Blogs


AWS Step Functions explained: A complete implementation guide
Managing complex workflows across multiple AWS services can be difficult to scale and maintain. AWS Step Functions solves this by providing a serverless workflow engine that coordinates tasks into defined, reliable sequences without requiring custom orchestration logic.
For example, a healthcare SMB automating patient onboarding can use Step Functions to chain together Lambda functions for data validation, store records in DynamoDB, run a background verification via API Gateway, and send confirmation emails. They can do all this in a single visual workflow with built-in error handling and retries.
This guide explains how AWS Step Functions work, how to implement them with best practices, and how small and mid-sized businesses can use them to improve automation, reduce complexity, and move faster without sacrificing control.
Key takeaways:
- Step Functions simplify orchestration: They coordinate services like Lambda, S3, Glue, and DynamoDB into reliable, visual workflows, eliminating the need for custom orchestration code.
- Built for complex, scalable automation: Supports both long-running and high-throughput workflows with features like retries, branching, and parallel execution, ideal for modern backend systems.
- Real-world use cases are production-ready: Examples include ETL pipelines, event-driven file processing, multi-branch data merges, and human-in-the-loop approvals, built using actual SMB patterns.
- Deep AWS integration is a core strength: It smoothly integrates with over 220 AWS services, including Amazon Redshift, SNS/SQS, CloudWatch, and RDS, thereby reducing infrastructure overhead and improving consistency.
- Monitoring and debugging are built in: With CloudWatch and X-Ray, teams gain full visibility into the execution flow, performance issues, and error traces, critical for achieving operational excellence.
What is AWS Step Functions?
AWS Step Functions is a fully managed orchestration service that simplifies how teams coordinate distributed workflows across AWS. It utilizes Amazon States Language (ASL) to define processes as state machines, which are JSON-based workflows that link services such as Lambda, S3, DynamoDB, and others.
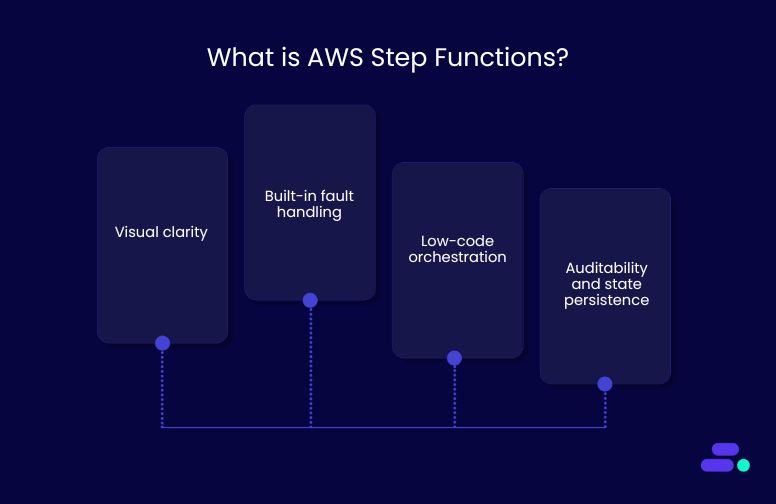
Step Functions brings several advantages to cloud-native architectures:
- Visual clarity: Workflows are represented as state diagrams, making logic easier to understand and debug.
- Built-in fault handling: Automatic retries, catch blocks, and state tracking ensure workflows are resilient to failures.
- Low-code orchestration: Developers focus on business logic while Step Functions handles flow control, error handling, and sequencing.
- Auditability and state persistence: Long-running workflows can pause and resume, while all execution history is recorded for traceability.
The service integrates natively with over 220 AWS services, including Amazon ECS, SageMaker, AWS Glue, and Athena. These native integrations simplify operations such as passing data between services, managing retries and exceptions, and handling authentication, all without custom glue code.
Whether coordinating high-volume data processing tasks or managing approval flows in business processes, Step Functions offers a scalable, reliable foundation for building event-driven and serverless applications on AWS.

Implementing AWS Step Functions: a step-by-step guide

For SMBs looking to automate processes without overcomplicating infrastructure, AWS Step Functions offers a practical and scalable solution. This service helps coordinate tasks across AWS, allowing technical teams to focus on business value instead of operational plumbing.
To understand how it works, consider a familiar scenario of a healthcare center automating a patient intake and scheduling workflow using AWS Step Functions. The workflow includes:
- Accept patient registration
- Verify insurance details
- Check provider availability
- Schedule appointment
- Send a confirmation email
Each step is orchestrated by AWS Step Functions, using services like AWS Lambda, Amazon DynamoDB, and Amazon SES.
Step 1: Define the workflow using Amazon States Language (ASL)
The first step is defining a state machine using Amazon States Language (ASL). Each “state” maps to a task in the intake process.
Example ASL definition:
{
"StartAt": "VerifyInsurance",
"States": {
"VerifyInsurance": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:acct:function:VerifyInsurance",
"Next": "CheckAvailability"
},
"CheckAvailability": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:acct:function:CheckAvailability",
"Next": "ScheduleAppointment"
},
"ScheduleAppointment": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:acct:function:ScheduleAppointment",
"Next": "SendConfirmation"
},
"SendConfirmation": {
"Type": "Task",
"Resource": "arn:aws:lambda:region:acct:function:SendEmail",
"End": true
}
}
}What this code does: This JSON defines an AWS Step Functions state machine that automates a patient appointment workflow. It specifies a sequence of tasks, each linked to an AWS Lambda function:
- StartAt: "VerifyInsurance": The workflow begins by verifying the patient’s insurance.
- "VerifyInsurance": Calls a Lambda function to validate insurance, then moves to check provider availability.
- "CheckAvailability": Queries available appointment slots.
- "ScheduleAppointment": Books the appointment in the system.
- "SendConfirmation": Sends a confirmation email to the patient and ends the workflow.
Each state is a step in the process, and the Next or End fields control the execution flow. This enables a fully automated, fault-tolerant healthcare intake process.
Step 2: Build the supporting AWS Lambda functions
Once the workflow is defined in Step Functions, each state must be backed by a purpose-built AWS Lambda function that executes a specific task in the sequence. These functions contain the actual business logic, whether it’s checking insurance, querying appointment slots, or sending emails. They are triggered automatically as the state machine progresses.
Each function should be:
- Modular and independently testable
- Scoped with minimal IAM permissions
- Configured with timeouts and retries based on expected SLA
This separation of concerns ensures each task is easy to manage, secure, and scalable, allowing healthcare teams to update or extend individual steps without disrupting the entire process.
Example Lambda (Node.js) for insurance verification:
exports.handler = async (event) => {
const isValid = await checkInsuranceAPI(event.insuranceId);
if (!isValid) throw new Error("Insurance verification failed");
return { status: "verified" };
};Here:
- event.insuranceId: Receives the insurance ID from the Step Functions input.
- checkInsuranceAPI(...): Calls an asynchronous function to verify insurance status with an external system.
- Error Handling: If the insurance is not valid, the function throws an error. Step Functions can catch this and route to an error state.
- Return: If the insurance is verified, it returns a success status for the next step in the workflow.
This function typically powers the VerifyInsurance state in a healthcare appointment scheduling workflow.
Step 3: Add error handling and retries
Healthcare workflows require fault tolerance. Step Functions provides native retry and catch mechanisms.
Example retry config for insurance check:
"VerifyInsurance": {
"Type": "Task",
"Resource": "arn:aws:lambda:...:VerifyInsurance",
"Retry": [
{
"ErrorEquals": ["Lambda.ServiceException"],
"IntervalSeconds": 5,
"MaxAttempts": 3
}
],
"Catch": [
{
"ErrorEquals": ["States.ALL"],
"Next": "LogFailure"
}
],
"Next": "CheckAvailability"
}Here:
- Type: "Task": This is a state that runs a task. In this case, a Lambda function.
- Resource: The ARN of the Lambda function VerifyInsurance, which handles insurance validation.
- Retry block: Retries up to 3 times if the Lambda returns a Lambda.ServiceException (a common transient error). Waits 5 seconds between each retry.
- Catch block: Catches all types of errors (States.ALL) if retries fail. Redirects the flow to a fallback state called LogFailure, which could handle logging, alerting, or compensation.
- Next: If the Lambda succeeds, the flow continues to CheckAvailability.
This setup ensures resilience and error visibility. If the insurance verification step temporarily fails (e.g., due to network latency), retries handle it automatically. If the failure is persistent, it is safely caught and redirected, preventing silent workflow failures.
Step 4: Visualize and test the workflow
Once the state machine is defined and deployed, the AWS Step Functions visual workflow console provides a clear, interactive way to test and monitor it, making it valuable for both technical and non-technical stakeholders.
The visual interface shows the full execution path of the workflow, step by step. This allows teams to see how data moves, where errors may occur, and what the outputs are at each stage. It also helps stakeholders like clinic administrators understand and verify the business logic before deploying to production.
Key benefits of the visual console:
- Real-time execution tracking: Each state is highlighted as it executes, providing instant visibility into progress and outcomes.
- Step-level inspection: Click into each state to view input/output data, runtime metrics, and any errors, ideal for debugging.
- Test case simulation: Teams can run test inputs (e.g., invalid insurance ID, unavailable appointment slots) to validate error handling and fallback logic.
- Cross-functional clarity: Non-developers can follow the workflow visually, making collaboration across technical and business teams easier.
This step ensures the workflow is functioning as intended, reduces the risk of bugs post-deployment, and builds team confidence in the automation.
Step 5: Secure and monitor the workflow
In healthcare scenarios, especially those involving sensitive patient data, security and observability are non-negotiable. AWS Step Functions, combined with supporting AWS services, allows SMBs to build workflows that are secure, compliant (e.g., with HIPAA), and fully traceable.
To ensure that every step of the workflow is both protected and observable, it’s important to implement the following:
Security best practices:
- Use least-privilege IAM roles: Assign narrowly scoped roles to each Lambda function and the Step Function itself. This limits what resources each service can access, minimizing risk if credentials are compromised.
- Encrypt environment variables and outputs: Ensure sensitive data (like patient IDs or insurance info) is encrypted in transit and at rest using AWS KMS.
Monitoring and observability:
- Enable CloudWatch Logs: Log all execution data, including inputs, outputs, errors, and durations. These logs are essential for debugging and post-incident analysis.
- Set CloudWatch Alarms: Trigger alerts for failed states, such as an unverified insurance policy or a scheduling failure, so the ops team can respond immediately.
- Enable AWS X-Ray (optional): For more complex workflows, X-Ray traces end-to-end execution across services like Lambda, API Gateway, or DynamoDB, helping diagnose latency and bottlenecks.
By integrating these tools, SMBs get enterprise-grade monitoring and security without needing costly third-party solutions. This foundation supports both trust and reliability in healthcare workflows.
Step 6: Scale and expand
As the healthcare SMB grows, adding new providers, locations, or services, the appointment scheduling workflow must evolve to handle increased complexity without creating new technical debt. AWS Step Functions is designed with modularity and scalability in mind, allowing teams to enhance their workflows incrementally.
Ways to expand the workflow:
- Parallel states: Support multiple provider checks at the same time (e.g., when a patient can see any available doctor across departments).
- Choice states: Route logic based on insurance type, appointment urgency, or patient age group. For example, directing pediatric appointments to specific providers.
- Map states: Handle batch processes like sending follow-up reminders for multiple patients, processing appointment cancellations in bulk, or reconfirming bookings.
Why this matters: Step Functions allows SMBs to scale without rewrites. As regulations, services, or team sizes change, businesses can plug in new functionality with minimal disruption. This adaptability is especially valuable in healthcare, where patient care, compliance, and system reliability must go hand in hand.
Final outcome: What does the SMB get out of AWS Step Functions?
Using AWS Step Functions to automate appointment scheduling allows the healthcare SMB to transform a fragmented intake process into a coordinated, reliable workflow. The result is:
- Streamlined operations: Tasks like insurance checks, scheduling, and notifications run seamlessly without manual coordination.
- Faster patient onboarding: Real-time validation and booking reduce delays for both patients and staff.
- Lower operational overhead: Staff spend less time chasing paperwork or managing schedules, freeing up time for patient-facing activities.
- Built-in adaptability: New services, insurers, or routing rules can be added with minimal changes to existing logic.
The overall impact is greater efficiency, fewer errors, and a foundation that supports both patient satisfaction and long-term business growth.

AWS Step Functions: popular use cases and examples
SMBs with limited DevOps resources but growing backend complexity, such as healthcare providers, fintech startups, SaaS vendors, and e-commerce businesses, benefit most from AWS Step Functions. These organizations need to automate multi-step processes like appointment scheduling, transaction validation, or order fulfillment across several AWS services without building and maintaining brittle glue code.
Built-in retries, state tracking, and visual debugging make it easier to deliver consistent outcomes, handle failures gracefully, and meet compliance or SLA requirements. With AWS Step Functions, SMBs can implement resilient, observable workflows with minimal operational overhead.
