long way from its origins in structured, relational databases. Initially designed to convert transactional data into relational formats for analysis, early ETL processes were rigid and resource-intensive.
1. Traditional ETL
In traditional systems, data resided in transactional databases optimized for recording activities, rather than for analysis and reporting.
ETL tools helped transform and normalize this data into interconnected tables, enabling fundamental trend analysis through SQL queries. However, these systems struggled with data duplication, limited scalability, and inflexible formats.
2. Modern ETL
Today’s ETL is built for the cloud. Modern tools support real-time ingestion, unstructured data formats, and scalable architectures like data warehouses and data lakes.
- Data warehouses store structured data in optimized formats for fast querying and reporting.
- Data lakes accept structured, semi-structured, and unstructured data, supporting a wide range of analytics, including machine learning and real-time insights.
This evolution enables businesses to process more diverse data at higher speeds and scales, all while utilizing cost-efficient cloud-native tools like those offered by AWS.
How does ETL work?
At a high level, ETL moves raw data from various sources into a structured format for analysis. It helps businesses centralize, clean, and prepare data for better decision-making.
Here’s how ETL typically flows in a modern AWS environment:
- Extract: Pulls data from multiple sources, including databases, CRMs, IoT devices, APIs, and other data sources, into a centralized environment, such as Amazon S3.
- Transform: Converts, enriches, or restructures the extracted data. This could include cleaning up missing fields, formatting timestamps, or joining data sets using AWS Glue or Apache Spark.
- Load: Places the transformed data into a destination such as Amazon Redshift, a data warehouse, or back into S3 for analytics using services like Amazon Athena.
Together, these stages power modern data lakes on AWS, letting businesses analyze data in real-time, automate reporting, or feed machine learning workflows.
What are the design principles for ETL in AWS data lakes?

Designing ETL processes for AWS data lakes involves optimizing for scalability, fault tolerance, and real-time analytics. Key principles include utilizing AWS Glue for serverless orchestration, Amazon S3 for high-volume, durable storage, and ensuring efficient data transformation through Amazon Athena and AWS Lambda. An impactful design also focuses on cost control, security, and maintaining data lineage with automated workflows and minimal manual intervention.
- Event sourcing and processing within AWS services
Use event-driven architectures with AWS tools such as Amazon Kinesis or AWS Lambda. These services enable real-time data capture and processing, which keeps data current and workflows scalable without manual intervention.
- Storing data in open file formats for compatibility
Adopt open file formats like Apache Parquet or ORC. These formats improve interoperability across AWS analytics and machine learning services while optimizing storage costs and query performance.
- Ensuring performance optimization in ETL processes
Utilize AWS services such as AWS Glue and Amazon EMR for efficient data transformation. Techniques like data partitioning and compression help reduce processing time and minimize cloud costs.
- Incorporating data governance and access control
Maintain data security and compliance by using AWS IAM (Identity and Access Management), AWS Lake Formation, and encryption. These tools provide granular access control and protect sensitive information throughout the ETL pipeline.
By following these design principles, businesses can develop ETL processes that not only meet their current analytics needs but also scale as their data volume increases.
AWS services supporting ETL processes
AWS provides a suite of services that simplify ETL workflows and help SMBs build scalable, cost-effective data lakes. Here are the key AWS services supporting ETL processes:
1. Utilizing AWS Glue data catalog and crawlers
AWS Glue data catalog organizes metadata and makes data searchable across multiple sources. Glue crawlers automatically scan data in Amazon S3, updating the catalog to keep it current without manual effort.
2. Building ETL jobs with AWS Glue
AWS Glue provides a serverless environment for creating, scheduling, and monitoring ETL jobs. It supports data transformation using Apache Spark, enabling SMBs to clean and prepare data for analytics without managing infrastructure.
3. Integrating with Amazon Athena for query processing
Amazon Athena allows businesses to run standard SQL queries directly on data stored in Amazon S3. It works seamlessly with the Glue data catalog, enabling quick, ad hoc analysis without the need for complex data movement.
4. Using Amazon S3 for data storage
Amazon Simple Storage Service (S3) serves as the central repository for raw and processed data in a data lake. It offers durable, scalable, and cost-efficient storage, supporting multiple data formats and integration with other AWS analytics services.
Together, these AWS services form a comprehensive ETL ecosystem that enables SMBs to manage and analyze their data effectively.
Steps to construct ETL pipelines in AWS
The how-to approach to ETL pipeline construction using AWS services, with Cloudtech guiding businesses at every stage of the modernization journey.
1. Mapping structured and unstructured data sources
Begin by identifying all data sources, including structured sources like CRM and ERP systems, as well as unstructured sources such as social media, IoT devices, and customer feedback. This step ensures full data visibility and sets the foundation for effective integration.
2. Creating ingestion pipelines into object storage
Use services like AWS Glue or Amazon Kinesis to ingest real-time or batch data into Amazon S3. It serves as the central storage layer in a data lake, offering the flexibility to store data in raw, transformed, or enriched formats.
3. Developing ETL pipelines for data transformation
Once ingested, use AWS Glue to build and manage ETL workflows. This step involves cleaning, enriching, and structuring data to make it ready for analytics. AWS Glue supports Spark-based transformations, enabling efficient processing without manual provisioning.
4. Implementing ELT pipelines for analytics
In some use cases, it is more effective to load raw data into Amazon Redshift or query directly from S3 using Amazon Athena.
This approach, known as ELT (extract, load, transform), allows SMBs to analyze large volumes of data quickly without heavy transformation steps upfront.
Best practices for security and access control

Security and governance are essential parts of any ETL workflow, especially for SMBs that manage sensitive or regulated data. The following best practices help SMBs stay secure, compliant, and audit-ready from day one.
1. Ensuring data security and compliance
Use AWS Key Management Service (KMS) to encrypt data at rest and in transit, and apply policies that restrict access to encryption keys. Consider enabling Amazon Macie to automatically discover and classify sensitive data, such as personally identifiable information (PII).
For regulated industries like healthcare, ensure all data handling processes align with standards such as HIPAA, HITRUST, or GDPR. AWS Config can help enforce compliance by tracking changes to configurations and alerting when policies are violated.
2. Managing user access with AWS Identity and Access Management (IAM)
Create IAM policies based on the principle of least privilege, giving users only the permissions required to perform their tasks. Use IAM roles to grant temporary access for third-party tools or workflows without compromising long-term credentials.
For added security, enable multi-factor authentication (MFA) and use AWS Organizations to apply access boundaries across business units or teams.
3. Implementing effective monitoring and logging practices
Use AWS CloudTrail to log all API activity, and integrate Amazon CloudWatch for real-time metrics and automated alerts. Pair this with AWS GuardDuty to detect unexpected behavior or potential security threats, such as data exfiltration attempts or unusual API calls.
Logging and monitoring are particularly important for businesses working with sensitive healthcare data, where early detection of irregularities can prevent compliance issues or data breaches.
4. Auditing data access and changes regularly
Set up regular audits of who accessed what data and when. AWS Lake Formation offers fine-grained access control, enabling centralized permission tracking across services.
SMBs can use these insights to identify access anomalies, revoke outdated permissions, and prepare for internal or external audits.
5. Isolating environments using VPCs and security groups
Isolate ETL components across development, staging, and production environments using Amazon Virtual Private Cloud (VPC).
Apply security groups and network ACLs to control traffic between resources. This reduces the risk of accidental data exposure and ensures production data remains protected during testing or development.
By following these practices, SMBs can build trust into their data pipelines and reduce the likelihood of security incidents.
Also Read: 10 Best practices for building a scalable and secure AWS data lake for SMBs
Understanding theory is great, but seeing ETL in action through real-world examples helps solidify these concepts.
Real-world examples of ETL implementations
Looking at how leading companies use ETL pipelines on AWS offers practical insights for small and medium-sized businesses (SMBs) building their own data lakes. The tools and architecture may scale across business sizes, but the core principles remain consistent.
Sisense: Flexible, multi-source data integration
Business intelligence company Sisense built a data lake on AWS to handle multiple data sources and analytics tools.
Using Amazon S3, AWS Glue, and Amazon Redshift, they established ETL workflows that streamlined reporting and dashboard performance, demonstrating how AWS services can support diverse, evolving data needs.
IronSource: real-time, event-driven processing
To manage rapid growth, IronSource implemented a streaming ETL model using Amazon Kinesis and AWS Lambda.
This setup enabled them to handle real-time mobile interaction data efficiently. For SMBs dealing with high-frequency or time-sensitive data, this model offers a clear path to scalability.
SimilarWeb: scalable big data processing
SimilarWeb uses Amazon EMR and Amazon S3 to process vast amounts of digital traffic data daily. Their Spark-powered ETL workflows are optimized for high-volume transformation tasks, a strategy that suits SMBs looking to modernize legacy data systems while preparing for advanced analytics.
AWS partners, such as Cloudtech, work with multiple such SMB clients to implement similar AWS-based ETL architectures, helping them build scalable and cost-effective data lakes tailored to their growth and analytics goals.
Choosing tools and technologies for ETL processes
For SMBs building or modernizing a data lake on AWS, selecting the right tools is key to building efficient and scalable ETL workflows. The choice depends on business size, data complexity, and the need for real-time or batch processing.
1. Evaluating AWS Glue for data cataloging and ETL
AWS Glue provides a serverless environment for data cataloging, cleaning, and transformation. It integrates well with Amazon S3 and Redshift, supports Spark-based ETL jobs, and includes features like Glue Studio for visual pipeline creation.
For SMBs looking to avoid infrastructure management while keeping costs predictable, AWS Glue is a reliable and scalable option.
2. Considering Amazon Kinesis for real-time data processing
Amazon Kinesis is ideal for SMBs that rely on time-sensitive data from IoT devices, applications, or user interactions. It supports real-time ingestion and processing with low latency, enabling quicker decision-making and automation.
When paired with AWS Lambda or Glue streaming jobs, it supports dynamic ETL workflows without overcomplicating the architecture.
3. Assessing Upsolver for automated data workflows
Upsolver is an AWS-native tool that simplifies ETL and ELT pipelines by automating tasks like job orchestration, schema management, and error handling.
While third-party, it operates within the AWS ecosystem and is often considered by SMBs that want faster deployment times without building custom pipelines. Cloudtech helps evaluate when tools like Upsolver fit into the broader modernization roadmap.
Choosing the right mix of AWS services ensures that ETL workflows are not only efficient but also future-ready. AWS partners like Cloudtech support SMBs in assessing tools based on their use cases, guiding them toward solutions that align with their cost, scale, and performance needs.
How Cloudtech supports SMBs with ETL on AWS
Cloudtech is an advanced cloud modernization and AWS Tier Partner focused on helping SMBs build efficient ETL pipelines and data lakes on AWS. Cloudtech helps with:
- Data modernization: Upgrading data infrastructures for improved performance and analytics, helping businesses unlock more value from their information assets through Amazon Redshift implementation.
- Application modernization: Revamping legacy applications to become cloud-native and scalable, ensuring seamless integration with modern data warehouse architectures.
- Infrastructure and resiliency: Building secure, resilient cloud infrastructures that support business continuity and reduce vulnerability to disruptions through proper Amazon Redshift deployment and optimization.
- Generative artificial intelligence: Implementing AI-driven solutions that leverage Amazon Redshift's analytical capabilities to automate and optimize business processes.
Cloudtech simplifies the path to modern ETL, enabling SMBs to gain real-time insights, meet compliance standards, and grow confidently on AWS.
Conclusion
Cloudtech helps SMBs simplify complex data workflows, making cloud-based ETL accessible, reliable, and scalable.
Building efficient ETL pipelines is crucial for SMBs to utilize a data lake on AWS fully. By adopting AWS-native tools such as AWS Glue, Amazon S3, and Amazon Athena, businesses can simplify data processing while ensuring scalability, security, and cost control. Following best practices in data ingestion, transformation, and governance helps unlock actionable insights and supports better business decisions.
Cloudtech specializes in guiding SMBs through this cloud modernization journey. With expertise in AWS and a focus on SMB requirements, Cloudtech delivers customized ETL solutions that enhance data reliability and operational efficiency.
Partners like Cloudtech help to design and implement scalable, secure ETL pipelines on AWS tailored to your business goals. Reach out today to learn how Cloudtech can help improve your data strategy.
FAQs
1. What is an ETL pipeline?
ETL stands for extract, transform, and load. It is a process that collects data from multiple sources, cleans and organizes it, then loads it into a data repository such as a data lake or data warehouse for analysis.
2. Why are ETL pipelines important for SMBs?
ETL pipelines help SMBs consolidate diverse data sources into one platform, enabling better business insights, streamlined operations, and faster decision-making without managing complex infrastructure.
3. Which AWS services are commonly used for ETL?
Key AWS services include AWS Glue for data cataloging and transformation, Amazon S3 for data storage, Amazon Athena for querying data directly from S3, and Amazon Kinesis for real-time data ingestion.
4. How does Cloudtech help with ETL implementation?
Cloudtech supports SMBs in designing, building, and optimizing ETL pipelines using AWS-native tools. They provide tailored solutions with a focus on security, compliance, and performance, especially for healthcare and regulated industries.
5. Can ETL pipelines handle real-time data processing?
Yes, AWS services like Amazon Kinesis and AWS Glue Streaming support real-time data ingestion and transformation, enabling SMBs to act on data as it is generated.Conclusion