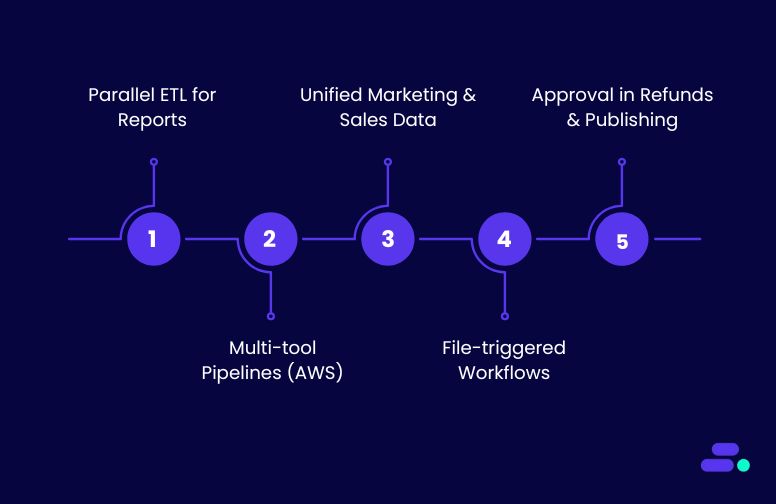
1. Parallel ETL processing for daily business reports
The challenge: A retail SMB needed to process product, transaction, and user data nightly for business dashboards. Running ETL tasks one after another created delays and missed report deadlines.
How AWS Step Functions helped: Using a Parallel state, AWS Step Functions ran three AWS Glue jobs simultaneously:
- Product data was validated and standardized.
- Transactions were deduplicated and enriched.
- User logs were normalized by timestamp.
If any job failed, the error was logged in AWS DynamoDB, and an alert was sent through Amazon SNS. Successful outputs were merged and loaded into Amazon Redshift.
Outcome: Faster pipeline execution, reduced latency, and consistent daily insights, all without manual coordination.
2. Multi-tool data pipelines using AWS
The challenge: A fintech client processed various datasets using different tools—AWS Glue for cleaning, Amazon EMR for heavy compute, and Amazon Athena for querying—but lacked orchestration across services.
How Step Functions helped: The workflow used a Choice state to inspect file schema and trigger the correct tool:
- Schema A → Glue job
- Schema B → EMR cluster with PySpark
After processing, Athena ran a validation query. Based on results, data was marked complete in DynamoDB or rerouted for reprocessing.
Outcome: One orchestrated pipeline with tool-specific optimization, improving SLAs and eliminating manual triggers.
3. Unified marketing + sales data for executive reporting
The challenge: Marketing and sales teams processed data in silos, leading to inconsistent metrics. Leadership needed a unified view for campaign ROI.
How Step Functions helped: A Parallel state launched:
- A Glue job for ad campaign metadata
- A Lambda chain for sales transactions and currency normalization
Both outputs were stored in Amazon S3 and joined using a Lambda function keyed on campaign IDs. Final results were written to Amazon Redshift.
Outcome: Consistent, near-real-time insights across departments with reduced manual data merging.
4. File-triggered workflows with conditional routing
The challenge: A logistics SMB received daily files (orders, inventory, returns) via Amazon S3, but handled each manually. Errors and delays were common.
How Step Functions helped: S3 event notifications triggered a Lambda function that parsed file metadata. A Choice state then routed:
- “Orders” → Glue job
- “Inventory” → Lambda formatter
- Unknown files → Archive + alert via SNS
Each processing path included success checks and stored results in partitioned S3 folders.
Outcome: Fully automated, reliable workflows triggered by file uploads with dynamic routing logic.
5. Human approval in refund and publishing workflows
The challenge: A healthcare SMB needed human approval for certain actions like patient record updates and issuing refunds while keeping automation intact.
How Step Functions helped: The workflow paused using task tokens after an automated refund eligibility check.
A reviewer received an approval link via email. Based on their decision:
- Approved → credit issued
- Rejected → action logged and archived
Timeouts ensured no indefinite waiting; escalations triggered if no response came in.
Outcome: Built-in compliance, traceability, and secure human input within a fully automated backend.

With the help of AWS partners like Cloudtech, SMBs can quickly integrate AWS Step Functions into their existing workflows. Their deep AWS expertise and an SMB-first approach helps design, implement, and optimize step-based automation tailored to business needs.
How does Cloudtech implement AWS Step Functions for scalable business workflows?
Cloudtech helps small and mid-sized businesses build production-grade orchestration systems using AWS Step Functions, enabling secure and scalable automation of backend workflows. As an AWS Advanced Tier Services Partner, it provides full lifecycle implementation with deep integration into AWS-native services, robust security, and long-term support.
Key areas of implementation include:
- Data modernization: Cloudtech uses AWS Glue, Amazon S3, and Amazon Redshift to coordinate data ingestion, transformation, and governed storage. Workflows include built-in alerting with Amazon CloudWatch and Amazon SNS, and audit visibility using AWS CloudTrail.
- Serverless backend orchestration: Cloudtech decouples application logic using AWS Lambda and AWS Step Functions to handle conditional flows, retries, and external service calls, creating maintainable, scalable systems that replace legacy scripts or hardcoded integrations.
Every deployment includes secure IAM configuration, AWS Key Management Service (AWS KMS) encryption, and optional use of AWS Secrets Manager for sensitive data handling. Monitoring and debugging are set up using Amazon CloudWatch Logs, CloudWatch Metrics, and AWS X-Ray.
For SMBs transitioning to cloud-native operations or expanding existing AWS usage, Cloudtech offers deep Step Functions expertise and operational rigor to accelerate implementation and maximize ROI.

Conclusion
AWS Step Functions bring structure and resilience to complex cloud workflows, making it easier for small and mid-sized businesses to automate operations without sacrificing control. By managing retries, branching logic, and service coordination in one place, they eliminate the need for brittle scripts or manual handoffs.
Cloudtech uses AWS Step Functions to turn scattered cloud tasks into unified, production-grade systems, whether it's automating patient intake in healthcare or orchestrating ETL pipelines in finance. Each implementation is optimized for cost, security, and long-term maintainability, tailored to the business’s specific cloud maturity and growth goals.
Reach out to us for implementation support and architecture aligned with AWS best practices.
FAQ’s
1. What are the Step Functions in AWS?
AWS Step Functions is a serverless orchestration service that connects AWS components into workflows. It utilizes visual state machines to manage execution flow, error handling, and parallel tasks, thereby automating and controlling backend processes at scale.
2. What are the types of Step Functions in AWS?
AWS offers Standard and Express workflows. Standard supports long-running, durable processes with full execution history, while Express is optimized for short-lived, high-volume tasks that require fast throughput and cost-efficient execution.
3. What are some of the applications of AWS Step Functions?
Step Functions are used for ETL pipelines, file-driven workflows, modular backends, approval flows, and distributed data processing. They support event-based automation and coordinate services like Lambda, Glue, DynamoDB, and SNS with built-in observability.
4. What is the difference between AWS Lambda and AWS Step Functions?
Lambda executes individual functions, while Step Functions coordinates multiple functions and services into structured workflows. Step Functions manage sequencing, retries, and branching across steps, whereas Lambda focuses on executing single tasks.
5. Is AWS Step Functions similar to Azure?
AWS Step Functions is similar to Azure Durable Functions. Both offer orchestration of serverless tasks using stateful workflows, allowing developers to manage dependencies, parallelism, and retries without writing complex coordination code.

A guide to AWS Lambda environment variables
Consider a growing SaaS company deploying a new feature using AWS Lambda to streamline part of its user workflow. But soon after launch, unexpected behavior surfaced in production. The codebase wasn’t changed, but the function didn’t execute as expected. After a deep dive, the issue is traced back to a simple but critical oversight: a misconfigured environment variable.
For many small and mid-sized businesses (SMBs) adopting serverless on AWS, environment variables in Lambda often fly under the radar—until they don’t. They control how functions connect to services, manage API keys, and handle environment-specific logic. When managed well, they reduce code duplication and speed up deployments. When overlooked, they can introduce bugs that are hard to trace.
This guide provides SMB teams with a practical understanding of AWS Lambda environment variables. From secrets management to debugging strategies, it offers best practices to help teams avoid common missteps and build more reliable serverless applications from the start.
Key takeaways
- Environment variables enable dynamic configuration: Lambda environment variables let businesses change runtime behavior, like API endpoints, feature flags, or logging levels.
- Security starts with proper encryption and access control: AWS automatically encrypts variables using KMS, but using customer-managed keys and IAM least-privilege policies provides stronger protection for sensitive data.
- Tools like AWS Secrets Manager and Parameter Store are better for secrets: Storing credentials directly in environment variables can be risky. Use AWS-native secret managers for secure storage, audit trails, and automatic rotation.
- The Serverless Framework simplifies multi-environment deployments: With stage-specific overrides, secret references, and version-controlled configs, teams can manage complex setups cleanly across dev, staging, and production.
- Following naming conventions and validation improves stability
Clear variable naming, environment-specific separation, and startup validation reduce misconfigurations and deployment issues, especially in growing teams.
What are AWS Lambda environment variables?
AWS Lambda environment variables are key-value pairs used to store configuration data outside of the function code. These variables live within the Lambda execution environment and are accessible via standard access methods (like process.env in Node.js or os.environ in Python), depending on the runtime.
By keeping configuration separate from code, environment variables allow teams to modify runtime behavior without redeploying the function. This is a major advantage for SMBs looking to reduce operational overhead and deployment risk.
Why environment variables matter: Hardcoding configuration values like API keys, database credentials, or feature flags into function code can lead to:
- Increased redeployment cycles for minor changes
- Higher risk of leaking sensitive values through version control
- Reduced ability to reuse code across dev, test, and production environments
Using environment variables helps avoid these issues by enabling:
- Dynamic runtime configuration
- Cleaner separation of code and environment
- Secure, encrypted storage of sensitive values via AWS Key Management Service (KMS)
Here’s how AWS Lambda handles them:
- Immutable at runtime: Environment variables are loaded once per container lifecycle, during the initialization phase. They remain constant throughout the life of that execution environment.
- Encrypted at rest: AWS encrypts environment variables using AWS KMS, ensuring that sensitive data is protected even if access is misconfigured.
- Scoped per version or alias: Businesses can assign different environment variables to each version or alias of their Lambda function, helpful for environment-specific deployments.
Using Lambda environment variables effectively allows SMBs to improve deployment agility, security posture, and operational consistency, especially as serverless architectures scale across teams or environments.
How does AWS Lambda store and load environment variables?
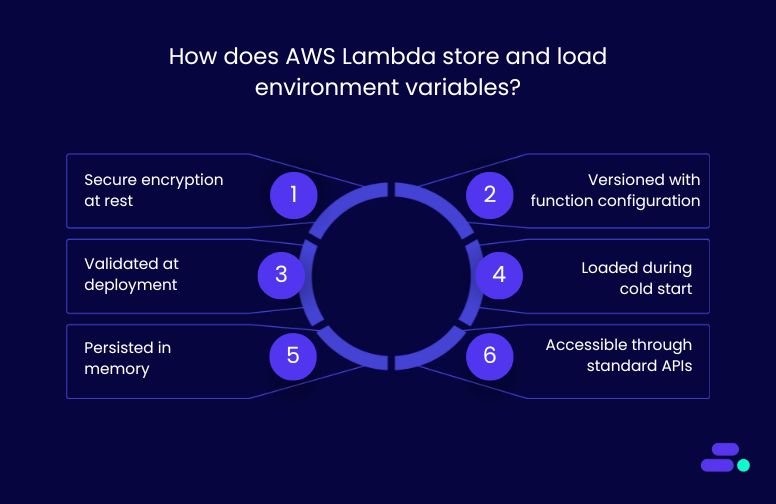
AWS Lambda uses a secure and efficient process to store and load environment variables, enabling functions to behave differently across environments without modifying code. This approach ensures both security and performance throughout the function lifecycle.
1. Secure encryption at rest: Lambda stores all environment variables as part of the function’s configuration and encrypts them using AWS Key Management Service (KMS). This can be either an AWS-managed key or a customer-managed KMS key. These encrypted values are stored with other function settings such as runtime, memory allocation, and timeout duration.
2. Versioned with function configuration: Each time a function is published as a new version, the environment variables are included as part of that version’s configuration. This allows teams to roll back safely or run multiple versions of the same function with different configurations (e.g., dev vs. prod), without affecting stability.
3. Validated at deployment: Lambda automatically validates environment variable syntax and enforces a maximum total size of 4KB per function. This includes all key-value pairs and formatting. If the limit is exceeded or formatting is invalid, the deployment is rejected before it reaches production.
4. Loaded during cold start: When a new execution environment is initialized (a cold start), Lambda decrypts the environment variables using KMS and injects them into the container. This process happens once, before any code is executed, ensuring variables are available from the start.
5. Persisted in memory: After a cold start, environment variables are cached in memory for the duration of the container’s lifecycle. During warm invocations, Lambda does not need to re-decrypt or reload them, improving performance without compromising security.
6. Accessible through standard APIs: Environment variables are made available through standard language-specific APIs:
- process.env in Node.js
- os.environ in Python
- Environment.GetEnvironmentVariable() in .NET
This method allows developers to configure functions dynamically without changing code, reducing deployment cycles and supporting consistent behavior across multiple environments.
How to set environment variables in AWS Lambda?
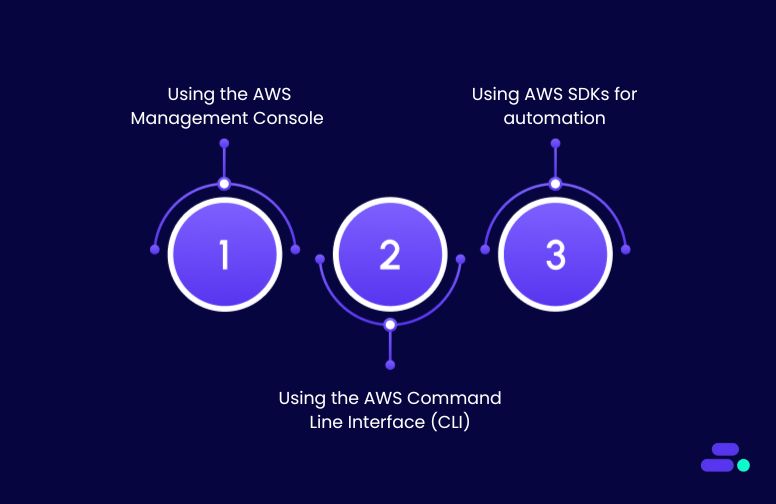
Environment variables in AWS Lambda can be configured using three main methods, via the AWS Console, CLI, or SDKs, depending on a team’s technical workflow and scale. Each method allows developers to separate runtime configuration from code, streamlining updates without redeploying functions.
1. Using the AWS Management Console
The Console is ideal for smaller teams or quick configuration changes. It provides a user-friendly interface to define up to 50 key-value pairs per function.
- The UI enforces naming rules (alphanumeric characters, underscores, and hyphens).
- A visual indicator tracks usage against the 4KB environment variable size limit.
- Developers can use built-in options to encrypt variables with AWS KMS, selecting region-specific keys.
- JSON import/export makes it easy to reuse environment configurations across multiple functions.
Use case: A healthcare provider running a patient appointment scheduling system on AWS Lambda needs to switch between staging and production API endpoints (e.g., for an EHR system or SMS notification service). Instead of modifying and redeploying the function code, the developer updates the API_URL and FEATURE_TOGGLE_SMS environment variables directly in the AWS Console. This allows the team to change behavior instantly, such as enabling SMS reminders for patients, without code changes or downtime, ensuring faster iteration and reduced operational risk.
2. Using the AWS Command Line Interface (CLI)
The CLI suits engineering teams who manage infrastructure through scripts or version-controlled deployments.
- Environment variables are updated using the update-function-configuration command.
- Only full replacements are allowed. Existing variables are overwritten, not merged.
- Supports configuration via inline input or external JSON files using file://, which helps standardize deployments across stages (e.g., dev, test, prod).
Example:
aws lambda update-function-configuration \
--function-name myFunction \
--environment Variables="{KEY1=value1,KEY2=value2}"
Use case: An SMB operating across development, staging, and production environments, each in separate AWS accounts, needs consistent Lambda configuration for settings like LOG_LEVEL, API_KEY, and REGION_ID. Instead of manually entering these values in each account, the team uses pre-approved JSON files containing environment variable definitions. These files are applied via the AWS CLI or deployment scripts during CI/CD runs, ensuring all environments are configured identically. This approach minimizes human error, speeds up deployments, and maintains compliance with internal governance policies.
3. Using AWS SDKs for automation
For advanced use cases and CI/CD pipelines, the AWS SDKs (e.g., Boto3 for Python, AWS SDK for JavaScript) allow full programmatic control over Lambda environment variables.
- The UpdateFunctionConfiguration API is used to update variables as part of deployment automation.
- SDKs manage authentication, retries, and error handling, reducing the need for custom error logic.
- Teams can build templated variable sets based on client, region, or environment.
Example (Python):
import boto3
lambda_client = boto3.client('lambda')
lambda_client.update_function_configuration(
FunctionName='myFunction',
Environment={'Variables': {'STAGE': 'prod'}}
)
Use case: An SMB software vendor deploying a multi-tenant SaaS solution can use Lambda environment variables to inject client-specific configurations, such as API credentials, feature flags, or tenant identifiers, at deploy time. During CI/CD, the deployment pipeline programmatically updates the Lambda function’s environment based on each customer’s config.
This enables the same Lambda codebase to serve multiple clients securely and efficiently, without hardcoding or redeploying for each tenant. It simplifies onboarding, reduces maintenance, and ensures isolation between customer environments.
These approaches allow SMBs to manage Lambda configurations dynamically, reduce redeployments, and scale operations without introducing complexity. Whether the team prefers a UI-driven approach or automated pipelines, AWS provides flexible tools to meet different operational needs.

Managing AWS Lambda environment variables with the Serverless Framework
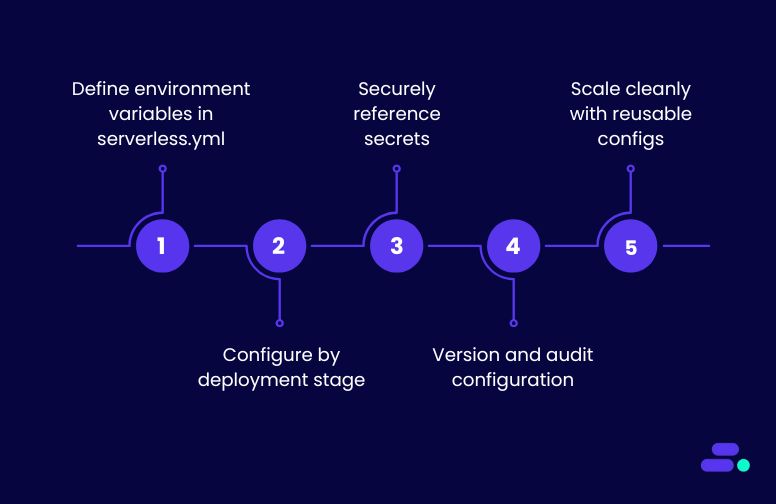
The Serverless Framework enables structured, stage-aware, and secure management of AWS Lambda environment variables using Infrastructure as Code. It allows teams to define, version, and deploy configurations cleanly across environments without embedding secrets in code or relying on manual edits.
Here’s how it works:
1. Define environment variables in serverless.yml
Environment variables can be scoped globally (for all functions) or per function. Variables can be hardcoded, pulled from local .env files, or injected via CI/CD.
provider:
name: aws
environment:
DB_HOST: ${env:DB_HOST}
functions:
myFunction:
environment:
LOG_LEVEL: debug
${env:DB_HOST} pulls values from the machine’s environment or deployment pipeline.
2. Configure by deployment stage
Use the --stage flag to inject different values per environment (e.g., dev, staging, prod). Stage-specific configurations are managed using file overrides or conditional logic.
serverless deploy --stage prod
Businesses can maintain per-stage variable files (env.prod.yml, env.dev.yml) and reference them using the file() directive in serverless.yml.
3. Securely reference secrets
Instead of hardcoding sensitive values, reference AWS Secrets Manager or SSM Parameter Store:
environment:
DB_PASSWORD: ${ssm:/prod/db/password~true}
The ~true flag ensures the value is decrypted. Secrets remain outside version control and are encrypted at rest.
4. Version and audit configuration
Since serverless.yml is part of source control, teams get full version history and rollback capability. This promotes consistent deployments and improves collaboration between dev and ops teams.
5. Scale cleanly with reusable configs
For large projects, use separate serverless.yml files per stage or modularize config using serverless.ts or YAML imports:
custom: ${file(./config.${opt:stage, 'dev'}.yml)}
This keeps configuration DRY while supporting stage-specific overrides.
By using the Serverless Framework, SMBs can manage Lambda environment variables securely, scalably, and with full automation, minimizing misconfigurations and accelerating deployment workflows.

How to secure AWS Lambda environment variables?
When Lambda functions handle sensitive values like database passwords or API tokens, securing environment variables is essential. Misconfiguration can lead to data exposure or compliance violations. AWS offers several tools to help, if used correctly.
1. Encryption with AWS KMS: All Lambda environment variables are encrypted at rest using AWS Key Management Service (KMS). By default, AWS uses its managed keys, but for sensitive workloads, SMBs should use customer-managed keys for better control. This allows teams to define key-specific IAM policies, track usage with CloudTrail, and enforce rotation policies. The KMSKeyArn field in the Lambda configuration lets the teams specify the custom key. No application code changes are required, as decryption is handled during function startup.
2. Storing secrets securely: Avoid embedding sensitive data directly in environment variables. Instead, store secrets in AWS Secrets Manager or Systems Manager Parameter Store. These services support fine-grained access control, logging, and automatic rotation (especially for RDS). Lambda functions can reference these secrets via ARNs in environment variables and retrieve them at runtime using the AWS SDK.
Example:
DATABASE_PASSWORD_SECRET_ARN: arn:aws:secretsmanager:us-east-1:...
3. IAM-based access control: Limit who and what can access secrets or decrypt environment variables. Use least-privilege IAM roles that restrict access to specific secrets or KMS keys. This helps isolate workloads and reduces blast radius in case of compromise. Use tools like IAM Access Analyzer to audit permissions regularly.
Combining encryption, secret management, and tight access control allows SMBs to ensure that Lambda-based applications handle sensitive configuration securely without sacrificing agility.
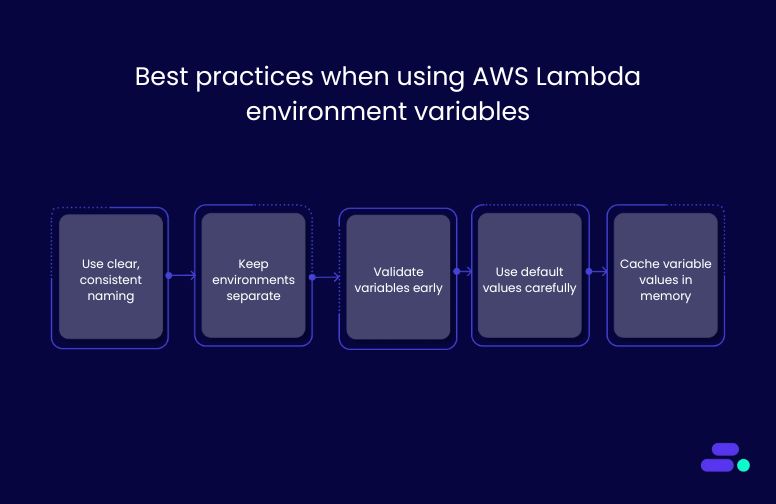
Best practices when using AWS Lambda environment variables
Environment variables in AWS Lambda provide a simple but powerful way to manage configuration without modifying code. By storing key values like database URLs, API keys, feature flags, or timeout settings outside the application logic, teams can run the same code across different environments with varying configurations.
For SMBs running lean teams or managing multiple client deployments, this separation of config from code offers speed and flexibility. There is no need to redeploy just to update a setting. Lambda environment variables are injected during the container’s cold start, made available as part of the runtime’s native environment (e.g., process.env in Node.js or os.environ in Python), and cached throughout the function's lifecycle for consistent performance.
However, poor environment variable practices can lead to runtime errors, security gaps, or debugging headaches. That’s why teams must structure, validate, and scope environment variables thoughtfully. The following best practices ensure the Lambda functions stay secure, scalable, and maintainable as the business and workloads grow.
1. Use clear, consistent naming: Stick to uppercase, underscore-separated names like PAYMENTS_API_KEY or ORDERS_DB_URL. Prefix variables with the service or app name (e.g., ORDERS_DB_URL) to avoid confusion or conflicts in shared environments.
2. Keep environments separate: Don’t mix dev, staging, and prod variables. Use environment-specific names like DB_URL_PROD vs. DB_URL_DEV. This prevents accidental access to production data during testing.
3. Validate variables early: Add startup checks to confirm that all required environment variables are present and correctly formatted. Catching misconfigurations upfront avoids runtime failures and debugging delays.
4. Use default values carefully: Set safe defaults only for non-sensitive settings, like timeouts or feature flags. Never default values like passwords or API keys; always set those explicitly.
5. Cache variable values in memory: Instead of re-reading or re-parsing environment variables on every function call, load them once during initialization. This improves performance and reduces compute costs, especially for high-frequency invocations.
These practices help SMBs build secure, reliable Lambda functions that are easier to scale and maintain.

How Cloudtech helps SMBs implement secure AWS Lambda configuration
Misconfigured environment variables can lead to broken deployments, leaked secrets, and unstable behavior across environments. Cloudtech helps small and mid-sized businesses solve these problems by designing serverless systems that prioritize secure, stage-aware configuration from the start.
Each of Cloudtech’s core services supports this goal:
- Application modernization: Cloudtech transforms monolithic or legacy applications into AWS-native systems where environment variables are managed dynamically. This ensures clean separation between code and configuration, enabling safer deployments and easier multi-environment support without manual rewrites.