AWS ECS vs AWS EKS: choosing the best for your business
Amazon Elastic Container Service (Amazon ECS) and Amazon Elastic Kubernetes Service (Amazon EKS) simplify how businesses run and scale containerized applications, eliminating the complexity of managing complex infrastructure. Unlike open-source options that demand significant in-house expertise, these managed AWS services automate deployment and security, making them a strong fit for teams focused on speed and growth.
The impact is evident. The global container orchestration market reached $332.7 million in 2018 and is projected to surpass $1382.1 million by 2026, driven largely by businesses adopting cloud-native architectures.
While both services help you deploy, manage, and scale containers, they differ significantly in how they operate, who they’re ideal for, and the level of control they offer.
This guide provides a detailed comparison of Amazon ECS vs EKS, highlighting the technical and operational differences that matter most to businesses ready to modernize their application delivery.
Key Takeaways
- Amazon ECS and Amazon EKS both deliver managed container orchestration, but Amazon ECS focuses on simplicity and deep AWS integration, while Amazon EKS offers portability and advanced Kubernetes features.
- Amazon ECS is a strong fit for businesses seeking rapid deployment, cost control, and minimal operational overhead, while Amazon EKS suits teams with Kubernetes expertise, complex workloads, or hybrid and multi-cloud needs.
- Pricing structures differ: Amazon ECS has no control plane fees, while Amazon EKS charges a management fee per cluster in addition to resource costs.
- Partnering with Cloudtech gives businesses expert support in evaluating, adopting, and optimizing Amazon ECS or Amazon EKS, ensuring the right service is chosen for long-term growth and reliability.
What is Amazon ECS?
Amazon ECS is a fully managed container orchestration service that helps organizations easily deploy, manage, and scale containerized applications. It integrates AWS configuration and operational best practices directly into the platform, eliminating the complexity of managing control planes or infrastructure components.
The service operates through three distinct layers that provide comprehensive container management capabilities:
- Capacity layer: The infrastructure foundation where containers execute, supporting Amazon EC2 instances, AWS Fargate serverless compute, and on-premises deployments through Amazon ECS Anywhere.
- Controller layer: The orchestration engine that deploys and manages applications running within containers, handling scheduling, availability, and resource allocation.
- Provisioning layer: The interface tools that enable interaction with the scheduler for deploying and managing applications and containers.
Key features of Amazon ECS
Amazon Elastic Container Service (ECS) is purpose-built to simplify container orchestration, without overwhelming businesses with infrastructure management.
Whether you're running microservices or batch jobs, Amazon ECS offers impactful features and tightly integrated components that make containerized applications easier to deploy, secure, and scale.
- Serverless integration with AWS Fargate: AWS Fargate is directly integrated into Amazon ECS, removing the need for server management, capacity planning, and manual container workload isolation.
Businesses define their application requirements and select AWS Fargate as the launch type, allowing AWS Fargate to automatically manage scaling and infrastructure. - Autonomous control plane operations: Amazon ECS operates as a fully managed service, with AWS configuration and operational best practices built in.
There is no need for users to manage control planes, nodes, or add-ons, which significantly reduces operational overhead and ensures enterprise-grade reliability. - Security and isolation by design: The service integrates natively with AWS security, identity, and management tools. This enables granular permissions for each container and provides strong isolation for application development. Organizations can deploy containers that meet the security and compliance standards expected from AWS infrastructure.
Key components of Amazon ECS
Amazon ECS relies on a few core components to run containers efficiently. From defining how containers run to keeping your applications available at all times, each plays an important role.
- Task definitions: JSON-formatted blueprints that specify how containers should execute, including resource requirements, networking configurations, and security settings.
- Clusters: The infrastructure foundation where applications operate, providing the computational resources necessary for container execution.
- Tasks: Individual instances of task definitions representing running applications or batch jobs.
- Services: Long-running applications that maintain desired capacity and ensure continuous availability.
Together, these features and components enable businesses to focus on building and deploying applications without being hindered by infrastructure complexity.
Amazon ECS deployment models

Amazon ECS provides businesses with the flexibility to run containers in a manner that aligns with their specific needs and resources. Here are the main deployment models that cover a range of preferences, from fully managed to self-managed environments.
- AWS Fargate Launch Type: A serverless, pay-as-you-go compute engine that enables application focus without server management. AWS Fargate automatically manages capacity needs, operating system updates, compliance requirements, and resiliency.
- Amazon EC2 Launch Type: Organizations choose instance types, manage capacity, and maintain control over the underlying infrastructure. This model suits large workloads requiring price optimization and granular infrastructure control.
- Amazon ECS Anywhere: Provides support for registering external instances, such as on-premises servers or virtual machines, to Amazon ECS clusters. This option enables consistent container management across cloud and on-premises environments.
Each deployment model supports a range of business needs, making it easier to match the service to specific use cases.
How businesses can use Amazon ECS
Amazon ECS supports a wide range of business needs, from updating legacy systems to handling advanced analytics and data processing. These use cases highlight how the service can help businesses address real-world challenges and scale with confidence.
- Application modernization: The service empowers developers to build and deploy applications with improved security features in a fast, standardized, compliant, and cost-efficient manner. Businesses can use this capability to modernize legacy applications without extensive infrastructure investments.
- Automatic web application scaling: Amazon ECS automatically scales and runs web applications across multiple Availability Zones, delivering the performance, scale, reliability, and availability of AWS infrastructure. This capability is particularly beneficial for businesses that experience variable traffic patterns.
- Batch processing support: Organizations can plan, schedule, and run batch computing workloads across AWS services, including Amazon EC2, AWS Fargate, and Amazon EC2 Spot Instances. This flexibility enables cost-effective processing of periodic workloads common in business operations.
- Machine learning model training: Amazon ECS supports training natural language processing and other artificial intelligence and machine learning models without managing infrastructure by using AWS Fargate. Businesses can use this capability to implement data-driven solutions without significant infrastructure investments.
While Amazon ECS offers a seamless way to manage containerized workloads with deep AWS integration, some businesses prefer the flexibility and portability of Kubernetes, especially when operating in hybrid or multi-cloud environments. That’s where Amazon EKS comes in.
What is Amazon EKS?
Amazon Elastic Kubernetes Service (EKS) is a managed Kubernetes service that simplifies running Kubernetes on AWS and on-premises environments. This eliminates the need for organizations to install and operate their own Kubernetes control plane.
Kubernetes serves as an open-source system for automating the deployment, scaling, and management of containerized applications, while Amazon EKS provides the managed infrastructure to support these operations.
The service automatically manages the availability and scalability of Kubernetes control plane nodes, which are responsible for scheduling containers, managing application availability, storing cluster data, and executing other critical tasks. Amazon EKS is certified Kubernetes-conformant, ensuring existing applications running on upstream Kubernetes remain compatible with Amazon EKS.
Key features of Amazon EKS
Amazon EKS combines features that enable businesses to run Kubernetes clusters with reduced manual effort and enhanced security. Here are the key capabilities that make the service practical and reliable for a range of workloads.
- Amazon EKS Auto Mode: This feature fully automates the management of the Kubernetes cluster infrastructure, including compute, storage, and networking. Auto Mode provisions infrastructure, scales resources, optimizes costs, applies patches, manages add-ons, and integrates with AWS security services with minimal user intervention.
- High availability and scalability: The managed control plane is automatically distributed across three Availability Zones for fault tolerance and automatic scaling, ensuring uptime and reliability.
- Security and compliance integration: Amazon EKS integrates with AWS Identity and Access Management, encryption, and network policies to provide fine-grained access control, compliance, and security for workloads.
- Smooth AWS service integration: Native integration with services such as Elastic Load Balancing, Amazon CloudWatch, Amazon Virtual Private Cloud, and Amazon Route 53 for networking, monitoring, and traffic management.
Key Components of Amazon EKS
To support these features, Amazon EKS includes several key components that act as its operational backbone:
- Managed control plane: The managed control plane is the core Kubernetes control plane managed by AWS. It includes the Kubernetes Application Programming Interface server, etcd database, scheduler, and controller manager, and is responsible for cluster orchestration, health monitoring, and high availability across multiple AWS Availability Zones.
- Managed node groups: Managed node groups are Amazon EC2 instances or groups of instances that run Kubernetes worker nodes. AWS manages its lifecycle, updates, and scaling, allowing organizations to focus on workloads rather than infrastructure.
- Amazon EKS add-ons: These are curated sets of Kubernetes operational software (such as CoreDNS and kube-proxy) provided and managed by AWS to extend cluster functionality and ensure smooth integration with AWS services.
- Service integrations (AWS Controllers for Kubernetes): These controllers allow Kubernetes clusters to directly manage AWS resources (such as databases, storage, and networking) from within Kubernetes, enabling cloud-native application patterns.
Together, these capabilities and components make Amazon EKS a practical choice for businesses seeking flexibility, security, and operational simplicity, whether running in the cloud or on-premises.
What deployment options are available for Amazon EKS?
Amazon EKS provides several options for businesses to run their Kubernetes workloads, each with its own unique balance of control and convenience. Here are the primary deployment options that enable organizations to align their resources and goals.
- Amazon EC2 Node Groups: Organizations choose instance types, pricing models (on-demand, spot, reserved), and node counts, providing high control with higher management responsibility.
- AWS Fargate Integration: AWS Fargate eliminates node management but costs scale linearly with pod usage, making it suitable for applications with predictable resource requirements.
- AWS Outposts: Enterprise hybrid model with custom pricing, typically not cost-efficient for small teams but ideal for organizations requiring on-premises Kubernetes capabilities.
- Amazon EKS Anywhere: No AWS charges, but organizations manage everything and lose cloud-native elasticity unless combined with autoscalers.
These deployment choices open up a range of practical use cases for businesses across different industries and technical requirements.
How can businesses use Amazon EKS?