- Infrastructure resiliency: Cloudtech’s infrastructure solutions embed best practices for runtime configuration, including encrypted environment variables, stage-specific resource isolation, and consistent IAM scoping. Teams gain better control over what their functions access.
- Data modernization: Cloudtech replaces fragile in-code credentials with centralized secret management using AWS Secrets Manager and Parameter Store. This reduces the risk of exposure, supports key rotation, and integrates cleanly with Lambda environment variable references.
- Generative AI: For teams building AI-powered features on Lambda, Cloudtech helps structure workloads with environment-specific tuning, model versioning, and secure access to APIs or feature flags, all configured safely outside the codebase.
Conclusion
Effective Lambda environment variable management depends on clear naming, strict environment separation, and secure configuration handling. When supported by automation and secret management, these practices reduce errors, improve consistency, and make serverless deployments easier to scale and manage.
For SMBs building on AWS, getting this right is key to long-term stability and efficiency. Cloudtech helps teams implement these best practices through application modernization, infrastructure design, secure data handling, and automation support. Contact us to build safer, more manageable serverless systems.
FAQ’s
1. How do businesses deploy environment variables in Lambda?
Environment variables in AWS Lambda can be deployed using the AWS Management Console, AWS CLI, SDKs, or Infrastructure-as-Code tools. Values are stored as key-value pairs and attached to the function’s configuration during deployment or update processes.
2. Does AWS Lambda encrypt environment variables?
Yes, AWS Lambda encrypts all environment variables at rest using AWS Key Management Service (KMS). Developers can use either AWS-managed keys or customer-managed keys to control access, enable auditing, and support encryption policies required for compliance and data security.
3. How to get environment variables in Lambda Java?
Lambda functions written in Java can access environment variables using System.getenv("VARIABLE_NAME"). These values are available during function initialization and remain accessible throughout the execution lifecycle, allowing developers to configure runtime behavior without modifying or redeploying function code.
4. How do I set environment variables in AWS?
Environment variables can be set in AWS Lambda through the Management Console, AWS CLI, or SDKs. Each method requires defining key-value pairs that meet naming constraints and fit within the total 4KB size limit for all environment variables combined.
5. What is a Lambda execution environment?
The Lambda execution environment is a managed runtime that hosts function code in an isolated container. It includes system libraries, runtime binaries, and environment variables, and it handles code initialization, invocation processing, and resource lifecycle management across cold and warm starts.

Why is cloud migration important for SMBs to achieve sustainable growth?
Small and mid-sized businesses (SMBs) that adopt cloud technologies early grow significantly faster than those that don’t. A study cited by Inc.com found that tech-forward SMBs (all using cloud) grew at a 13% CAGR, compared to just 3% for those who didn’t.
The reason? Cloud migration eliminates large upfront IT costs and unlocks pay-as-you-go flexibility that accelerates growth.
For example, instead of investing in expensive, on-prem CRM software, a growing services firm can adopt a cloud-based CRM like Amazon Connect. They pay only for active usage, scale instantly as new clients join, and integrate customer data across teams in real time. That efficiency frees up capital and time, resources that can be redirected into customer acquisition, new hires, or product innovation.
This article explores why cloud migration is a growth catalyst for small businesses and outlines practical strategies to maximize ROI, agility, and long-term value.
Key takeaways:
- Cloud migration replaces costly upfront IT investments with flexible, pay-as-you-go infrastructure, helping SMBs scale without overcommitting capital.
- Speed and agility improve dramatically as cloud services enable faster development, deployment, and innovation, reducing time to market from months to days.
- Elastic scalability and built-in resilience ensure SMBs can handle demand spikes, maintain uptime, and recover from disruptions without manual effort.
- Access to enterprise-grade technologies like AI, analytics, and automation becomes affordable and manageable, giving SMBs a competitive edge.
- Cloudtech helps SMBs unlock real growth from migration by delivering modern, cost-optimized architectures with hands-on support, training, and measurable outcomes.
10 reasons why cloud migration is critical for SMBs seeking growth
Traditional infrastructure often demands time, capital, and specialized talent to maintain. For lean teams, this creates an operational burden that pulls focus away from innovation, customer experience, and go-to-market speed.
By migrating to the cloud, SMBs offload infrastructure management to providers like AWS, enabling them to redirect internal resources toward high-impact work like launching products, expanding into new markets, or automating internal operations. Modern cloud services like AWS offer built-in scalability, high availability, security, and observability, capabilities once reserved for large enterprises.
This shift empowers SMBs to operate with agility, adopt new technologies quickly, and compete with larger players without being weighed down by legacy constraints. This is one of the many reasons why migrating to the cloud is a smart, growth-focused move for SMBs:
1. Lower upfront costs
For many SMBs, capital constraints are a major barrier to scaling. Traditional IT demands significant upfront investment in servers, storage, and licenses. These are costs incurred before delivering real value. Cloud migration shifts this model by converting capital expenses (CapEx) into operational expenses (OpEx), enabling pay-as-you-go flexibility. This aligns costs with actual usage, allowing businesses to grow without overcommitting financially.
How SMBs reduce upfront costs with the cloud:
- No physical infrastructure needed: Services like Amazon EC2 and S3 replace on-prem hardware with usage-based cloud resources, no servers or data center space required.
- Lower software and support costs: Managed services like RDS and Lambda eliminate licensing fees, reduce maintenance, and minimize IT staffing needs.
- Elastic scaling, no overprovisioning: Tools like Auto Scaling and Aurora adjust resources automatically based on real-time demand, no more capacity guesswork.
Use case: A regional logistics SMB spends over $15,000 annually on on-prem servers, backup hardware, and software licenses for its shipment tracking platform. IT teams are often tied up managing downtime, patches, and hardware upgrades. After migrating to AWS, using Amazon EC2, RDS, S3, and CloudWatch, the company reduces infrastructure costs by over 65% and shifts to predictable, usage-based billing. The savings are reinvested in digital marketing and route optimization R&D, driving a 40% increase in order volume within 12 months.
2. Faster time to market
For growing SMBs, speed is often the biggest competitive advantage. Traditional infrastructure slows down innovation with long procurement cycles, manual setup, and deployment delays. Cloud migration eliminates these blockers by providing instant access to scalable infrastructure and fully managed services. This enables teams to build, test, and launch applications or features quickly, within days instead of months.
How SMBs accelerate time to market with the cloud:
- Instant provisioning of resources: Services like Amazon EC2, AWS Lambda, and Fargate allow developers to spin up compute environments in minutes, with no hardware setup or manual provisioning needed.
- CI/CD automation: Tools such as AWS CodePipeline and CodeDeploy streamline build, test, and deployment pipelines, helping teams ship faster with fewer errors.
- Integrated developer tooling: Services like AWS Amplify and API Gateway simplify backend setup and API management, reducing dev time and complexity.
Use case: A SaaS SMB building a customer support platform struggles to launch new features due to hardware delays and manual deployment processes. After migrating to AWS, the team adopts AWS Lambda for backend logic, Amazon API Gateway for endpoint management, and AWS CodePipeline for automated deployments. New features now roll out in days, not weeks. As a result, the business accelerates its release cycles, rapidly responds to customer feedback, and increases user retention by 25% in under six months.
3. Scalability on demand
For small and mid-sized businesses, unpredictable traffic patterns and seasonal surges can overwhelm fixed infrastructure. Traditional systems force teams to either overprovision (wasting money) or underprepare (risking downtime). Cloud migration solves this by enabling elastic scalability, automatically adjusting resources in real time to match actual demand.
How SMBs scale efficiently with the cloud:
- Elastic compute and storage: Services like Amazon EC2 Auto Scaling and Amazon S3 automatically adjust capacity based on usage, ensuring consistent performance without manual intervention.
- Database scalability: Amazon Aurora and DynamoDB support dynamic scaling, accommodating traffic spikes without performance degradation.
- Load balancing and distribution: Amazon Elastic Load Balancing distributes traffic across resources for high availability during peak times.
Use case: A D2C apparel SMB experiences large traffic spikes during festive sales and influencer-driven campaigns. Previously, their on-prem setup struggled with sudden demand, resulting in slowdowns and missed sales. After migrating to AWS, the business uses Amazon EC2 Auto Scaling, Amazon Aurora, and Elastic Load Balancing. The platform now scales up automatically during peak loads and scales down when traffic drops, reducing costs and improving customer experience. The SMB can now handle 4x normal traffic without downtime, increasing conversion rates by 30%.
4. Better business continuity
Downtime can be devastating for SMBs, causing lost revenue, damaged customer trust, and operational setbacks. Traditional disaster recovery setups often require separate hardware, complex failover systems, and high costs. Cloud migration dramatically improves business continuity by making backup, recovery, and redundancy built-in and easier to manage.
How SMBs strengthen resilience with the cloud:
- Automated backups and point-in-time recovery: Services like Amazon RDS and Amazon DynamoDB offer built-in backup and restore features with minimal configuration.
- Multi-AZ and multi-region architecture: Tools like Amazon S3 and Amazon EC2 support replication across availability zones or regions to maintain uptime even during localized failures.
- Disaster recovery planning made easy: AWS Backup and AWS Elastic Disaster Recovery simplify implementation of failover strategies without managing additional infrastructure.
Use case: A healthcare SMB relies on its patient appointment and billing system to run daily operations. With its on-prem servers, a local power outage once caused a full day of downtime and data reconciliation headaches. After moving to AWS, the business uses Amazon RDS with Multi-AZ deployment, AWS Backup for daily snapshots, and Amazon S3 for secure, durable storage. During a regional disruption, their system automatically fails over with zero data loss and minimal downtime. Patient services remain unaffected, and internal teams now operate with confidence knowing recovery is automated and reliable.
5. Remote work enablement
Enabling remote or hybrid work is no longer optional for SMBs, it’s essential. Traditional office-bound systems make it difficult to access data, collaborate in real time, or scale remote operations securely. Cloud migration removes these limitations by providing anywhere-anytime access to business-critical tools and data.
How SMBs support remote work through the cloud:
- Centralized access to apps and data: Services like Amazon WorkSpaces and Amazon AppStream 2.0 allow secure desktop and application access from any location or device.
- Real-time collaboration tools: Cloud-hosted platforms integrated with Amazon S3 or Amazon RDS ensure all teams operate on up-to-date data, regardless of geography.
- Secure, scalable connectivity: AWS Identity and Access Management (IAM) and AWS Client VPN provide secure access without setting up complex networking infrastructure.
Use case: A mid-sized design agency transitions to a hybrid work model after facing productivity issues with their on-prem project management tools. Post-migration, they deploy Amazon WorkSpaces for designers and Amazon S3 to centralize shared assets. Teams now collaborate from home, client sites, or the office without version conflicts or access issues. IT no longer has to maintain desktop environments, and the company reduces operational friction while improving team satisfaction and client delivery timelines.
6. Access to advanced technologies
Building or maintaining complex infrastructure for AI, machine learning, or real-time analytics requires resources SMBs might not have. However, cloud migration levels the playing field by offering on-demand access to enterprise-grade technologies without the cost or complexity of traditional IT stacks. With AWS, SMBs can innovate faster using tools once reserved for large enterprises.
How SMBs access advanced technologies through the cloud:
- AI/ML without heavy lifting: Services like Amazon SageMaker, Amazon Rekognition, and Amazon Comprehend let SMBs build intelligent features such as recommendations, image tagging, or sentiment analysis without deep AI expertise.
- Real-time insights: Amazon Athena and AWS Glue help SMBs transform raw data into real-time dashboards or reports, accelerating decision-making.
- Business automation: AWS Step Functions and AWS Lambda enable process automation, from notifications to data processing, without building complex backend logic.
Use case: A regional edtech SMB wants to personalize student learning content but lacks the in-house AI team or budget for enterprise tools. After migrating to AWS, they integrate Amazon Personalize to deliver tailored course recommendations and Amazon QuickSight to visualize student performance in real time. The platform sees a 22% increase in student engagement within months without hiring new technical staff or building ML pipelines from scratch.
7. Improved security posture
Security is one of the most critical yet often under-resourced areas for SMBs. Traditional on-prem environments require costly firewalls, patching cycles, and manual monitoring, which many SMBs struggle to maintain. Cloud migration improves security by default, offering access to advanced protection tools and built-in best practices that are continuously updated.
How the cloud strengthens security for SMBs:
- Centralized identity and access control: With AWS Identity and Access Management (IAM), SMBs can enforce least-privilege access, use multi-factor authentication, and define granular user roles across services.
- Automated threat detection: Amazon GuardDuty and AWS CloudTrail offer real-time anomaly detection, logging, and alerting, no need for external security appliances or SIEM systems.
- Encryption made simple: AWS Key Management Service (KMS) allows encryption of data at rest and in transit with minimal setup, ensuring sensitive business data is protected without manual key handling.
Use case: A growing legal-tech SMB handles sensitive client data and is under pressure to meet compliance standards. On-prem setups lacked encryption and visibility. After migrating to AWS, they use IAM to enforce access control, GuardDuty to detect threats, and KMS for data encryption. The company passes its first external security audit with zero findings, enabling it to onboard larger clients and expand into regulated markets.
8. Easier integration with SaaS and APIs
For SMBs, productivity often depends on the ability to connect systems quickly, whether it’s syncing customer data from a CRM or automating billing workflows. Traditional infrastructure makes integration complex, with custom connectors, firewall issues, and manual API management. The cloud changes that by offering seamless, secure connectivity with leading SaaS platforms and APIs.
How the cloud enables easier integrations:
- API-first architecture: AWS services like Amazon API Gateway simplify creating, securing, and managing APIs to connect with tools like Salesforce, HubSpot, or Stripe.
- Event-driven workflows: AWS Lambda and Amazon EventBridge allow real-time triggers based on external events. such as a new support ticket or online payment, without polling or batch jobs.
- Out-of-the-box SaaS compatibility: Cloud-native platforms are built to integrate easily with tools for marketing, finance, HR, and support, helping SMBs eliminate data silos and manual processes.
Use case: A subscription-based education SMB struggles to sync customer data across its billing, support, and learning platforms. After migrating to AWS, it uses Amazon API Gateway to connect its internal database with Stripe for billing and Zendesk for support. Workflows are orchestrated using Lambda and EventBridge, eliminating manual reconciliation and enabling real-time updates across systems. Within six months, the company reduces support overhead by 30% and improves customer satisfaction scores through faster issue resolution.
9. Faster decision-making with data
For SMBs, the ability to make quick, informed decisions can be a major competitive advantage, but traditional analytics often require complex infrastructure and costly BI tools. Cloud migration unlocks access to modern, serverless analytics services that work directly on cloud-stored data, reducing time-to-insight and enabling smarter, faster decision-making.
How the cloud accelerates insights for SMBs:
- Serverless querying: Tools like Amazon Athena let teams run SQL queries directly on data stored in Amazon S3, no ETL or data warehouse setup needed.
- Interactive dashboards: Amazon QuickSight provides real-time dashboards and visualizations without the need for separate BI infrastructure or long setup times.
- Unified data sources: Cloud storage and integration tools consolidate customer, sales, and operational data, giving SMBs a single source of truth for decision-making.
Use case: A mid-sized healthcare provider manages data across EMR systems, call centers, and billing tools, making reporting slow and inconsistent. After migrating datasets to Amazon S3 and implementing Amazon Athena and QuickSight, the provider builds a centralized reporting layer. Business teams now generate on-demand reports to track appointment trends, no-shows, and billing anomalies. As a result, decision-making cycles shrink from weeks to hours, improving patient service delivery and operational planning.
10. Support for long-term innovation
For growth-focused SMBs, the cloud isn’t just about solving today’s problems but a foundation for tomorrow’s opportunities. Whether it's launching new digital products, adopting serverless technologies, or expanding to new regions, cloud infrastructure provides the flexibility and scalability to evolve without major replatforming down the road.
How cloud sets SMBs up for long-term innovation:
- Modern architecture ready: With services like AWS Lambda and Amazon API Gateway, SMBs can gradually adopt serverless models that reduce overhead and speed up feature delivery.
- Future-proof infrastructure: Cloud-native tools and APIs integrate easily with emerging technologies like AI, machine learning, and edge computing.
- Global reach, local performance: With AWS Regions and Availability Zones, SMBs can scale applications globally without needing physical presence in new geographies.
Use case: A software SMB initially moves its core app to Amazon EC2 and Amazon RDS to stabilize performance. Over time, it adopts AWS Lambda for user-facing features like notifications and status updates. Later, it begins using Amazon SageMaker to pilot AI-based recommendations. Without needing to re-architect or migrate again, the company transitions from a basic web app to a smart, globally available SaaS platform, positioned for future growth and innovation.
How does Cloudtech help SMBs realize these cloud gains?
Achieving the full value of cloud migration takes more than moving infrastructure. It requires thoughtful execution, service alignment, and continuous optimization. That’s where Cloudtech, an AWS Advanced Tier Services Partner focused exclusively on SMBs, plays a critical role.
Here’s how Cloudtech helps growth-focused SMBs unlock real outcomes from day one:
- Right-sized architecture from the start: Cloudtech uses tools like AWS Migration Evaluator and Compute Optimizer to design efficient, cost-effective environments, avoiding overprovisioning and reducing upfront infrastructure spend.
- Built-in observability and resilience: With services like AWS CloudWatch, CloudTrail, and AWS Backup, Cloudtech ensures every workload is monitored, secure, and recoverable, which is critical for SMBs with lean ops teams.
- Enablement of modern services without complexity: From Amazon QuickSight for instant reporting to serverless orchestration with AWS Step Functions, Cloudtech equips SMBs to adopt advanced capabilities without needing large internal teams.
Cloudtech’s approach is tested across real SMB environments. Whether it’s reducing infrastructure costs, improving analytics performance, or enabling secure, remote-ready operations, Cloudtech helps clients translate cloud capabilities into measurable outcomes.
One such example is a non-profit healthcare insurance provider that struggled with the cost and complexity of managing its growing on-premises data warehouse. By migrating to Amazon Redshift with Cloudtech’s guidance, the organization streamlined its data pipeline, improved performance on large datasets, and significantly reduced IT overhead. The result was faster data analysis, centralized reporting, and a scalable foundation for future growth. Read more!
Wrapping up
For SMBs, cloud migration is about meeting the conditions required for sustainable, accelerated growth. From reducing upfront costs and enabling remote teams to adopting advanced analytics and scaling with demand, the cloud removes many of the traditional constraints that slow small businesses down.
But the real competitive edge lies not just in using cloud infrastructure, but in how SMBs use it to out-innovate, out-deliver, and out-learn their competitors. Those who treat migration as a one-time project risk missing the bigger opportunity. The most successful SMBs use the move to the cloud as a launchpad, to build smarter systems, move faster, and stay customer-focused even as they scale.
Cloudtech works with these growth-focused SMBs to make that vision real, with modern architectures, practical strategies, and measurable ROI from day one.
If your business is ready to grow faster, the cloud is the fastest way there. Accelerate your growth with Cloudtech!
FAQs
1. How long does a typical cloud migration take for an SMB?
Most SMB cloud migrations take 4–12 weeks, depending on factors like data volume, application complexity, and team readiness. Simple lift-and-shift workloads (e.g., file servers, static websites) can be moved quickly. But migrations involving refactoring apps or modernizing data pipelines take longer.
2. What kind of upfront investment should an SMB expect?
There’s no fixed number, but SMBs often spend 30–60% less on cloud setup compared to upgrading on-prem infrastructure. Costs mainly include discovery tools, initial architecture, training, and AWS usage. Many costs are usage-based, so businesses can start small. AWS credits, free tiers, and funding programs (which Cloudtech can help access) also reduce early-stage expenses.
3. Do businesses need to re-write all applications for the cloud?
Not necessarily. A “lift-and-optimize” strategy works for many SMBs. Some apps can move as-is to Amazon EC2, while others benefit from modernization with Amazon RDS, AWS Lambda, or container services like ECS. Cloudtech helps evaluate which apps to rehost, refactor, or retire based on cost and performance benefits.
4. How does cloud migration improve my data security?
The cloud improves security through built-in tools like AWS Identity and Access Management (IAM), AWS Key Management Service (KMS), and GuardDuty. These offer encryption, threat detection, and granular access control. These features are expensive and complex to build in-house.
5. What happens after the migration is complete?
Post-migration, SMBs enter the optimization phase, including fine-tuning costs, improving performance, and integrating advanced capabilities like monitoring (Amazon CloudWatch), auto-scaling, and analytics (Amazon QuickSight or Athena). Cloudtech continues to support with cost governance, security reviews, and feature rollout, ensuring the cloud delivers long-term value.

Cloud migration ROI: what can SMBs expect in year one?
A regional logistics company migrates its order tracking system to the cloud hoping for quick gains, including faster performance, easier scaling, and lower IT overhead. But six months in, the benefits feel unclear. Some costs go down, others pop up. Teams are still adapting. This might be a true story for many small and mid-sized businesses (SMBs) today.
Cloud migration is a strategic move but the return on that investment (ROI) doesn’t always show up in a straight line. Year one can feel like a balancing act between early wins and foundational setup. That’s normal, but there is a pattern to what works. When done right, SMBs can see meaningful returns like faster deployments, reduced licensing costs, and less time spent firefighting infrastructure issues.
This guide looks at where SMBs typically see ROI within the first 12 months of cloud migration, and what factors move the needle.
Key takeaways:
- The most valuable returns come from improved efficiency, faster product delivery, and better data insights, not just lower infrastructure costs.
- By months 3 to 6, many SMBs see reduced overhead and improved visibility. Value comes from automation, analytics, and operational agility by month 12.
- Services like AWS Athena, Lambda, and Trusted Advisor can significantly enhance performance, reduce waste, and support data-driven decisions.
- SMBs that monitor cost trends, resource usage, and team output using tools like Cost Explorer and CloudWatch are better positioned to optimize and grow.
- Cloudtech helps SMBs avoid common migration issues by delivering clear roadmaps, cost governance, and AWS-aligned architecture.
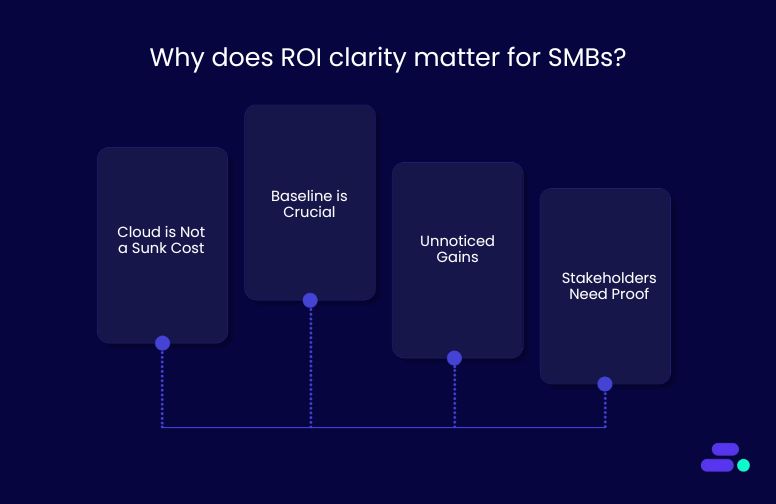
Why does ROI clarity matter for SMBs?
Cloud migration is a strategic investment. But unlike one-time infrastructure purchases, the ROI isn’t always immediately clear. Many SMBs move to the cloud with the expectation of faster performance, lower costs, or better scalability, only to find it hard to prove those benefits internally.
Without a clear framework for tracking ROI, it becomes difficult to validate the effort, justify future investments, or pinpoint what’s working and what’s not.
Here’s why getting ROI clarity in year one matters:
- Cloud is not a sunk cost: Businesses are not just spending on infrastructure. They’re investing in agility, security, and long-term growth. ROI should reflect operational impact, not just technical metrics.
- Having a baseline is important: Many teams skip defining clear pre-migration metrics (e.g., downtime hours, support tickets, time-to-deploy), which makes it harder to compare gains post-migration.
- Untracked gains often go unnoticed: Savings in developer time, faster release cycles, reduced maintenance overhead, or uptime improvements are real but easily overlooked without intentional tracking.
- Stakeholders need proof: For SMB leaders managing tight budgets, ROI clarity builds confidence, aligns teams, and strengthens the case for ongoing modernization.
With the right tools and tracking in place, the first 12 months post-migration can provide a clear picture of value delivered, setting the stage for even greater returns in year two and beyond.
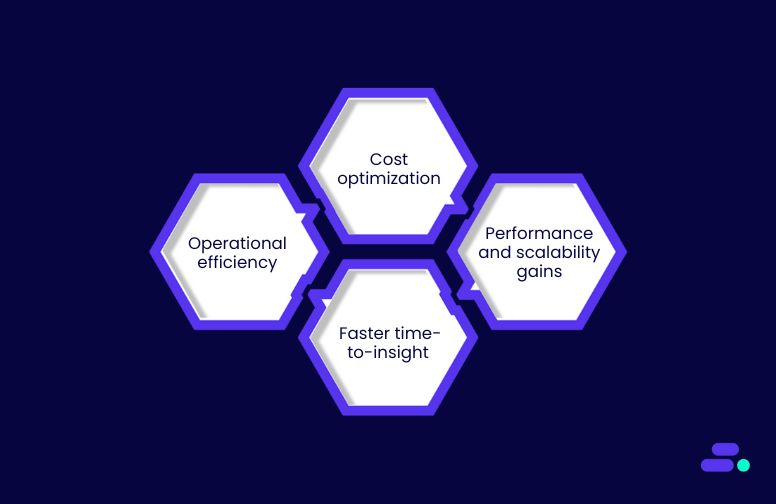
Where does cloud ROI come from and how to measure it?
For SMBs, the return on cloud investment shows up across four key areas, each measurable with the right AWS tools and tracking discipline. Clarity here helps teams identify what’s working, justify costs, and optimize faster.
1. Operational efficiency
Cloud-native services reduce the overhead of managing infrastructure, freeing up teams to focus on innovation instead of maintenance.
- CI/CD pipelines deployed via AWS CodePipeline or GitHub Actions allow faster, automated deployments, cutting release times from days to minutes.