Amazon EKS supports a variety of business needs, from building reliable applications to supporting data science teams. These use cases demonstrate how the service enables organizations to manage complex workloads and remain flexible as requirements evolve.
- High-availability applications deployment: Using Elastic Load Balancing ensures applications remain highly available across multiple Availability Zones. This capability supports mission-critical applications requiring continuous operation.
- Microservices architecture development: Organizations can utilize Kubernetes service discovery features with AWS Cloud Map or Amazon Virtual Private Cloud Lattice to build resilient systems. This approach enables scalable, maintainable application architectures.
- Machine learning workload execution: Amazon EKS supports popular machine learning frameworks such as TensorFlow, MXNet, and PyTorch. With Graphics Processing Unit support, organizations can handle complex machine learning tasks effectively.
- Hybrid and multi-cloud deployments: The service enables consistent operation on-premises and in the cloud using Amazon EKS clusters, features, and tools to run self-managed nodes on AWS Outposts or Amazon EKS Hybrid Nodes.
Comparing these Amazon services helps businesses identify where each service excels and what sets them apart. Choosing between the two depends on your team's expertise, application needs, and the level of control you want over your orchestration layer.
Key differences between Amazon ECS and Amazon EKS
Amazon ECS is a fully managed, AWS-native service that’s simpler to set up and use. On the other hand, Amazon EKS is built on Kubernetes, offering more flexibility and portability for teams already invested in the Kubernetes ecosystem.
When comparing Amazon ECS and Amazon EKS, several key differences emerge in how they handle orchestration, integration, and day-to-day management.
The core differences between Amazon ECS and Amazon EKS enable businesses to make informed decisions based on their technical capabilities, resource needs, and long-term objectives. However, to choose the right fit, it's just as important to consider practical use cases.
When to choose AWS ECS or AWS EKS?
Selecting the right container service depends on your team’s expertise, workload complexity, and operational priorities. Below are common business scenarios to help you determine whether Amazon ECS or Amazon EKS is the better fit for your application needs.
Choose Amazon ECS when:
Some situations require a service that keeps things straightforward and allows teams to move quickly. These points highlight when Amazon ECS is the right match for business needs.
- Operational simplicity is the priority: Amazon ECS excels when organizations prioritize powerful simplicity and prefer an AWS-opinionated solution. The service is ideal for teams new to containers or those seeking rapid deployment without complex configuration requirements.
- Deep AWS integration is required: Organizations fully committed to the AWS ecosystem benefit from smooth integration with AWS services, including AWS Identity and Access Management, Amazon CloudWatch, and Amazon Virtual Private Cloud. This integration accelerates development and reduces operational complexity.
- Cost optimization is essential: Amazon ECS can be more cost-effective, especially for smaller workloads, as it eliminates control plane charges. Businesses benefit from pay-as-you-go pricing across multiple AWS compute options.
- Quick time-to-market is critical: Amazon ECS reduces the time required to build, deploy, or migrate containerized applications successfully. The service enables organizations to focus on application development rather than infrastructure management.
Choose Amazon EKS when:
Some businesses require more flexibility, advanced features, or the ability to run workloads across multiple environments. These points show when Amazon EKS is the better choice.
- Kubernetes expertise is available: Organizations with existing Kubernetes knowledge can use the extensive Kubernetes ecosystem and community. Amazon EKS enables the utilization of existing plugins and tooling from the Kubernetes community.
- Portability requirements are crucial: Amazon EKS offers vendor portability, preventing vendor lock-in and enabling workload operation across multiple cloud providers. Applications remain fully compatible with any standard Kubernetes environment.
- Complex workloads require advanced features: Applications requiring advanced Kubernetes features like custom resource definitions, operators, or advanced networking configurations benefit from Amazon EKS. The service supports complex microservices architectures and machine learning workloads.
- Hybrid deployments are necessary: Organizations needing consistent container operation across on-premises and cloud environments can utilize Amazon EKS. The service supports AWS Outposts and Amazon EKS Hybrid Nodes for comprehensive hybrid strategies.
Choosing between Amazon ECS and Amazon EKS can be challenging, particularly when considering the balance of cost, complexity, and future scalability. That’s where partners like Cloudtech step in.
How Cloudtech supports businesses comparing Amazon ECS vs EKS
Cloudtech is an advanced AWS partner that helps businesses evaluate their current infrastructure, technical expertise, and long-term goals to make the right choice between Amazon ECS and Amazon EKS, and support them every step of the way.
With a team of AWS-certified experts, Cloudtech offers end-to-end cloud transformation services, from crafting customized AWS adoption strategies to modernizing applications with Amazon ECS and Amazon EKS.
By partnering with Cloudtech, businesses can confidently compare Amazon ECS vs. EKS, select the right service for their needs, and receive expert assistance every step of the way, from planning to ongoing optimization.
Conclusion
Selecting between Amazon ECS and Amazon EKS comes down to the specific needs, technical skills, and growth plans of each business. Both services offer managed container orchestration, but the right fit depends on factors such as operational preferences, integration requirements, and team familiarity with container technologies.
For SMBs, this choice has a direct impact on deployment speed, ongoing management, and the ability to scale applications with confidence.
For businesses seeking to maximize their investment in AWS, collaborating with an experienced consulting partner like Cloudtech can clarify the Amazon ECS vs. EKS decision and streamline the path to modern application delivery. Get started with us!
FAQs
- Can AWS ECS and EKS run workloads on the same cluster?
No, ECS and EKS are separate orchestration platforms and do not share clusters. Each manages its own resources, so workloads must be deployed to either an ECS or EKS cluster, not both.
- How do ECS and EKS handle IAM permissions differently?
ECS uses AWS IAM roles for tasks and services, making it straightforward to assign permissions directly to containers. EKS, built on Kubernetes, integrates with IAM using Kubernetes service accounts and the AWS IAM Authenticator, which can require extra configuration for fine-grained access.
- Is there a difference in how ECS and EKS support hybrid or on-premises workloads?
ECS Anywhere and EKS Anywhere both extend AWS container management to on-premises environments, but EKS Anywhere offers a Kubernetes-native experience, while ECS Anywhere is focused on ECS APIs and workflows.
- Which service offers simpler integration with AWS Fargate for serverless containers?
Both ECS and EKS support AWS Fargate, but ECS typically offers a more direct and streamlined setup for running serverless containers, with fewer configuration steps compared to EKS.
- How do ECS and EKS differ in their support for multi-region deployments?
ECS provides multi-region support through its own APIs and service discovery, while EKS relies on Kubernetes-native tools and add-ons for cross-region communication, which may require extra setup and management.

An easy guide to AWS Lambda limits and quotas in 2025
Businesses are increasingly adopting AWS Lambda to automate processes, reduce operational overhead, and respond to changing customer demands. As businesses build and scale their applications, they are likely to encounter specific AWS Lambda limits related to compute, storage, concurrency, and networking.
Each of these limits plays a role in shaping function design, performance, and cost. For businesses, including small and medium-sized businesses (SMBs), understanding where these boundaries lie is important for maintaining application reliability. Knowing how to operate within them helps control expenses effectively.
This guide will cover the most relevant AWS Lambda limits for businesses and provide practical strategies for monitoring and managing them effectively.
Key Takeaways:
- AWS Lambda limits on memory, execution time, concurrency, and storage shape function performance, reliability, and cost for SMB workloads.
- SMBs can monitor Lambda usage effectively using CloudWatch, Service Quotas, and AWS X-Ray to prevent throttling and control costs efficiently.
- Reserved and provisioned concurrency ensures critical functions scale predictably, avoid throttling, and deliver consistent performance for SMB apps.
- AWS Lambda layers, container images, and /tmp storage management let SMBs optimize deployment size, temporary data, and function efficiency effectively.
- Cloudtech helps SMBs modernize data with AWS Lambda while respecting limits, enabling scalable, compliant, and AI-ready serverless architectures.
What are AWS Lambda limits, and what is their relevance for SMBs?
AWS Lambda operates within a set of predefined limits, also known as quotas, to ensure the service remains reliable, secure, and cost-efficient for all users. These limits help maintain fair resource allocation and prevent individual workloads from unintentionally affecting system performance.
They fall into two main categories:
- Hard limits are fixed and cannot be changed.
- Soft limits (quotas), which can be increased through AWS Support requests.
The key AWS Lambda limits include:
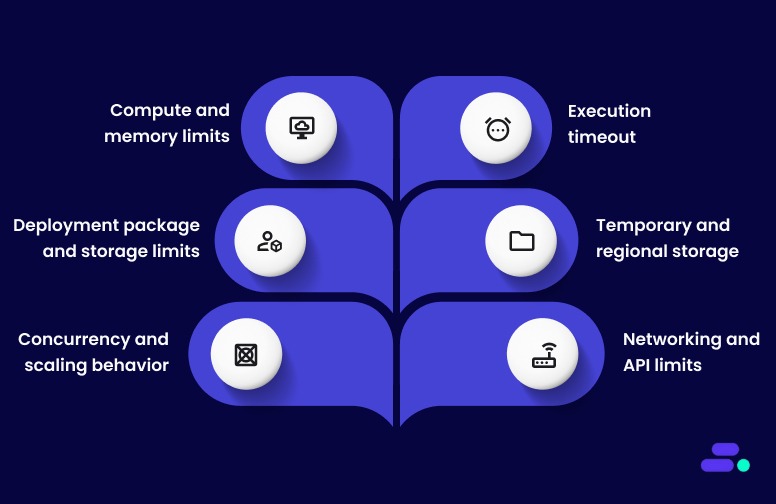
1. Compute and memory limits: AWS Lambda functions can allocate between 128 MB and 10,240 MB of memory, with CPU power scaling proportionally to the selected memory. This means increasing memory can improve CPU performance and reduce execution time, which is an important optimization lever for SMBs running compute-intensive or time-sensitive tasks.
2. Execution timeout: Each Lambda function has a maximum execution time of 15 minutes (900 seconds) per invocation. Workloads requiring longer processing should use AWS Step Functions to coordinate multiple shorter Lambda runs, a best practice for maintaining modular and fault-tolerant architectures.
3. Deployment package and storage limits:
- 50 MB (zipped) for direct uploads via the AWS Console or API.
- 250 MB (unzipped), including all dependencies, layers, and custom runtimes.
- 10 GB maximum uncompressed size for container images hosted in Amazon ECR.
SMBs can use layers or container packaging to manage dependencies efficiently and streamline deployment.
4. Temporary and regional storage: Each Lambda execution environment provides 512 MB of temporary storage in the /tmp directory by default, configurable up to 10 GB. This local storage is ideal for intermediate data processing or caching, while long-term storage should use Amazon S3 or Amazon EFS.
Across all Lambda functions in a region, AWS provides 75 GB of total code storage, which can be increased upon request.
5. Concurrency and scaling behavior: By default, each AWS account has 1,000 concurrent executions per region, shared across all functions. This limit can be increased to accommodate higher traffic.
Lambda also scales at a rate of 1,000 instances every 10 seconds per function, allowing smooth scaling during traffic spikes. SMBs can use:
- Reserved concurrency to guarantee capacity for critical workloads.
- Provisioned concurrency for consistent, low-latency performance in customer-facing applications.
6. Networking and API limits: For functions running inside a VPC, Lambda creates Elastic Network Interfaces (ENIs), subject to a default quota of 500 per VPC.
Control plane API requests are limited (e.g., 100 GetFunction requests per second), ensuring predictable management-plane performance.
Why do these limits matter for SMBs?
For small and medium-sized businesses, understanding AWS Lambda limits is essential for cost control, scalability, and reliability.
Here’s why managing AWS Lambda limits is essential:
- Cost efficiency: Memory and concurrency tuning can directly affect execution time and AWS billing.
- Performance consistency: Proper concurrency configuration avoids throttling and ensures critical workloads remain responsive.
- Resilience and scalability: Designing within Lambda’s scaling behavior helps SMBs handle unpredictable workloads without overprovisioning infrastructure.
- Security and governance: Network limits and code storage quotas help enforce best practices for secure, maintainable deployments.
By aligning function design and scaling strategies with AWS Lambda’s defined limits, SMBs can achieve a balance of agility, control, and operational efficiency, which are key to maximizing the value of serverless computing on AWS.