- Serverless architectures (like AWS Lambda and Step Functions) simplify backend logic, eliminating the need to manage EC2-based app servers.
Example: A healthcare SMB replaces batch-based reporting with AWS Athena queries on Amazon S3 data, reducing patient analytics turnaround from hours to minutes.
2. Cost optimization
Cloud spending is dynamic, but with visibility and good architecture, SMBs can reduce waste and shift from fixed costs to pay-as-you-go models.
- Auto-scaling groups and EC2 Spot Instances help scale workloads efficiently, especially for dev/test or stateless jobs.
- AWS Lambda and Fargate remove the need to pay for idle compute.
- Use AWS Cost Explorer to visualize spend trends, and AWS Compute Optimizer to right-size EC2 and EBS resources.
- OpEx flexibility also helps SMBs avoid large CapEx purchases, improving cash flow and budget agility.
3. Performance and scalability gains
Unlike on-prem hardware, cloud enables SMBs to scale based on demand, not prediction.
- Elastic Load Balancing and Auto Scaling allow web apps to handle spikes without degraded performance.
- Amazon CloudFront improves global latency with edge caching.
- Multi-AZ deployments and Amazon RDS read replicas ensure availability and responsiveness at scale.
4. Faster time-to-insight
SMBs using AWS data services gain quicker access to decision-making.
- Amazon Athena enables SQL queries directly on Amazon S3, removing the need for traditional ETL pipelines.
- Amazon Redshift provides high-performance analytics for structured data warehouses.
- QuickSight helps visualize these insights, making dashboards accessible even to non-technical users.
Bottom line: AWS provides both the tools and architecture patterns to quantify cloud ROI across performance, cost, and time. SMBs that align their goals with these levers tend to see measurable returns within the first 12 months.
Sample ROI metrics to track:
What realistic ROI looks like in the first year?

SMBs entering the cloud face pressure to show ROI quickly, but it’s important to understand how value unfolds across the first 12 months. Returns aren’t always immediate, but with the right AWS tools and governance, compounding gains emerge in automation, agility, and insight.
Months 1–3: Setup costs and learning curve
The first phase of cloud migration is often the most resource-intensive, as SMBs lay the groundwork for long-term value. Costs during this period span not just infrastructure, but skills development, governance setup, and workload re-architecture.
Initial investment areas:
- Training and enablement: Teams require upskilling in cloud-native concepts like shared responsibility, identity and access control, and serverless computing. Training platforms (e.g., AWS Skill Builder or third-party labs) help close skill gaps.
- Discovery and planning tools: Tools like AWS Application Discovery Service or Migration Evaluator are used to inventory existing systems, map interdependencies, and assess readiness. This reduces rework later by avoiding overlooked components during migration.
Foundational architecture work:
- Environment setup: Organizations establish core services like cloud networking (VPCs, subnets, NAT gateways), IAM roles and policies, and S3 buckets for backup and storage. Multi-account strategies are often implemented using AWS Organizations or Control Tower.
- Workload replatforming or rehosting: Teams begin lifting and shifting VMs to cloud compute (e.g., Amazon EC2 or Lightsail), or refactor apps to use managed services like Amazon RDS (for databases), Amazon ECS/Fargate (for containers), or AWS Lambda (for serverless).
Early wins and quick reductions:
- Retiring physical infrastructure reduces power, cooling, maintenance, and hardware refresh cycles. SMBs can decommission old on-prem file servers and run scalable file shares using Amazon FSx or EFS.
- Replacing manual processes with cloud-native operations. AWS Backup automates snapshot management. Amazon CloudWatch enables centralized logging and alarms. IAM roles replace legacy credential-sharing and manual access control.
While costs may initially rise due to training, dual-running infrastructure, or consulting engagements, this period builds the foundation for long-term efficiency, observability, and agility, especially when SMBs take advantage of AWS’s modular, pay-as-you-go model.
Months 4–6: Cost normalization and visibility
As SMBs move beyond initial setup, the cloud environment begins to stabilize, making it easier to understand actual usage, identify inefficiencies, and align spend with business value. This stage is all about turning raw cloud usage into actionable insights.
Visibility tools:
- AWS Cost Explorer: Visualizes cost and usage data by service, linked account, or custom tags (e.g., team, workload, environment). It helps SMBs detect unexpected cost spikes and analyze trends.
- AWS Budgets: Enables teams to define budget thresholds and receive alerts when usage exceeds targets. SMBs can set monthly or service-specific budgets to keep teams accountable.
- AWS Trusted Advisor: Performs real-time checks across cost, performance, fault tolerance, and security. SMBs benefit from its cost optimization recommendations, such as idle load balancers, unattached EBS volumes, and overprovisioned EC2 instances.
Optimization in practice:
- Rightsizing compute: Use AWS Compute Optimizer to analyze historical utilization and suggest better-suited instance types or Auto Scaling policies.
- Storage efficiency: Transition infrequently accessed data to S3 Intelligent-Tiering, which automatically shifts objects between storage tiers based on usage patterns.
- Instance modernization: Move workloads to Graviton-based EC2 instances (e.g., t4g, m7g), which offer up to 40% better price/performance for many general-purpose workloads.
Outcome: By Month 6, most SMBs are no longer flying blind. They’ve set up tagging strategies, implemented monitoring dashboards, and begun reclaiming spend from unused or inefficient resources. This marks the start of continuous optimization, where every dollar is tracked and justified, and infrastructure begins aligning tightly with business outcomes.
Months 7–12: Compounding benefits
As SMBs settle into cloud operations, the real return on investment begins to emerge, not just through cost savings, but via smarter automation, improved performance, and faster insights. This stage is where strategic benefits compound.
Automation and observability:
- Infrastructure as Code (IaC): SMBs adopt tools like AWS CloudFormation or Terraform to automate infrastructure provisioning across environments. This reduces human error and accelerates new deployments.
- Real-time visibility: AWS CloudTrail records every API call and user action across AWS accounts. Amazon CloudWatch Logs and Metrics enable centralized log management, alerting, and dashboards, key for performance tuning and issue resolution.
Performance gains:
- Auto Scaling dynamically adjusts EC2 capacity based on load, preventing overprovisioning while maintaining availability.
- Elastic Load Balancing (ELB) distributes traffic efficiently, reducing response times during traffic spikes.
These services help SMBs deliver consistent user experiences and absorb seasonal or unpredictable demand without manual scaling.
Data-driven agility:
- Amazon Athena allows teams to run SQL queries directly on raw data in Amazon S3 without needing ETL pipelines.
- AWS Glue powers schema discovery and ETL preparation across datasets.
- Amazon QuickSight provides dashboards for non-technical teams to explore trends and KPIs.
This serverless analytics stack enables cross-functional insights (e.g., marketing, sales, ops) without building a dedicated data platform.
Example: A mid-sized retail business integrated Athena with their Amazon S3-based customer activity logs to track product interest during live campaigns. Within 2 quarters, they improved campaign ROI by 28% by reacting to customer behavior in real time.
SMBs often enter the cloud expecting savings alone, but long-term ROI is driven by smarter operations, faster delivery cycles, and data-informed decisions. By month 12, the most successful cloud transitions show not just reduced costs, but improved agility, security, and time-to-market.
How does Cloudtech help SMBs maximize cloud ROI?
For SMBs, cloud ROI is about building the right foundation for faster innovation, lower operational burden, and long-term business agility. Cloudtech brings a structured, AWS-native approach to help SMBs realize measurable returns from day one.
- ROI-centered planning: Cloudtech starts with a discovery-led assessment using tools like AWS Migration Evaluator and Application Discovery Service to identify the workloads that deliver the most value when moved.
- Right-sized, optimized architectures: Cloudtech doesn’t just lift and shift. It aligns every workload with the best-fit AWS services (e.g., Graviton EC2, Lambda, S3 Intelligent-Tiering) to improve performance and cost-efficiency.
- Full cost and performance visibility: From day one, Cloudtech sets up AWS Cost Explorer, Budgets, and CloudWatch dashboards to give SMBs real-time insights into spend, usage, and performance.
- Enablement for continuous value: Beyond migration, Cloudtech helps SMBs unlock ongoing ROI by implementing analytics (e.g., Athena, QuickSight) and automation tools (e.g., EventBridge, CloudFormation) that reduce manual work and speed up decision-making.
With Cloudtech, SMBs accelerate value, reduce long-term overhead, and build cloud environments that evolve with their business.
Wrapping up
For SMBs, the first year after cloud migration sets the tone for everything that follows. It’s when budgets tighten, expectations rise, and leadership looks for proof that the move was worth it. That proof doesn’t come from infrastructure alone. It comes from measurable outcomes: faster delivery cycles, clearer cost controls, more responsive operations.
Getting there takes more than just tools. It takes knowing what to optimize, when to modernize, and how to align technology choices with real business goals.
That’s where Cloudtech helps SMBs stand out. As an AWS Advanced Tier Partner with deep SMB experience, Cloudtech equips teams with a phased, ROI-driven roadmap, from early discovery to post-migration tuning. Whether it's streamlining Amazon EC2 usage, automating reporting with Athena, or enforcing budget guardrails, Cloudtech helps ensure the first 12 months deliver real, lasting value.
Ready to make cloud investment count? Let Cloudtech help you turn momentum into measurable ROI. Connect with Cloudtech.
FAQs
1. How soon should businesses expect to see ROI after migrating to AWS?
Most SMBs begin seeing measurable gains between months 4–6, typically in reduced infrastructure costs and improved team productivity. Deeper returns (like automation and analytics-driven decisions) often emerge by months 7–12.
2. What are the biggest drivers of ROI in cloud migration for SMBs?
Key levers include reduced hardware and licensing costs, faster deployments via CI/CD, improved uptime, and faster access to decision-ready data through services like Amazon Athena and Redshift.
3. Does rehosting (lift-and-shift) offer ROI, or do businesses need to modernize?
Lift-and-shift offers short-term gains like hardware savings and basic elasticity. But longer-term ROI often comes from re-architecting parts of the stack using serverless (Lambda), managed databases, or analytics tools.
4. How can businesses make sure they don’t overspend after migrating?
Using tools like AWS Budgets, Cost Explorer, and Trusted Advisor helps track spend and optimize resources. SMBs should also enforce tagging, monitor idle assets, and rightsize instances regularly.
5. How does Cloudtech help improve ROI post-migration?
Cloudtech helps SMBs go beyond just migrating by aligning infrastructure choices with business goals, enforcing governance from day one, and unlocking value through automation, data insights, and cost optimization strategies.
.png)
A detailed breakdown of the Amazon Textract pricing
Small and mid-sized businesses (SMBs) use Amazon Textract to automate data extraction from invoices, receipts, medical forms, and other scanned documents. By replacing manual data entry with intelligent OCR, Amazon Textract allows SMBs to improve accuracy, speed up operations, and reduce overhead.
As adoption grows, understanding Amazon Textract pricing becomes essential for budgeting and scaling document automation workflows efficiently.
This article outlines Amazon Textract pricing, explains the structure of each available feature, and offers usage insights to help businesses make informed decisions about document automation on AWS.
Key Takeaways
- Amazon Textract uses a pay-as-you-go model with per-page rates that vary by feature and region, making it flexible for businesses of any size or document volume.
- A free tier is available for new customers for the first three months, covering a set number of pages for each API, which helps businesses test and plan before incurring costs.
- Pricing drops for high-volume processing: After the first 1 million pages (or 100,000 for identity documents), per-page rates decrease, offering cost savings for large-scale projects.
- Businesses can monitor usage and control costs using AWS tools like Amazon CloudWatch and estimate expenses in advance with the AWS Pricing Calculator.
What is Amazon Textract?
Amazon Textract is a machine learning service from AWS that automatically extracts printed text, handwriting, layout elements, and data from scanned documents. The service is designed to help businesses automate the process of extracting information from a wide range of document types, including forms, tables, and unstructured documents.
The service charges on a per-page basis, with rates that vary by feature and region, making it accessible for businesses with fluctuating document volumes.
The following features highlight how the service addresses the requirements for accuracy, scale, and security.
- Automatic extraction of text and data: Amazon Textract can extract printed text, handwritten text, and structured data, such as tables and forms, from virtually any document. This capability allows businesses to process documents without manual data entry.
- Layout and context preservation: The service maintains the original context and layout of the extracted data, which is important for understanding relationships between different pieces of information within a document.
- Scalability for changing business needs: Amazon Textract enables businesses to scale their document processing pipelines up or down based on demand. This flexibility supports both small-scale and large-scale document processing requirements.
- Security and compliance: Data processed by Amazon Textract is protected by encryption and privacy controls. The service is built to meet various compliance standards, making it suitable for industries with strict regulatory requirements.
Why should businesses choose Amazon Textract?
Amazon Textract offers a flexible and feature-rich solution that adapts to diverse business document processing needs. Its pricing model and comprehensive application programming interfaces provide businesses with control, precision, and scalability.
- Pay only for what businesses use: No minimum fees or upfront commitments. Charges are based on the number of pages and features used (like text, tables, forms, queries, or signatures), making costs predictable and scalable for any business size.