How can SMBs monitor AWS Lambda limitations?
Monitoring AWS Lambda limits is critical for maintaining visibility into function behavior, preventing performance degradation, and ensuring cost efficiency. SMBs that actively track usage patterns can identify potential bottlenecks early and scale more effectively as workloads grow.
Here’s how to monitor AWS Lambda limites:
1. Use the AWS Service Quotas dashboard: The AWS Service Quotas dashboard provides a centralized view of current limits and usage across all AWS services. Businesses can:
- View default quotas and any custom increases requested.
- Identify when usage approaches key thresholds.
- Plan ahead for traffic growth or seasonal peaks before reaching hard limits.
Tip: Schedule regular reviews of AWS Lambda quotas, especially concurrency and storage usage, to avoid unexpected throttling.
2. Monitor AWS Lambda metrics with Amazon CloudWatch
Amazon CloudWatch automatically captures operational metrics for all Lambda functions, allowing teams to track performance, detect anomalies, and respond proactively. Key metrics to monitor include:
- ConcurrentExecutions: Shows the number of functions running simultaneously.
- Throttles: Alerts businesses when functions are blocked due to concurrency limits.
- Errors and DLQ Errors: Identify and troubleshoot failed executions.
- Duration: Measures how long functions run, useful for optimizing cost and performance.
Best practice: Combine CloudWatch alarms with Amazon SNS notifications to get real-time alerts when thresholds are crossed.
3. Analyze performance with AWS X-Ray: For deeper visibility, AWS X-Ray helps trace function execution paths, visualize dependencies, and pinpoint latency sources. It helps businesses:
- Identify inefficient code paths or slow API calls.
- Monitor cold start occurrences and their impact on latency.
- Optimize function performance to stay within timeout limits.
In short, effective monitoring transforms AWS Lambda from a reactive compute service into a predictable, performance-driven platform for modern business applications.
Also Read: AWS cost optimization strategies and best practices

How can SMBs manage AWS Lambda limitations?
Once AWS Lambda limits are understood and monitored, the next step is to manage them strategically to ensure smooth scaling, predictable costs, and consistent performance. For SMBs, this means taking a proactive approach to concurrency control, deployment optimization, and workflow design.

The key areas of AWS Lambda limit management include controlling concurrency, optimizing package and storage usage, managing temporary data, and designing workflows that stay within execution time boundaries:
1. Manage concurrency for performance and reliability
Concurrency defines how many function instances can run at once. Managing it effectively ensures consistent performance and prevents throttling across workloads.
Reserved concurrency: Guarantees execution capacity for critical functions and isolates them from shared pool limits.
Use reserved concurrency for:
- Always-on or mission-critical workloads
- Functions interacting with limited downstream services (e.g., databases)
- High-priority systems that must remain unaffected by traffic surges
Provisioned concurrency: Pre-warms Lambda instances to eliminate cold starts and deliver low-latency responses.
It is ideal for:
- Web and mobile backends
- Customer-facing APIs
- Real-time or interactive features
Requesting limit increases: If businesses expect usage growth, request concurrency or quota increases through the AWS Service Quotas console.
Include details such as:
- Expected peak loads (e.g., marketing campaigns or seasonal events)
- Forecasted growth rates
- Limitations of integrated systems (e.g., database throughput)
2. Handle deployment package and storage limits
Efficiently managing deployment package size and storage constraints is critical to ensuring reliable Lambda deployments and maintaining smooth CI/CD pipelines. Oversized packages can slow down cold starts, increase deployment times, and lead to failed uploads during automation workflows.
SMBs can address these issues by modularizing their code, leveraging AWS-native tools, and separating reusable dependencies into managed layers or container images.
Use AWS Lambda layers: AWS Lambda layers allow teams to share common code, SDKs, or libraries across multiple functions, reducing redundancy and simplifying updates. Instead of bundling the same dependencies in every function, developers can centralize them into versioned layers:
- Smaller deployment packages
- Easier version management
- Improved maintainability
Limit: Each Lambda function can include up to five layers, and the total unzipped deployment package (function code + layers) must not exceed 250 MB. Additionally, the zipped upload directly through the AWS Management Console is limited to 50 MB, or 250 MB via Amazon S3.
Use Amazon ECR for larger deployments: For more complex workloads, custom runtimes, or larger dependencies, container image packaging offers greater flexibility.
By hosting function images in Amazon Elastic Container Registry (ECR), SMBs can use the same tools and pipelines already familiar from containerized applications.
Key advantages include:
- Package and deploy container images up to 10 GB in size
- Support any programming language or framework, including custom runtimes
- Simplify dependency management using Dockerfiles and version tags
- Enable automated vulnerability scanning and security compliance via Amazon ECR integration
Container-based Lambda deployments are especially useful for teams standardizing on containerized workflows or integrating Lambda into hybrid architectures.
3. Manage temporary storage (/tmp)
Each AWS Lambda execution environment provides 512 MB of ephemeral storage in the /tmp directory by default. This space can be increased up to 10 GB per function, allowing more flexibility for workloads that require intermediate data processing or file manipulation. However, since /tmp storage is ephemeral (deleted after the function instance is recycled), it should be used carefully and efficiently.
Best practices for SMBs:
- Clean up temporary files before the function exits to free up space for subsequent invocations and avoid unexpected failures.
- Stream data instead of writing large files locally. For example, use Amazon S3 or Amazon Kinesis for data transfer and buffering instead of a local disk.
- Monitor ephemeral storage metrics through Amazon CloudWatch, tracking MaxStorageUsed to prevent space exhaustion.
- Request expanded storage via the Lambda configuration (up to 10 GB) for workloads such as file conversions, data transformations, or batch processing that temporarily handle large datasets.
- Avoid using /tmp for persistence. Data stored here is not retained across concurrent executions or after the environment is recycled.
4. Optimize execution time and memory allocation
AWS Lambda functions can run for a maximum of 15 minutes (900 seconds), with memory settings configurable from 128 MB to 10,240 MB (10 GB). These two parameters, execution duration and memory allocation, are closely linked and play a major role in both cost efficiency and performance optimization.
For SMBs, balancing them effectively can reduce costs while improving responsiveness and reliability in production environments.
Optimize for performance and cost: Performance tuning begins with understanding how each function behaves under load. AWS provides multiple observability tools to help identify bottlenecks and inefficiencies.
Key recommendations:
- Profile function performance with AWS X-Ray and CloudWatch Logs: Use tracing and log metrics to measure latency, cold start impact, and downstream call durations.
- Right-size memory allocations: Increasing memory also proportionally increases CPU, network bandwidth, and ephemeral storage, which often reduces execution time enough to offset higher per-millisecond costs.
- Remove unused dependencies: Smaller deployment packages lead to faster cold starts, especially for high-frequency or on-demand workloads.
- Use connection pooling and re-use SDK clients: Keep persistent connections (e.g., database or API clients) initialized outside the function handler to minimize repeated connection overhead.
- Leverage AWS Compute Optimizer: Get automated recommendations for optimal memory configurations based on historical performance data.
These optimizations ensure that the Lambda functions are both cost-effective and scalable under varying workloads, without hitting timeout or concurrency bottlenecks.
Break complex workloads into smaller steps: Some workloads naturally exceed the Lambda execution limit or involve multiple dependent operations. In these cases, AWS Step Functions offers a managed way to coordinate and chain multiple Lambda functions or even integrate with other AWS services (e.g., ECS, DynamoDB, SageMaker).
Benefits of this approach:
- Sequential or parallel orchestration: Execute functions in a defined sequence or run them concurrently for faster processing.
- Built-in retries and error handling: Automatically retry failed steps and capture errors for easier debugging.
- State management: Maintain data and progress across steps without custom logic.
- Simplified workflow design: Visualize complex logic as a state machine, improving clarity and reducing code complexity.
This pattern is ideal for data processing pipelines, file transformations, multi-step approvals, or ML inference workflows, where each step can be handled independently but still contributes to a unified outcome.
By treating limits as design parameters, and not constraints, organizations can unlock the full flexibility of AWS Lambda while maintaining control, performance, and operational confidence.
Also Read: Common security pitfalls during cloud migration, and how to avoid them

How Cloudtech helps SMBs manage AWS Lambda limits and modernize data?
Understanding and managing AWS Lambda limits is essential for small and medium-sized businesses (SMBs) looking to modernize data environments efficiently. Cloudtech helps organizations navigate AWS Lambda quotas, optimize serverless architectures, and build scalable, compliant data systems using AWS best practices.
Cloudtech services that support data modernization:
- Application modernization: Cloudtech transforms legacy applications into event-driven, serverless architectures powered by AWS Lambda. It helps SMBs achieve better scalability, reduced cold starts, and predictable performance without exceeding service quotas.
- Data modernization: Cloudtech creates end-to-end, Lambda-based data pipelines using Amazon S3, AWS Glue, and Amazon Redshift. Their approach ensures data ingestion, processing, and analytics workflows stay within Lambda’s execution, storage, and temporary storage limits.
- Infrastructure and resiliency: Cloudtech strengthens AWS environments with secure, highly available architectures, including automated backups, multi-AZ replication, and disaster recovery. This ensures Lambda workloads can scale safely while remaining compliant with system limits.
- Generative AI solutions: Cloudtech prepares data for generative AI applications using AWS Lambda and Amazon Q Business. SMBs can harness AI-driven insights without breaching compute or concurrency limits.
With Cloudtech’s AWS-certified expertise, SMBs can confidently modernize data environments while respecting Lambda quotas. The services ensure functions scale efficiently, workloads remain compliant, and every modernization initiative unlocks real-time insights, AI readiness, and sustainable cloud growth.
See how other SMBs have modernized, scaled, and thrived with Cloudtech’s support →
Conclusion
With a clear view of AWS Lambda limits and actionable strategies for managing them, SMBs can approach serverless development with greater confidence. Readers now have practical guidance for balancing performance, cost, and reliability, whether it is tuning memory and concurrency, handling deployment package size, or planning for network connections. These insights help teams make informed decisions about function design and operations, reducing surprises as workloads grow.
For SMBs seeking expert support, Cloudtech offers data modernization services built around Amazon Web Services' best practices.
Cloudtech’s AWS-certified architects work directly with clients to streamline data pipelines, strengthen compliance, and build scalable solutions using AWS Lambda and the broader AWS portfolio. Get started now!
FAQs
1. What is the maximum payload size for AWS Lambda invocations?
For synchronous invocations, the maximum payload size is 6 megabytes. Exceeding this limit will result in invocation failures, so large event data must be stored elsewhere, such as in Amazon S3, with only references passed to the function.
2. Are there limits on environment variables for AWS Lambda functions?
Each Lambda function can store up to 4 kilobytes of environment variables. This limit includes all key-value pairs and can impact how much configuration or sensitive data is embedded directly in the function’s environment.
3. How does AWS Lambda handle sudden traffic spikes in concurrency?
Lambda supports burst concurrency, allowing up to 500 additional concurrent executions every 10 seconds per function, or 5,000 requests per second every 10 seconds, whichever is reached first. This scaling behavior is critical for applications that experience unpredictable load surges.
4. Is there a limit on ephemeral storage (/tmp) for AWS Lambda functions?
By default, each Lambda execution environment provides 512 megabytes of ephemeral storage in the /tmp directory, which can be increased up to 10 gigabytes if needed. This storage is shared across all invocations on the same environment and is reset between container reuses.
5. Are there restrictions on the programming languages supported by AWS Lambda?
Lambda natively supports a set of languages (such as Python, Node.js, Java, and Go), but does not support every language out of the box. Using custom runtimes or container images can extend language support, but this comes with additional deployment and management considerations.

Amazon Redshift: a comprehensive guide
From sales transactions to operational logs, businesses now handle millions of data points daily. Yet when it’s time to pull insights, most find their traditional databases too slow, rigid, or costly for complex analytics.
Without scalable infrastructure, even basic reporting turns into a bottleneck. SMBs often operate with lean teams, limited budgets, and rising compliance demands, leaving little room for overengineered systems or extended deployment cycles.
Amazon Redshift from AWS changes that. As a fully managed cloud data warehouse, it enables businesses to query large volumes of structured and semi-structured data quickly without the need to build or maintain underlying infrastructure. Its decoupled architecture, automated tuning, and built-in security make it ideal for SMBs looking to modernize fast.
This guide breaks down how Amazon Redshift works, how it scales, and why it’s become a go-to analytics engine for SMBs that want enterprise-grade performance without the complexity.
Key Takeaways
- End-to-end analytics without infrastructure burden: Amazon Redshift eliminates the need for manual cluster management and scales computing and storage independently, making it ideal for growing teams with limited technical overhead.
- Built-in cost efficiency: With serverless billing, reserved pricing, and automatic concurrency scaling, Amazon Redshift enables businesses to control costs without compromising performance.
- Security built for compliance-heavy industries: Data encryption, IAM-based access control, private VPC deployment, and audit logging provide the safeguards required for finance, healthcare, and other regulated environments.
- AWS ecosystem support: Amazon Redshift integrates with Amazon S3, Kinesis, Glue, and other AWS services, making it easier to build real-time or batch data pipelines without requiring additional infrastructure layers.
- Faster rollout with Cloudtech: Cloudtech’s AWS-certified experts help SMBs deploy Amazon Redshift with confidence, handling everything from setup and tuning to long-term optimization and support.
What is Amazon Redshift?
Amazon Redshift is built to support analytical workloads that demand high concurrency, low-latency queries, and scalable performance. It processes both structured and semi-structured data using a columnar storage engine and a massively parallel processing (MPP) architecture, making it ideal for businesses, especially SMBs, that handle fast-growing datasets.
It separates compute and storage layers, allowing organizations to scale each independently based on workload requirements and cost efficiency. This decoupled design supports a range of analytics, from ad hoc dashboards to complex modeling, without burdening teams with the maintenance of infrastructure.
Core capabilities and features of Amazon Redshift

Amazon Redshift combines a high-performance architecture with intelligent automation to support complex analytics at scale, without the burden of manual infrastructure management. From optimized storage to advanced query handling, it equips SMBs with tools to turn growing datasets into business insights.
1. Optimized architecture for analytics
Amazon Redshift stores data in a columnar format, minimizing I/O and reducing disk usage through compression algorithms like LZO, ZSTD, and AZ64. Its Massively Parallel Processing (MPP) engine distributes workloads across compute nodes, enabling horizontal scalability for large datasets. The SQL-based interface supports PostgreSQL-compatible JDBC and ODBC drivers, making it easy to integrate with existing BI tools.
2. Machine learning–driven performance
The service continuously monitors historical query patterns to optimize execution plans. It automatically adjusts distribution keys, sort keys, and compression settings—eliminating the need for manual tuning. Result caching, intelligent join strategies, and materialized views further improve query speed.
3. Serverless advantages for dynamic workloads
Amazon Redshift Serverless provisions and scales compute automatically based on workload demand. With no clusters to manage, businesses benefit from zero administration, fast start-up via Amazon Redshift Query Editor v2, and cost efficiency through pay-per-use pricing and automatic pause/resume functionality.
4. Advanced query capabilities across sources
Amazon Redshift supports federated queries to join live data from services like Amazon Aurora, RDS, and DynamoDB—without moving data. Amazon Redshift Spectrum extends this with the ability to query exabytes of data in Amazon S3 using standard SQL, reducing cluster load. Cross-database queries simplify analysis across schemas, and materialized views ensure fast response for repeated metrics.
5. Performance at scale
To maintain responsiveness under load, Amazon Redshift includes concurrency scaling, which provisions temporary clusters when query queues spike. Workload management assigns priorities and resource limits to users and applications, ensuring a fair distribution of resources. Built-in optimization engines maintain consistent performance as usage increases.
Amazon Redshift setup and deployment process
Successfully deploying Amazon Redshift begins with careful preparation of AWS infrastructure and security settings. These foundational steps ensure that the data warehouse operates securely, performs reliably, and integrates well with existing environments.
The process involves configuring identity and access management, network architecture, selecting the appropriate deployment model, and completing critical post-deployment tasks.
1. Security and network prerequisites for Amazon Redshift deployment
Before provisioning clusters or serverless workgroups, organizations must establish the proper security and networking foundation. This involves setting permissions, preparing network isolation, and defining security controls necessary for protected and compliant operations.
- IAM configuration: Assign IAM roles with sufficient permissions to manage Amazon Redshift resources. The Amazon Redshift Full Access policy covers cluster creation, database admin, and snapshots. For granular control, use custom IAM policies with resource-based conditions to restrict access by cluster, database, or action.
- VPC network setup: Deploy Amazon Redshift clusters within dedicated subnets in a VPC spanning multiple Availability Zones (AZs) for high availability. Attach security groups that enforce strict inbound/outbound rules to control communication and isolate the environment.
- Security controls: Limit access to Amazon Redshift clusters through network-level restrictions. Inbound traffic on port 5439 (default) must be explicitly allowed only from trusted IPs or CIDR blocks. Outbound rules should permit necessary connections to client apps and related AWS services.
2. Deployment models in Amazon Redshift
Once the security and network prerequisites are in place, organizations can select the deployment model that best suits their operational needs and workload patterns. Amazon Redshift provides two flexible options that differ in management responsibility and scalability:
- Amazon Redshift Serverless: It eliminates infrastructure management by auto-scaling compute based on query demand. Capacity, measured in Amazon Redshift Processing Units (RPUs), adjusts dynamically within configured limits, helping organizations balance performance and cost.
- Provisioned clusters: Designed for predictable workloads, provisioned clusters offer full control over infrastructure. A leader node manages queries, while compute nodes process data in parallel. With RA3 node types, compute and storage scale independently for greater efficiency.
3. Initial configuration tasks for Amazon Redshift
After selecting a deployment model and provisioning resources, several critical configuration steps must be completed to secure, organize, and optimize the Amazon Redshift environment for production use.
- Database setup: Each Amazon Redshift database includes schemas that group tables, views, and other objects. A default PUBLIC schema is provided, but up to 9,900 custom schemas can be created per database. Access is controlled using SQL to manage users, groups, and privileges at the schema and table levels.
- Network security: Updated security group rules take effect immediately. Inbound and outbound traffic permissions must support secure communication with authorized clients and integrated AWS services.
- Backup configuration: Amazon Redshift captures automated, incremental backups with configurable retention from 1 to 35 days. Manual snapshots support point-in-time recovery before schema changes or key events. Cross-region snapshot copying enables disaster recovery by replicating backups across AWS regions.
- Parameter management: Cluster parameter groups define settings such as query timeouts, memory use, and connection limits. Custom groups help fine-tune behavior for specific workloads without impacting other Amazon Redshift clusters in the account.
With the foundational setup, deployment model, and initial configuration complete, the focus shifts to how Amazon Redshift is managed in production, enabling efficient scaling, automation, and deeper enterprise integration.
Post-deployment operations and scalability in Amazon Redshift
Amazon Redshift offers flexible deployment options through both graphical interfaces and programmatic tools. Organizations can choose between serverless and provisioned cluster management based on the predictability of their workloads and resource requirements. The service provides comprehensive management capabilities that automate routine operations while maintaining control over critical configuration parameters.
1. Provision of resources and management functionalities
Getting started with Amazon Redshift involves selecting the right provisioning approach. The service supports a range of deployment methods to align with organizational preferences, from point-and-click tools to fully automated DevOps pipelines.
- AWS Management Console: The graphical interface provides step-by-step cluster provisioning with configuration wizards for network settings, security groups, and backup preferences. Organizations can launch clusters within minutes using pre-configured templates for everyday use cases.
- Infrastructure as Code: AWS CloudFormation and Terraform enable automated deployment across environments. Templates define cluster specs, security, and networking to ensure consistent, repeatable setups..
- AWS Command Line Interface: Programmatic cluster management through CLI commands supports automation workflows and integration with existing DevOps pipelines. It offers complete control over cluster lifecycle operations, including creation, modification, and deletion.
- Amazon Redshift API: Direct API access allows integration with enterprise systems for custom automation workflows. RESTful endpoints enable organizations to embed Amazon Redshift provisioning into broader infrastructure management platforms.
2. Dynamic scaling capabilities for Amazon Redshift workloads
Once deployed, Amazon Redshift adapts to dynamic workloads using several built-in scaling mechanisms. These capabilities help maintain query performance under heavy loads and reduce costs during periods of low activity.
- Concurrency Scaling: Automatically provisions additional compute clusters when query queues exceed thresholds. These temporary clusters process queued queries independently, preventing performance degradation during spikes.
- Elastic Resize: Enables fast adjustment of cluster node count to match changing capacity needs. Organizations can scale up or down within minutes without affecting data integrity or system availability.
- Pause and Resume: Provisioned clusters can be suspended during idle periods to save on computing charges. The cluster configuration and data remain intact and are restored immediately upon resumption.
- Scheduled Scaling: Businesses can define policies to scale resources in anticipation of known usage patterns, allowing for more efficient resource allocation. This approach supports cost control and ensures performance during recurring demand cycles.
3. Unified analytics with Amazon Redshift
Beyond deployment and scaling, Amazon Redshift acts as a foundational analytics layer that unifies data across systems and business functions. It is frequently used as a core component of modern data platforms.
- Enterprise data integration: Organizations use Amazon Redshift to consolidate data from CRM, ERP, and third-party systems. This centralization breaks down silos and supports organization-wide analytics and reporting.
- Multi-cluster environments: Teams can deploy separate clusters for different departments or applications, allowing for greater flexibility and scalability. This enables workload isolation while allowing for shared insights when needed through cross-cluster queries.
- Hybrid storage models: By combining Amazon Redshift with Amazon S3, organizations optimize both performance and cost. Active datasets remain in cluster storage, while historical or infrequently accessed data is stored in cost-efficient S3 data lakes.
After establishing scalable operations and integrated data workflows, organizations must ensure that these environments remain secure, compliant, and well-controlled, especially when handling sensitive or regulated data.
Security and connectivity features in Amazon Redshift