- Automates manual work: Extracts printed text, handwriting, tables, forms, and signatures, reducing manual data entry, speeding up processes, and minimizing errors.
- Works with all kinds of documents: Handles invoices, receipts, contracts, identity documents, loan papers, and more. Adapts to different layouts and formats, so businesses can process almost any document type.
- Easy to integrate: Simple APIs let businesses add Textract to their existing apps and workflows. Works smoothly with other AWS services for end-to-end automation.
- Scales with their business: Processes a few pages or millions per month, no need to manage infrastructure. Grows with their business needs.
- High accuracy: Uses advanced machine learning for reliable extraction of key information, even from complex or handwritten documents.
- Secure and compliant: Built-in security, encryption, and compliance standards protect their data.
- Flexible features: Choose from APIs for basic text extraction, forms, tables, queries, signatures, expenses, identity docs, and lending documents, and use only what they need.
Many businesses want to understand what Amazon Textract offers before making any financial commitments; this is where the free tier options provide a risk-free way to test key features and see how Textract fits into their workflows.
What are the free tier options in Amazon Textract?
The Amazon Textract free tier is designed to help new AWS customers test and prototype document extraction features without upfront costs. For the first 3 months after account creation, businesses can process a set number of pages each month for free, depending on the type of document task they need.
This lets teams explore Textract’s capabilities and see how it fits into their workflows before committing to paid usage.
What’s not included?
- The free tier does not cover custom queries in the Analyze Document API.
- Layout extraction is only free when used with the tables feature.
If the free tier feels too basic or limited, it’s worth checking out the full pricing options to find what fits a business’s specific needs and scale.
What are the pricing details for Amazon Textract?
Textract’s pricing is usage-based, meaning businesses only pay for the features they actually use, and there’s no minimum spend or upfront commitment.
This is especially useful for businesses that want to start small, scale up later, or handle unpredictable volumes without locking into long-term contracts.
Pretrained features pricing
When a business is evaluating Amazon Textract, the pretrained features pricing table is the first thing to check. This is where businesses see exactly what they’ll pay for the most common document processing tasks, like extracting text, tables, forms, or running queries, based on how many pages the business processes.
Here's a side-by-side look at the costs for each feature, so businesses can quickly estimate their monthly spend and compare options as their document volume grows.
*Pricing is based on the number of pages processed, where each “page” refers to a single document page submitted through Textract’s API for analysis.
*The layout feature is included free with any combination of Forms, Tables, and Queries.
*Signatures are included free with any combination of Forms, Tables, Queries, and Layout.
Pretrained + customized features pricing
For businesses with unique document types or specific data extraction needs, Amazon Textract offers custom query features on top of its standard APIs. Here’s exactly what it costs to use those advanced, customized features, so businesses can budget for specialized automation and know what to expect as their usage grows.
Note: Training of adapters for Custom Queries is free.
How does Amazon Textract pricing matter to businesses?
Here’s what these pricing details actually mean for businesses considering Amazon Textract:
- Cost control: Businesses only pay for the features and volume they use, with no minimum fees or upfront costs.
- Bundled discounts: Combining features (like forms plus tables plus queries) is more cost-effective than purchasing separately.
- Volume savings: Processing more pages unlocks lower per-page rates, especially for large-scale automation.
- Feature clarity: Knowing which features are bundled or included (like OCR, layout, or signatures) helps avoid unnecessary charges.
Businesses should review their document processing needs and select the feature set that matches their workflow. Timing large projects to cross volume thresholds within a billing cycle can further reduce costs. For identity documents, significant savings start after 100,000 pages, while OCR-only projects see price drops after one million pages.
In summary, Amazon Textract’s pricing model is transparent and flexible, making it easier for businesses to budget and scale document automation as their needs grow.
If the pricing details still leave some questions, it can help to see how other businesses are actually using Textract and what kinds of results they’re seeing in practice.
Cloudtech AWS expertise for Amazon Textract success
Many organizations need expert guidance to set up secure, scalable, and cost-effective solutions that match their specific requirements.
This is where Cloudtech steps in, as an AWS Advanced Consulting Partner, helps businesses get the most out of Amazon Textract by designing secure, scalable solutions that fit each business's specific document processing needs, making it easier to automate workflows and achieve measurable results.
- Cloud strategy and adoption: Cloudtech assesses a business's current information technology landscape and creates a custom AWS adoption roadmap, guiding businesses through migration from on-premises or hybrid environments to the cloud.
- Data engineering and analytics: Cloudtech migrates and modernizes data architectures to AWS data lakes and warehouses, and uses analytics services like Amazon Redshift, Glue, and Athena to deliver actionable business insights.
- DevOps and automation: Cloudtech sets up continuous integration and continuous deployment pipelines, automates cloud deployments, and manages security policies and compliance tracking to support rapid and secure development cycles.
- Security and governance: Cloudtech implements strong identity and access management, monitors environments with services such as AWS CloudTrail and Amazon CloudWatch, and enforces governance using AWS Control Tower and Config.
- Cost optimization and cloud management: Cloudtech helps right-size resources, manage reserved instances, and use cost visibility tools like AWS Cost Explorer. Ongoing monitoring and support are provided to prevent cloud sprawl and control spending.
- Ongoing support and innovation: Cloudtech delivers managed cloud services, technical support, and strategic consulting. The team assists with integrating new AWS offerings, including artificial intelligence and machine learning, container orchestration, and serverless computing.
Cloudtech’s expertise empowers businesses to fully realize the benefits of Amazon Textract and other AWS solutions, supporting secure, modern, and cost-effective cloud adoption.

Conclusion
Businesses now have a clear view of how Amazon Textract pricing works, from the way features are billed to the factors that influence costs across regions and document types. With this information, decision-makers can forecast expenses, select the right features for their needs, and avoid common billing surprises. Understanding these details supports better planning for document automation projects and helps businesses capture the value of machine learning-driven extraction on AWS.
For businesses that want to take the next step with Amazon Textract or require support with broader cloud adoption, Cloudtech delivers the expertise needed for secure migrations, application modernization, and ongoing cloud management.
Cloudtech’s experience with AWS ensures businesses can deploy, scale, and manage document automation and other cloud solutions with confidence. Get started with us!
FAQs about Amazon Textract pricing
1. How does Amazon Textract pricing work when combining multiple features on a single page?
When using the Analyze Document API, if businesses select multiple features (such as Forms, Tables, Queries, or Signatures) for the same page, each feature’s per-page fee is charged separately and added together. For example, using both Forms and Tables on one page results in a combined charge for that page.
2. Are there additional costs beyond per-page processing fees?
Yes, standard Amazon Simple Storage Service (S3), Amazon Simple Notification Service (SNS), and Amazon Simple Queue Service (SQS) fees apply if businesses use these services to store documents, receive job completion notifications, or manage asynchronous operations. These costs are separate from Amazon Textract’s per-page pricing.
3. How long are asynchronous job results retained, and does this affect pricing?
Asynchronous job outputs are retained in Amazon Textract’s managed Amazon Simple Storage Service bucket for seven days. After this period, results are deleted. If businesses need to keep the results longer, they must copy them to their own storage, which may incur additional Amazon Simple Storage Service charges.
4. Does Amazon Textract pricing vary by region?
Yes, pricing can differ across AWS regions. For example, rates in GovCloud and certain international regions can be 10–20 percent higher than standard United States regions. Always check the pricing page for their specific region.
5. What happens if a document processing request fails?
Amazon Textract only charges for successfully processed pages. If a request fails and no data is extracted, businesses are not billed for those pages.
.png)
How to get started with AWS Glue: a complete guide
Disjointed systems, manual data prep, and inconsistent pipelines continue to delay insights across many mid-sized and enterprise businesses. As data volumes scale and regulatory demands intensify, traditional extract, transform, load (ETL) tools often fall short, adding complexity rather than clarity.
AWS Glue addresses this need with a fully managed ETL service that simplifies data integration across Amazon RDS, Amazon S3, and other structured or semi-structured data sources. It enables teams to automate transformation workflows, enforce governance, and scale operations without manually provisioning infrastructure.
This guide outlines the core concepts, architectural components, and practical implementation strategies required to build production-grade ETL pipelines using AWS Glue. From job orchestration to cost monitoring, it provides a valuable foundation for building, optimizing, and scaling AWS Glue pipelines across modern data ecosystems.
Key takeaways
- Serverless ETL at scale: AWS Glue eliminates infrastructure management and auto-scales based on data volume and job complexity.
- Built-in cost control: Pay-per-use pricing, Flex jobs, and DPU right-sizing help teams stay within budget without sacrificing speed.
- Governance for regulated industries: Features such as column-level access, lineage tracking, and Lake Formation integration support compliance-intensive workflows.
- Smooth AWS integration: Native connectivity with Amazon S3, Redshift, RDS, and more enables unified analytics across the stack.
- Faster delivery with Cloudtech: Cloudtech designs AWS Glue pipelines that are secure, cost-efficient, and aligned with industry-specific demands.
What is AWS Glue?
AWS Glue is a serverless ETL service that automates data discovery, transformation, and loading across enterprise systems. It scales compute resources automatically and supports both visual interfaces and custom Python for configuring workflows.
Glue handles various data formats (Parquet, ORC, CSV, JSON, Avro) stored in Amazon S3 or traditional databases. It infers schemas and builds searchable metadata catalogs, enabling unified access to information. Finance teams can pull reports while operations teams access real-time metrics from the same datasets.
For security, AWS Glue integrates with AWS Identity and Access Management (IAM) for fine-grained access control, supports column-level security, Virtual Private Cloud (VPC)-based network isolation, and encryption both at rest and in transit. This ensures secure handling of sensitive business data.
Key functions of AWS Glue
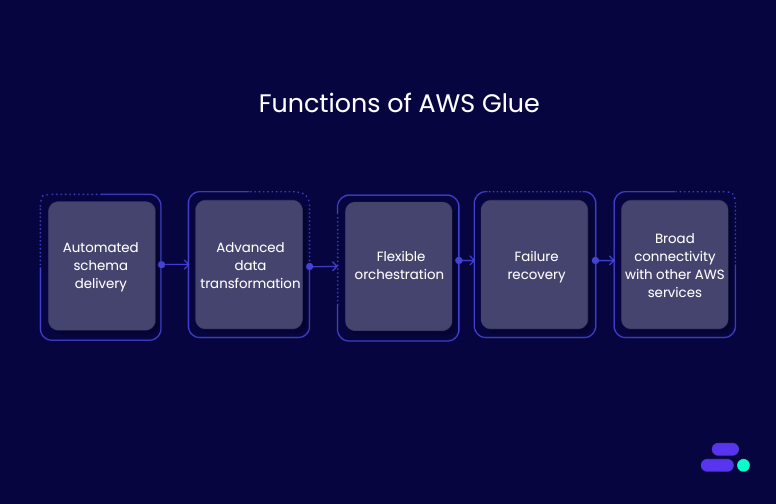
AWS Glue simplifies the ETL process with built-in automation and scalable data handling. Below are its key functions that support efficient data integration across modern cloud environments.
- Automated schema discovery: AWS Glue crawlers analyze new and existing data sources, such as databases, file systems, and data lakes, to detect table structures, column types, and relationships. This eliminates the need for manual schema definition, reducing setup time across ingestion pipelines.
- Advanced data transformation engine: Powered by Apache Spark, AWS Glue’s transformation layer handles complex logic, including multi-table joins, window functions, filtering, and format reshaping. Developers apply custom business logic at scale without building infrastructure from scratch.
- Flexible job orchestration: AWS Glue manages ETL job execution through a combination of time-based schedules, event triggers, and dependency chains. This orchestration ensures workflows run in the correct sequence and datasets remain synchronized across distributed systems.
- Built-in monitoring and failure recovery: Execution logs and metrics are automatically published to Amazon CloudWatch, supporting detailed performance tracking. Jobs include retry logic and failure isolation, helping teams debug efficiently and maintain pipeline continuity.
- Broad connectivity across enterprise systems: Out-of-the-box connectors enable integration with over 80 data sources, including Amazon RDS, Amazon Redshift, Amazon DynamoDB, and widely used third-party platforms, supporting centralized analytics across hybrid environments.
What are the core components of AWS Glue ETL?
Efficient ETL design with AWS Glue starts with understanding its key components. Each part is responsible for tasks like schema discovery, data transformation, and workflow orchestration, all running on fully managed serverless infrastructure.
1. AWS Glue console management interface
The AWS Glue console is the centralized control hub for all ETL activities. Data engineers use it to define ETL jobs, manage data sources, configure triggers, and monitor executions. It provides both visual tools and script editors, enabling rapid job development and debugging.
Integrated with AWS Secrets Manager and Amazon Virtual Private Cloud (VPC), the console facilitates secure credential handling and network isolation. It also displays detailed operational metrics, such as job run duration, processed data volume, and error rates, to help teams fine-tune their performance and troubleshoot issues in real-time. Role-based access controls ensure that users only see and modify information within their designated responsibilities.
2. Job scheduling and automation system
AWS Glue automates job execution through an event-driven and schedule-based trigger system. Engineers can configure ETL workflows to run on fixed intervals using cron expressions, initiate on-demand runs, or trigger jobs based on events from Amazon EventBridge.