Amazon Redshift enforces strong security measures to protect sensitive data while enabling controlled access across users, applications, and networks. Security implementation encompasses data protection, access controls, and network isolation, all of which are crucial for organizations operating in regulated industries, such as finance and healthcare. Connectivity is supported through secure, standards-based drivers and APIs that integrate with internal tools and services.
1. Data security measures using IAM and VPC
Amazon Redshift integrates with AWS Identity and Access Management (IAM) and Amazon Virtual Private Cloud (VPC) to provide fine-grained access controls and private network configurations.
- IAM integration: IAM policies allow administrators to define permissions for cluster management, database operations, and administrative tasks. Role-based access ensures that users and services access only the data and functions for which they are authorized.
- Database-level security: Role-based access at the table and column levels allows organizations to enforce granular control over sensitive datasets. Users can be grouped by function, with each group assigned specific permissions.
- VPC isolation: Clusters are deployed within private subnets, ensuring network isolation from the public internet. Custom security groups define which IP addresses or services can communicate with the cluster.
- Multi-factor authentication: To enhance administrative security, Amazon Redshift supports multi-factor authentication through AWS IAM, requiring additional verification for access to critical operations.
2. Encryption for data at rest and in transit
Amazon Redshift applies end-to-end encryption to protect data throughout its lifecycle.
- Encryption at rest: All data, including backups and snapshots, is encrypted using AES-256 via AWS Key Management Service (KMS). Organizations can use either AWS-managed or customer-managed keys for encryption and key lifecycle management.
- Encryption in transit: TLS 1.2 secures data in motion between clients and Amazon Redshift clusters. SSL certificates are used to authenticate clusters and ensure encrypted communication channels.
- Certificate validation: SSL certificates also protect against spoofed endpoints by validating cluster identity, which is essential when connecting through external applications or secure tunnels.
3. Secure connectivity options for Amazon Redshift access
Amazon Redshift offers multiple options for secure access across application environments and user workflows.
- JDBC and ODBC drivers: Amazon Redshift supports industry-standard drivers that include encryption, connection pooling, and compatibility with a wide range of internal applications and SQL-based tools.
- Amazon Redshift Data API: This HTTP-based API allows developers to run SQL queries without maintaining persistent database connections. IAM-based authentication ensures secure, programmatic access for automated workflows.
- Query Editor v2: A browser-based interface that allows secure SQL query execution without needing to install client drivers. It supports role-based access and session-level security settings to maintain administrative control.
Integration and data access in Amazon Redshift
Amazon Redshift offers flexible integration options designed for small and mid-sized businesses that require efficient and scalable access to both internal and external data sources. From real-time pipelines to automated reporting, the platform streamlines how teams connect, load, and work with data, eliminating the need for complex infrastructure or manual overhead.
1. Simplified access through Amazon Redshift-native tools
For growing teams that need to analyze data quickly without relying on a heavy setup, Amazon Redshift includes direct access methods that reduce configuration time.
- Amazon Redshift Query Editor v2: A browser-based interface that allows teams to run SQL queries, visualize results, and share findings, all without installing drivers or maintaining persistent connections.
- Amazon Redshift Data API: Enables secure, HTTP-based query execution in serverless environments. Developers can trigger SQL operations directly from applications or scripts using IAM-based authentication, which is ideal for automation.
- Standardized driver support: Amazon Redshift supports JDBC and ODBC drivers for internal tools and legacy systems, providing broad compatibility for teams using custom reporting or dashboard solutions.
2. Streamlined data pipelines from AWS services
Amazon Redshift integrates with core AWS services, enabling SMBs to manage both batch and real-time data without requiring extensive infrastructure.
- Amazon S3 with Amazon Redshift Spectrum: Enables high-throughput ingestion from S3 and allows teams to query data in place, avoiding unnecessary transfers or duplications.
- AWS Glue: Provides visual tools for setting up extract-transform-load (ETL) workflows, reducing the need for custom scripts. Glue Data Catalog centralizes metadata, making it easier to manage large datasets.
- Amazon Kinesis: Supports the real-time ingestion of streaming data for use cases such as application telemetry, customer activity tracking, and operational metrics.
- AWS Database Migration Service: Facilitates low-downtime migration from existing systems to Amazon Redshift. Supports ongoing replication to keep cloud data current without disrupting operations.
3. Built-in support for automated reporting and dashboards
Amazon Redshift supports organizations that want fast, accessible insights without investing in separate analytics platforms.
- Scheduled reporting: Teams can automate recurring queries and export schedules to keep stakeholders updated without manual intervention.
- Self-service access: Amazon Redshift tools support role-based access, allowing non-technical users to run safe, scoped queries within approved datasets.
- Mobile-ready dashboards: Reports and result views are accessible on tablets and phones, helping teams track KPIs and metrics on the go.
Cost and operational factors in Amazon Redshift
For SMBs, cost efficiency and operational control are central to maintaining a scalable data infrastructure. Amazon Redshift offers a flexible pricing model, automatic performance tuning, and predictable maintenance workflows, making it practical to run high-performance analytics without overspending or overprovisioning.
Pricing models tailored to usage patterns
Amazon Redshift supports multiple pricing structures designed for both variable and predictable workloads. Each model offers different levels of cost control and scalability, allowing organizations to align infrastructure spending with business goals.
- Capacity-based pricing: Amazon Redshift follows a capacity-based pricing model where businesses pay for the compute capacity (measured in Redshift Processing Units or RPUs) that is provisioned.
- Reserved instance pricing: For businesses with consistent query loads, reserved instances offer savings through 1-year or 3-year commitments. This approach provides budget predictability and cost reduction for steady usage.
- Serverless pricing model: Amazon Redshift Serverless charges based on Amazon Redshift Processing Units (RPUs) consumed during query execution. Since computing pauses during idle time, organizations avoid paying for unused capacity.
- Concurrency scaling credits: When demand spikes, Amazon Redshift spins up additional clusters automatically. Most accounts receive sufficient free concurrency scaling credits to handle typical peak periods without incurring extra costs.
Operational workflows for cluster management
Amazon Redshift offers streamlined workflows for managing cluster operations, ensuring consistent performance, and minimizing the impact of maintenance tasks on business-critical functions.
- Lifecycle control: Clusters can be launched, resized, paused, or deleted using the AWS Console, CLI, or API. Organizations can scale up or down as needed without losing data or configuration.
- Maintenance schedule: Software patches and system updates are applied during customizable maintenance windows to avoid operational disruption.
- Backup and Restore: Automated, incremental backups provide continuous data protection with configurable retention periods. Manual snapshots can be triggered for specific restore points before schema changes or major updates.
- Monitoring and diagnostics: Native integration with Amazon CloudWatch enables visibility into query patterns, compute usage, and performance bottlenecks. Custom dashboards help identify resource constraints early.
Resource optimization within compute nodes
Efficient resource utilization is crucial for maintaining a balance between cost and performance, particularly as data volumes expand and the number of concurrent users increases.
- Compute and storage configuration: Organizations can choose from node types, including RA3 instances that decouple compute from storage. This allows independent scaling based on workload needs.
- Workload management policies: Amazon Redshift supports queue-based workload management, which assigns priority and resource caps to different users or jobs. This ensures that lower-priority operations do not delay time-sensitive queries.
- Storage compression: Data is stored in columnar format with automatic compression, significantly reducing storage costs while maintaining performance.
- Query tuning automation: Amazon Redshift recommends materialized views, caches common queries, and continuously adjusts query plans to reduce compute time, enabling businesses to achieve faster results with lower operational effort.
While Amazon Redshift delivers strong performance and flexibility, many SMBs require expert help to handle implementation complexity, align the platform with business goals, and ensure compliant, growth-oriented outcomes.
How Cloudtech accelerates Amazon Redshift implementation
Cloudtech is a specialized AWS consulting partner dedicated to helping businesses address the complexities of cloud adoption and modernization with practical, secure, and scalable solutions.
Many businesses face challenges in implementing enterprise-grade data warehousing due to limited resources and evolving analytical demands. Cloudtech fills this gap by providing expert guidance and hands-on support, ensuring businesses can confidently deploy Amazon Redshift while maintaining control and compliance.
Cloudtech's team of former AWS employees delivers comprehensive data modernization services that minimize risk and ensure cloud analytics support business objectives:
- Data modernization: Upgrading data infrastructures for improved performance and analytics, helping businesses unlock more value from their information assets through Amazon Redshift implementation.
- Application modernization: Revamping legacy applications to become cloud-native and scalable, ensuring seamless integration with modern data warehouse architectures.
- Infrastructure and resiliency: Building secure, resilient cloud infrastructures that support business continuity and reduce vulnerability to disruptions through proper Amazon Redshift deployment and optimization.
- Generative artificial intelligence: Implementing AI-driven solutions that leverage Amazon Redshift's analytical capabilities to automate and optimize business processes.
Conclusion
Amazon Redshift provides businesses with a secure and scalable foundation for high-performance analytics, eliminating the need to manage infrastructure. With automated optimization, advanced security, and flexible pricing, it enables data-driven decisions across teams while keeping costs under control.
For small and mid-sized organizations, partnering with Cloudtech streamlines the implementation process. Our AWS-certified team helps you plan, deploy, and optimize Amazon Redshift to meet your specific performance and compliance goals. Get in touch with us to get started today!
FAQ’s
1. What is the use of Amazon Redshift?
Amazon Redshift is used to run high-speed analytics on large volumes of structured and semi-structured data. It helps businesses generate insights, power dashboards, and handle reporting without managing traditional database infrastructure.
2. Is Amazon Redshift an ETL tool?
No, Amazon Redshift is not an ETL tool. It’s a data warehouse that works with ETL services like AWS Glue to store and analyze transformed data efficiently for business intelligence and operational reporting.
3. What is the primary purpose of Amazon Redshift?
Amazon Redshift’s core purpose is to deliver fast, scalable analytics by running complex SQL queries across massive datasets. It supports use cases like customer insights, operational analysis, and financial forecasting across departments.
4. What is the best explanation of Amazon Redshift?
Amazon Redshift is a managed cloud data warehouse built for analytics. It separates computing and storage, supports standard SQL, and enables businesses to scale performance without overbuilding infrastructure or adding operational overhead.
5. What is Amazon Redshift best for?
Amazon Redshift is best for high-performance analytical workloads, powering dashboards, trend reports, and data models at speed. It’s particularly useful for SMBs handling growing data volumes across marketing, finance, and operations.

The latest guide to AWS disaster recovery in 2025
No business plans for a disaster, but every business needs a plan to recover from one. In 2025, downtime has become not just inconvenient but also expensive, disruptive, and often public. Whether it’s a ransomware attack, a regional outage, or a simple configuration error, SMBs can’t afford long recovery times or data loss.
That’s where AWS disaster recovery comes in. With cloud-native tools like AWS Elastic Disaster Recovery, even smaller teams can access the kind of resilience once reserved for large enterprises. The goal is to keep the business running, no matter what happens.
This guide breaks down the latest AWS disaster recovery strategies, from simple backups to multi-site architectures, so you can choose the right balance of speed, cost, and protection for your organization.
Key takeaways:
- AWS disaster recovery helps SMBs reduce downtime, protect data, and recover quickly with cloud-native automation and resilience.
- AWS DRS, S3, and multi-region replication enable cost-effective, scalable DR strategies tailored to business RTO and RPO goals.
- Automation with AWS EventBridge, AWS Lambda, and AWS Infrastructure as Code ensures faster, error-free recovery during outages or disasters.
- Cloudtech helps SMBs design secure, compliant, and tested DR plans using AWS tools for continuous backup, replication, and failover.
- Regular DR testing, cost optimization, and multi-region planning make AWS disaster recovery practical and reliable for SMBs in 2025.
Why is disaster recovery mission-critical in 2025?
Disaster recovery (DR) is a core part of business continuity. The digital space has become a high-stakes environment where every minute of downtime can lead to lost revenue, damaged trust, and compliance risks.
For SMBs, these impacts are amplified by smaller teams, tighter budgets, and increasingly complex hybrid environments.
Today’s threats go far beyond hardware failures or accidental data loss. SMBs face:
- Ransomware and cyberattacks can encrypt or destroy critical systems overnight.
- Regional outages caused by power failures or connectivity disruptions.
- Climate-related incidents like floods or wildfires can take entire data centers offline.
- Supply chain disruptions that affect access to infrastructure and recovery resources.
Even short outages can trigger cascading effects, from delayed healthcare operations to missed financial transactions. The question for businesses is no longer if a disruption will happen, but how quickly they can recover when it does.
The shift toward automation and cloud-native resilience: Traditional DR methods like manual failovers, physical backups, and secondary data centers can’t meet modern recovery expectations. Businesses now need:
- Automation to eliminate human delays during failover.
- Scalability to expand recovery capacity instantly.
- Affordability to avoid idle infrastructure costs.
That’s where AWS transforms the game. With AWS Elastic Disaster Recovery (AWS DRS), organizations can continuously replicate data, recover from specific points in time, and spin up recovery instances in minutes, all using a cost-efficient, pay-as-you-go model.
Why it matters for SMBs: For smaller businesses, this evolution is an equalizer. AWS makes enterprise-level resilience achievable without massive capital investment.
By combining automation, scalability, and strong security under a single framework, AWS empowers SMBs to stay operational no matter what 2025 brings.
Suggested Read: Best practices for AWS resiliency: Building reliable clouds

A closer look at AWS’s modern disaster recovery stack
Disaster recovery on AWS has matured into a full resilience ecosystem, not just a backup strategy. It has turned what was once a complex, costly process into a flexible, automated, and affordable framework that SMBs can confidently rely on.
Businesses need continuity for entire workloads, including compute, databases, storage, and networking, with automation that responds instantly to failure events. AWS meets this challenge through an integrated DR ecosystem that combines scalable compute, low-cost storage, and intelligent automation under one cloud-native architecture.
Below is a closer look at the core AWS services powering disaster recovery in 2025:
1. AWS Elastic Disaster Recovery (AWS DRS): The core of modern DR
AWS DRS has become the cornerstone of AWS-based disaster recovery. It continuously replicates on-premises or cloud-based servers into a low-cost staging area within AWS.
- Instant recovery: In case of a disaster, AWS DRS can launch recovery instances in minutes using the latest state or a specific point-in-time snapshot.
- Cross-region replication: Data can be replicated across AWS Regions for compliance or geographic redundancy.
- Scalability and automation: Combined with Lambda or CloudFormation, recovery environments can be automatically scaled to meet post-failover demand.
For SMBs, this service eliminates the need for expensive standby infrastructure while delivering near-enterprise-grade recovery times.
2. Amazon S3, Amazon Glacier, and Amazon Glacier Deep Archive: Tiered, cost-efficient backup storage
Reliable storage remains the foundation of any disaster recovery plan. AWS provides multiple layers of durability and cost optimization through:
- Amazon S3: Ideal for frequently accessed backups and versioned data, offering 99.999999999% durability.
- Amazon S3 Glacier: Designed for infrequent access, with recovery in minutes to hours at a fraction of the cost.
- Amazon S3 Glacier Deep Archive: For long-term retention or compliance data, with recovery times measured in hours but at the lowest possible cost.
These options give SMBs fine-grained control over storage economics, protecting data affordably without sacrificing accessibility.
3. Amazon EC2 and EBS snapshots: Fast restoration for compute and data volumes
Snapshots form the operational backbone of infrastructure recovery.
- Amazon EBS snapshots capture incremental backups of volumes, enabling point-in-time restoration.
- Amazon EC2 snapshots allow entire virtual machines to be redeployed in another Region or Availability Zone.
With automation through AWS Backup or Lambda, these snapshots can be scheduled, monitored, and replicated for quick recovery from corruption or regional failure.
4. AWS CloudFormation and AWS CDK: Infrastructure as Code for recovery at scale
Manual recovery is no longer viable. AWS’s Infrastructure as Code (IaC) tools such as CloudFormation and the Cloud Development Kit (CDK) make it possible to rebuild entire production environments automatically.
- Versioned blueprints: Define compute, storage, and networking configurations once and redeploy anywhere.
- Consistency: Ensure recovery environments are identical to production, avoiding configuration drift.
- Speed: Launch full-stack environments in minutes instead of days.
IaC has become essential for SMBs seeking consistent, repeatable recovery processes without maintaining redundant infrastructure.
5. AWS Lambda and Amazon EventBridge: Automation and event-driven recovery
Recovery is no longer a manual checklist. Using AWS Lambda and Amazon EventBridge, DR processes can be fully automated:
- AWS Lambda runs recovery scripts, initiates failover, or provisions resources the moment a trigger event occurs.
- Amazon EventBridge detects failures, health changes, or compliance events and automatically executes recovery workflows.
This automation ensures that recovery isn’t delayed by human intervention, a critical factor when every second counts.
6. Amazon Route 53: Intelligent failover and traffic routing
Even the best recovery setup fails without smart routing. Amazon Route 53 handles global DNS management and automated failover by:
- Redirecting traffic from failed Regions to healthy ones.
- Supporting active-active or active-passive architectures.
- Monitoring application health continuously for instant redirection.
This ensures users always connect to the most available endpoint, even during major disruptions.
7. Amazon DynamoDB Global Tables and Aurora Global Database: Always-on data replication
Data availability is at the heart of resilience. AWS provides globally distributed data replication options for mission-critical workloads:
- Amazon DynamoDB Global Tables replicate changes in milliseconds across Regions, ensuring applications remain consistent and writable anywhere.
- Amazon Aurora Global Database replicates data with sub-second latency, allowing immediate failover with minimal data loss.
These services make multi-region architectures practical even for SMBs, enabling near-zero RPO and RTO without complex replication management.
Each service complements the others, helping SMBs build DR strategies that are both technically sophisticated and financially realistic.
Whether recovering from a cyberattack, system outage, or natural disaster, AWS gives organizations the agility to resume operations quickly, without the traditional complexity or capital expense of disaster recovery infrastructure. In short, it’s resilience reimagined for the cloud-first era.
Also Read: An AWS cybersecurity guide for SMBs in 2025

Effective strategies for disaster recovery in AWS
When selecting a disaster recovery (DR) strategy within AWS, it’s essential to evaluate both the Recovery Time Objective (RTO) and the Recovery Point Objective (RPO). Each AWS DR strategy offers different levels of complexity, cost, and operational resilience. Below are the most commonly used strategies, along with detailed technical considerations and the associated AWS services.
1. Backup and restore
The Backup and restore strategy involves regularly backing up your data and configurations. In the event of a disaster, these backups can be used to restore your systems and data. This approach is affordable but may require several hours for recovery, depending on the volume of data.
Key technical steps:
- AWS backup: Automates backups for AWS services, such as EC2, RDS, DynamoDB, and EFS. It supports cross-region backups, ideal for regional disaster recovery.
- Amazon S3 versioning: Enable versioning on S3 buckets to store multiple versions of objects, which can help recover from accidental deletions or data corruption.
- Infrastructure as code (IaC): Use AWS CloudFormation or AWS CDK to define infrastructure templates. These tools automate the redeployment of applications, configurations, and code, reducing recovery time.
- Point-in-time recovery: Use Amazon RDS snapshots, Amazon EBS snapshots, and Amazon DynamoDB backups for point-in-time recovery, ensuring that you meet stringent RPOs.
AWS Services:
- Amazon RDS for database snapshots
- Amazon EBS for block-level backups
- Amazon S3 Cross-region replication for continuous replication to a DR region
2. Pilot light
In the pilot light approach, minimal core infrastructure is maintained in the disaster recovery region. Resources such as databases remain active, while application servers stay dormant until a failover occurs, at which point they are scaled up rapidly.
Key technical steps:
- Continuous data replication: Use Amazon RDS read replicas, Amazon Aurora global databases, and DynamoDB global tables for continuous, cross-region asynchronous data replication, ensuring low RPO.
- Infrastructure management: Deploy core infrastructure using AWS CloudFormation templates across primary and DR regions, keeping application configurations dormant to reduce costs.
- Traffic management: Utilize Amazon Route 53 for DNS failover and AWS global accelerator for more efficient traffic management during failover, ensuring traffic is directed to the healthiest region.
AWS Services:
- Amazon RDS read replicas
- Amazon DynamoDB global tables for distributed data
- Amazon S3 Cross-Region Replication for real-time data replication
3. Warm standby
Warm Standby involves running a scaled-down version of your production environment in a secondary AWS Region. This allows minimal traffic handling immediately and enables scaling during failover to meet production needs.
Key technical steps
- EC2 auto scaling: Use Amazon EC2 auto scaling to scale resources automatically based on traffic demands, minimizing manual intervention and accelerating recovery times.
- Amazon Aurora global databases: These offer continuous cross-region replication, reducing failover latency and allowing a secondary region to take over writes during a disaster.
- Infrastructure as code (IaC): Use AWS CloudFormation to ensure both primary and DR regions are deployed consistently, making scaling and recovery easier.
AWS services
- Amazon EC2 auto scaling to handle demand
- Amazon Aurora global databases for fast failover
- AWS Lambda for automating backup and restore operations
4. Multi-site active/active
The multi-site active/active strategy runs your application in multiple AWS Regions simultaneously, with both regions handling traffic. This provides redundancy and ensures zero downtime, making it the most resilient and comprehensive disaster recovery option.
Key technical steps:
- Global load balancing: Utilize AWS Global Accelerator and Amazon Route 53 to manage traffic distribution across regions, ensuring that traffic is routed to the healthiest region in real-time.
- Asynchronous data replication: Implement Amazon Aurora global databases with multi-region replication for low-latency data availability across regions.
- Real-time monitoring and failover: Utilize AWS CloudWatch and AWS Application Recovery Controller (ARC) to monitor application health and automatically trigger traffic failover to the healthiest region.
AWS services:
- AWS Global Accelerator for low-latency global routing
- Amazon Aurora global databases for near-instantaneous replication
- Amazon Route 53 for failover and traffic management
Also Read: Hidden costs of cloud migration and how SMBs can avoid them

Advanced considerations for AWS disaster recovery in 2025
While AWS offers several core disaster recovery strategies, from backup and restore to multi-site active/active, modern resilience planning requires going a step further. SMBs can strengthen their DR posture by adopting advanced practices around architecture design, automation, governance, and cost optimization.
Here are some important considerations:
1. Choosing the right architecture: single-region vs. multi-region
Not every workload needs a multi-region setup, but every business needs redundancy. AWS offers multiple architectural layers to meet varying RTO/RPO goals:
- Multi-AZ redundancy for regional resilience: Replicating workloads across multiple Availability Zones (AZs) within a single AWS Region protects against localized data center outages. It’s ideal for applications that require high uptime but have data residency or regulatory constraints.
- Cross-region backups for disaster-level protection: Backing up to another AWS Region adds a safeguard against large-scale events such as natural disasters or regional power failures. Tools like AWS Backup and Amazon S3 Cross-Region Replication make this seamless and automated.
- Multi-region deployments for maximum availability: For mission-critical workloads, running active systems in multiple AWS Regions provides near-zero downtime. Services like Amazon Aurora Global Database and DynamoDB Global Tables ensure your data stays synchronized worldwide.
Tip: Choose your redundancy level based on your recovery time objective (RTO) and recovery point objective (RPO). Not every system needs multi-region replication; sometimes a hybrid of local resilience and selective replication is more cost-effective.
2. Automating recovery and testing
Automation is the backbone of successful disaster recovery. Manual steps increase both error risk and downtime, especially under pressure.
- Event-driven recovery: Use Amazon EventBridge and AWS Lambda to automate failover workflows, detect system anomalies, and trigger predefined recovery actions without manual intervention.
- Automated testing: Leverage AWS Resilience Hub and AWS Elastic Disaster Recovery (AWS DRS) to perform non-disruptive recovery tests. Regular “game days” and simulated failovers help validate that your systems can actually meet RTO and RPO targets when it counts.
- Continuous documentation updates: After each test, refine your DR runbooks, IAM roles, and escalation workflows. Resilience isn’t static—it evolves as your architecture changes.
3. Governance, compliance, and security best practices
A DR plan is only as strong as its security controls. Ensuring that recovery operations comply with data protection and industry regulations is critical.
- Secure access and encryption: Use AWS Identity and Access Management (IAM) for least-privilege access and AWS Key Management Service (KMS) for encryption key control.
- Compliance-ready backups: AWS services can help meet standards such as HIPAA, FINRA, and SOC 2 through auditable, tamper-proof data storage.
- Credential isolation: Keep backup and recovery credentials separate from production access to reduce the risk of simultaneous compromise during an incident.
4. Cost optimization for SMBs
Resilience shouldn’t break your budget. AWS enables cost-effective recovery through flexible storage tiers and on-demand infrastructure.
- Use tiered storage: Store frequently accessed backups in Amazon S3, long-term archives in Amazon Glacier, and deep archives in Amazon Glacier Deep Archive for significant cost savings.
- Automate lifecycle policies: Configure automatic transitions between storage tiers to minimize manual oversight and wasted spend.
- Selective replication: Not all data needs to be replicated across regions—focus on critical workloads first.
- Pay-as-you-go recovery: Services like AWS Elastic Disaster Recovery (DRS) allow you to maintain minimal compute during normal operations and scale up only when needed, avoiding the cost of a full secondary site.
Example: Many SMBs start with a pilot light configuration for essential systems and expand to warm standby as their business and recovery needs grow, achieving resilience in phases without large upfront investments.
By integrating automation, security, and cost awareness into your AWS disaster recovery plan, SMBs can achieve enterprise-grade resilience without enterprise-level complexity. The key isn’t just recovering quickly; it’s building a DR strategy that evolves with your business.
Challenges of automating AWS disaster recovery for SMBs (and how to solve them)
AWS disaster recovery automation empowers SMBs with multiple strategies and solutions for disaster recovery. However, SMBs must address setup complexity and ongoing costs and ensure continuous monitoring to benefit fully.
Here are some common challenges and how to solve them:
1. Complex multi-region orchestration: Coordinating automated failover across multiple AWS Regions can be intricate, risking data inconsistency and downtime.
Solution: Use AWS Elastic Disaster Recovery (AWS DRS) and AWS CloudFormation/CDK to define reproducible, automated multi-region failover processes, reducing human error and synchronization issues.
2. Cost management under strict RTO/RPO targets: Low RTOs and RPOs often require high resource usage, which can escalate costs quickly.
Solution: Implement tiered storage with Amazon S3, Amazon Glacier, and Amazon Glacier Deep Archive, and leverage on-demand DR environments rather than always-on secondary systems to optimize costs.
3. Replication latency and data lag: Cross-region replication can introduce delays, risking data inconsistency within recovery windows.
Solution: Use DynamoDB Global Tables or Aurora Global Database for near real-time multi-region replication and configure RPO tolerances according to workload criticality.
4. Maintaining compliance and security: Automated DR workflows must meet regulatory standards (HIPAA, SOC 2), requiring continuous monitoring and audit-ready reporting.
Solution: Employ AWS Backup Audit Manager, IAM roles with least-privilege access, and AWS KMS for encryption, ensuring compliance without adding manual overhead.
5. Operational overhead of testing and validation: Regular failover drills and recovery testing are resource-intensive, especially for small IT teams.
Solution: Use AWS Resilience Hub and AWS DRS non-disruptive testing to automate simulation drills, validate RTO/RPO targets, and continuously refine DR plans.
Despite these challenges, AWS remains the leading choice for SMB disaster recovery due to its extensive global infrastructure, comprehensive native services, and flexible pay-as-you-go pricing.
Also Read: A complete guide to Amazon S3 Glacier for long-term data storage

How does Cloudtech help SMBs implement AWS disaster recovery strategies?
For SMBs, building a resilient disaster recovery (DR) framework is no longer optional; it’s essential for minimizing downtime, protecting data, and ensuring business continuity. Cloudtech simplifies this process with an AWS-native, SMB-first approach that emphasizes automation, compliance, and measurable recovery outcomes.
Here’s how Cloudtech enables reliable AWS disaster recovery for SMBs:
- Cloud foundation and governance: Cloudtech sets up secure, multi-account AWS environments using AWS Control Tower, AWS Organizations, and AWS IAM. This ensures strong governance, access management, and cost visibility for DR operations from day one.
- Workload recovery and resiliency: Using AWS Elastic Disaster Recovery (AWS DRS), AWS Backup, and Amazon Route 53, Cloudtech implements structured DR plans with automated failover. This reduces disruption and maintains high availability for critical workloads during outages.
- Application recovery and modernization: Cloudtech adapts legacy applications into scalable, cloud-native architectures using AWS Lambda, Amazon ECS, and Amazon EventBridge. This enables faster recovery, efficient resource usage, and automation-driven failover for production workloads.
- Data protection and integration: Through Amazon S3, AWS Backup, and Multi-AZ configurations, Cloudtech ensures continuous data replication, backup retention, and regional redundancy, providing SMBs with secure and reliable access to their critical data.
- Automation, testing, and monitoring: Cloudtech uses EventBridge and AWS DRS automation, along with regular DR drills and validation exercises, to continuously test recovery procedures, maintain compliance, and optimize RTO/RPO targets.
Cloudtech’s proven AWS disaster recovery methodology ensures SMBs don’t just recover from outages; they modernize, automate, and scale their DR strategy securely. The result is a cloud-native, cost-efficient DR environment that protects business operations and enables growth in 2025 and beyond.
Also Read: 10 common challenges SMBs face when migrating to the cloud

Wrapping up
Effective disaster recovery is critical for SMBs to safeguard operations, data, and customer trust in an unpredictable environment. AWS provides a powerful, flexible platform offering diverse strategies, from backup and restore to multi-site active-active setups, that help SMBs balance recovery speed, cost, and complexity.
Cloudtech simplifies the complexity of disaster recovery, enabling SMBs to focus on growth while maintaining strong operational resilience. To strengthen your disaster recovery plan with AWS expertise, visit Cloudtech and explore how Cloudtech can support your business continuity goals.
FAQs
1. How does AWS Elastic Disaster Recovery improve SMB recovery plans?
AWS Elastic Disaster Recovery continuously replicates workloads, reducing downtime and data loss. It automates failover and failback, allowing SMBs to restore applications quickly without complex manual intervention, improving recovery speed and reliability.
2. What are the cost implications of using AWS for disaster recovery?
AWS DR costs vary based on data volume and recovery strategy. Pay-as-you-go pricing helps SMBs avoid upfront investments, but monitoring storage, data transfer, and failover expenses is essential to optimize overall costs.
3. Can SMBs use AWS disaster recovery without a dedicated IT team?
Yes, AWS offers managed services and automation tools that simplify DR setup and management. However, SMBs may benefit from expert support to design and maintain effective recovery plans tailored to their business needs.
4. How often should SMBs test their AWS disaster recovery plans?
Regular testing, at least twice a year, is recommended to ensure plans work as intended. Automated testing tools on AWS can help SMBs perform failover drills efficiently, reducing operational risks and improving readiness.
Get started on your cloud modernization journey today!
Let Cloudtech build a modern AWS infrastructure that’s right for your business.