This orchestration layer supports complex dependency chains, for instance, ensuring one ETL task begins only after the successful completion of another. All job runs are tracked in a detailed execution history, complete with success and failure logs, as well as integrated notifications via Amazon Simple Notification Service (SNS). These capabilities enable businesses to maintain reliable and repeatable ETL cycles across departments.
3. Script development and connection management
AWS Glue offers automatic script generation in Python or Scala based on visual job designs while also supporting custom code for specialized logic. Its built-in development environment includes syntax highlighting, auto-completion, real-time previews, and debugging support. Version control is integrated to maintain a complete change history and enable rollbacks when needed.
On the connection front, AWS Glue centralizes access to databases and storage layers. It securely stores connection strings, tokens, and certificates, with support for rotation, allowing for updates without service disruption. Through connection pooling, AWS Glue minimizes latency and reduces overhead by reusing sessions for parallel job runs. Combined, these scripting and connection features give developers control without compromising speed or security.
4. ETL engine and automated discovery crawler
At the heart of AWS Glue lies a scalable ETL engine based on Apache Spark. It automatically provisions compute resources based on workload size and complexity, allowing large jobs to run efficiently without manual tuning. During low-load periods, the system downscales to avoid over-provisioning, keeping costs predictable.
AWS Glue Crawlers are designed to discover new datasets and evolving schemas automatically. They scan Amazon S3 buckets and supported data stores to infer structure, detect schema drift, and update the AWS Glue Data Catalog. Crawlers can be configured on intervals or triggered by events, ensuring metadata remains current with minimal manual overhead.
5. Centralized metadata catalog repository
The AWS Glue Data Catalog is a central metadata store that organizes information about all datasets across the organization. It houses table schemas, column types, partition keys, and lineage information to support traceability, governance, and analytics.
This catalog integrates seamlessly with services such as Amazon Athena, Amazon Redshift Spectrum, and Amazon EMR, enabling users to run SQL queries on structured and semi-structured data without duplication. Tags, classifications, and column-level lineage annotations further support data sensitivity management and audit readiness. The catalog also enables fine-grained access control via AWS Lake Formation, making it essential for securing and compliant data operations.
How to use AWS Glue for enterprise ETL implementation
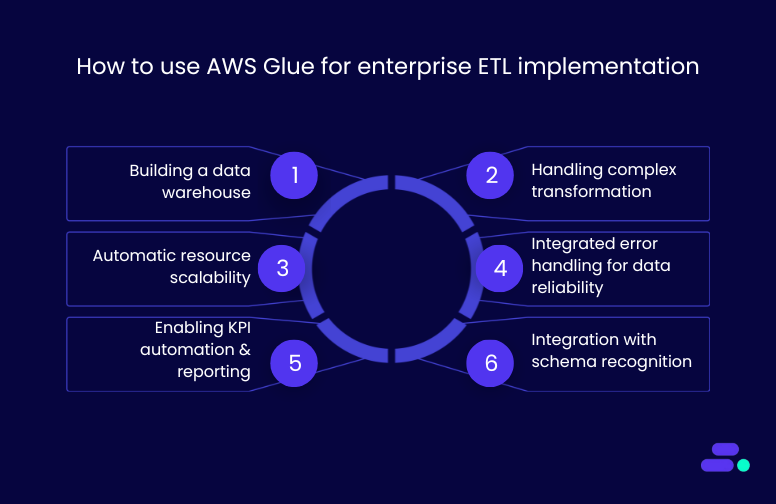
AWS Glue supports end-to-end ETL pipelines that serve analytics, reporting, and operational intelligence needs across complex data ecosystems. Here’s how businesses use it in practice.
- Building enterprise-class data warehouses: Businesses extract data from ERP, CRM, and financial systems, transforming it into standardized formats for analytics. AWS Glue supports schema standardization, historical data preservation, and business rule enforcement across all sources.
- Handling complex transformation scenarios: The ETL engine manages slowly changing dimensions, aggregated fact tables, and diverse file types, from relational records to JSON logs. Data quality checks are applied across the pipeline to ensure compliance and analytics precision.
- Automatic resource scaling and performance tuning: AWS Glue provisions resources dynamically during high-load periods and scales down in low-activity windows. This reduces operational overhead and controls costs without manual intervention.
- Integrated error handling for data reliability: Failed records are handled with retry logic and routed to dead-letter queues. This ensures that mission-critical data is processed reliably, even in the event of intermittent network or system errors.
- Enabling KPI automation and reporting: AWS Glue enables the calculation of real-time metrics and updates dashboards. Businesses compute complex KPIs, such as lifetime value, turnover ratios, and operational performance, directly from ETL pipelines.
- Accelerating integration with schema recognition: When new systems are added, AWS Glue Crawlers automatically detect schemas and update the Data Catalog. This speeds up integration timelines and supports cross-team metadata governance.
How to optimize AWS Glue performance?
Maximizing AWS Glue efficiency requires systematic optimization approaches that balance performance requirements with cost considerations. Businesses should implement advanced optimization strategies to achieve optimal processing speed while controlling operational expenses and maintaining data quality standards.
- Data partitioning optimization: Implement strategic partitioning by date ranges, geographical regions, or business units to minimize data movement and improve query performance, reducing data scan volumes during transformation operations
- Connection pooling configuration: Maintain persistent database connections to operational systems, eliminating connection establishment delays and optimizing resource utilization across concurrent job executions
- Memory allocation tuning: Configure optimal memory settings based on data volume analysis and transformation complexity to balance processing performance with cost-efficiency requirements
- Parallel processing configuration: Distribute workloads across multiple processing nodes to maximize throughput while avoiding resource contention and bottlenecks during peak processing periods
- Job scheduling optimization: Coordinate ETL execution timing to minimize resource conflicts and take advantage of off-peak pricing while ensuring data availability meets business requirements
- Resource right-sizing strategies: Monitor processing metrics to determine optimal Data Processing Unit (DPU) allocation for different workload types and data volumes
- Error handling refinement: Implement intelligent retry logic and dead letter queue management to handle transient failures efficiently while maintaining data integrity
- Output format optimization: Select appropriate file formats, such as Parquet or OR, C, for downstream processing to improve query performance and reduce storage costs
After implementing performance optimization strategies, businesses should assess the broader strengths and trade-offs of AWS Glue to guide informed adoption decisions.
What are the data transformation processes in AWS Glue?
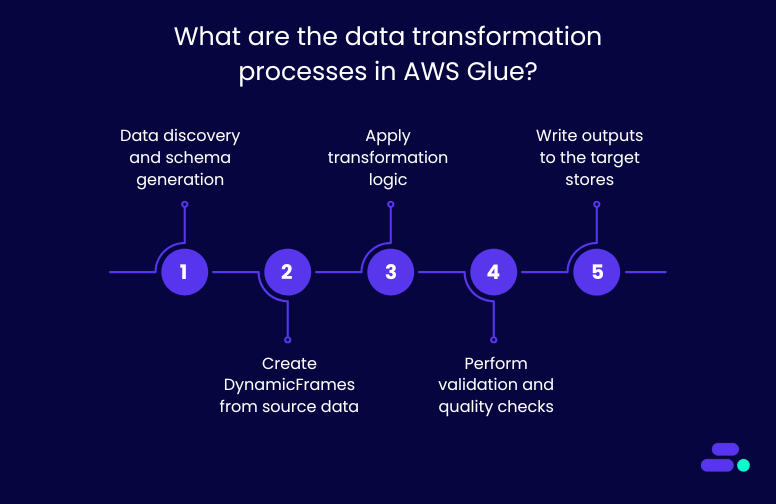
AWS Glue transformations follow a structured flow, from raw data ingestion to schema-aware output generation. The process involves discovery, dynamic schema handling, rule-based transformations, and targeted output delivery, all of which are built on Apache Spark.
Step 1: Data discovery and schema generation
AWS Glue Crawlers scan source systems (e.g., Amazon S3, Amazon RDS) and automatically infer schema definitions. These definitions are registered in the AWS Glue Data Catalog and used as the input schema for the transformation job.
Step 2: Create DynamicFrames from source data
Jobs start by loading data as DynamicFrames, AWS Glue’s schema-flexible abstraction over Spark DataFrames. These allow for schema drift, nested structures, and easier transformations without rigid schema enforcement.
Step 3: Apply transformation logic
Users apply built-in transformations or Spark code to clean and modify the data. Common steps include:
- Mapping input fields to a standardized schema (ApplyMapping)
- Removing empty or irrelevant records (DropNullFields)
- Handling ambiguous types or multiple formats (ResolveChoice)
- Implementing conditional business rules using Spark SQL or built-in AWS Glue transformations
- Enriching datasets with external joins (e.g., reference data, APIs)
Step 4: Perform validation and quality checks
Before writing outputs, AWS Glue supports custom validation logic and quality rules (via Data Quality or manual scripting) to ensure referential integrity, format correctness, and business rule conformance.
Step 5: Write outputs to the target stores
Transformed data is saved to destinations such as Amazon S3, Amazon Redshift, or Amazon RDS. Jobs support multiple output formats, such as Parquet, ORC, or JSON, based on downstream analytical needs.
Once transformation workflows are established, businesses must turn their attention to cost oversight to ensure scalable ETL operations remain within budget as usage expands.
How to monitor costs in AWS Glue ETL
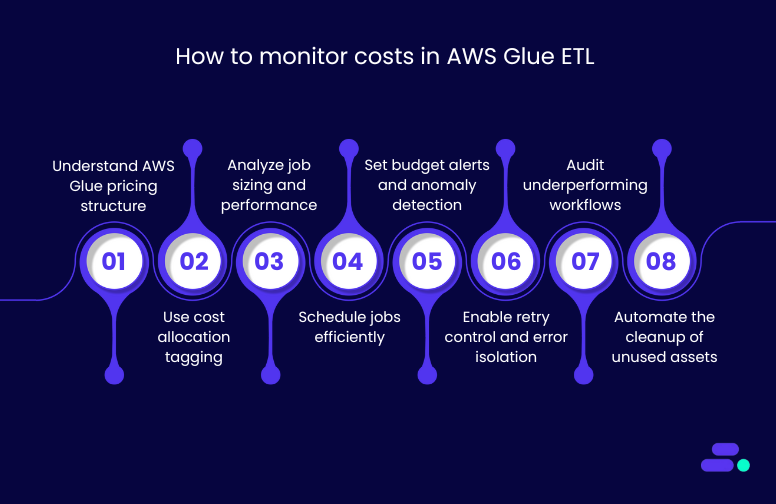
As businesses scale AWS Glue implementations across departments and data products, cost management becomes critical. Enterprise teams implement detailed cost monitoring strategies to ensure data processing performance aligns with operational budgets.
- Understand AWS Glue pricing structure: AWS Glue costs are based on Data Processing Units (DPUs), crawler runtime, and AWS Glue Data Catalog storage. ETL jobs, crawlers, and Python shell jobs are billed at $0.44 per DPU-Hour, per second with a 1-minute minimum (e.g., 6 DPUs for 15 minutes = $0.66). The Data Catalog offers 1M objects and requests free, then charges $1.00 per 100,000 objects and $1.00 per 1M requests monthly. Data Quality requires 2+ DPUs at the same rate. Zero-ETL ingestion costs $1.50 per GB.
- Use cost allocation tagging: Businesses should tag jobs by project, department, or business unit using AWS resource tags. This enables granular tracking in AWS Cost Explorer, supporting usage-based chargebacks and budget attribution.
- Analyze job sizing and performance: Teams adjust job sizing to match the complexity of the workload. Oversized ETL jobs consume unnecessary DPUs; undersized jobs can extend runtimes. Businesses monitor metrics such as DPU hours and stage execution time to right-size their workloads.
- Schedule jobs efficiently: Staggering non-urgent jobs during low-traffic hours reduces competition for resources and avoids peak-time contention. Intelligent scheduling also helps identify idle patterns and optimize job orchestration.
- Set budget alerts and anomaly detection: Administrators set thresholds with AWS Budgets to receive alerts when projected spend exceeds expectations. For broader trends, AWS Cost Anomaly Detection highlights irregular spikes tied to configuration errors or volume surges.
- Enable retry control and error isolation: Jobs that fail repeatedly due to upstream issues inflate costs. Businesses configure intelligent retry patterns and dead-letter queues (DLQs) to isolate bad records and avoid unnecessary full-job retries.
- Audit underperforming workflows: Regularly reviewing job performance helps identify inefficient transformations, outdated logic, and redundant steps. This allows teams to refactor code, streamline logic, and reduce processing overhead.
- Automate the cleanup of unused assets: Stale crawlers, old development jobs, and unused table definitions in the Data Catalog can generate costs over time. Automation scripts using the AWS Software Development Kit (SDK) or the AWS Command Line Interface (CLI) can clean up unused resources programmatically.
While these strategies help maintain performance and cost control, implementing them correctly, especially at enterprise scale, often requires specialized expertise. That’s where partners like Cloudtech come in, helping businesses design, optimize, and secure AWS Glue implementations tailored to their unique operational needs.
How Cloudtech supports advanced AWS Glue implementations
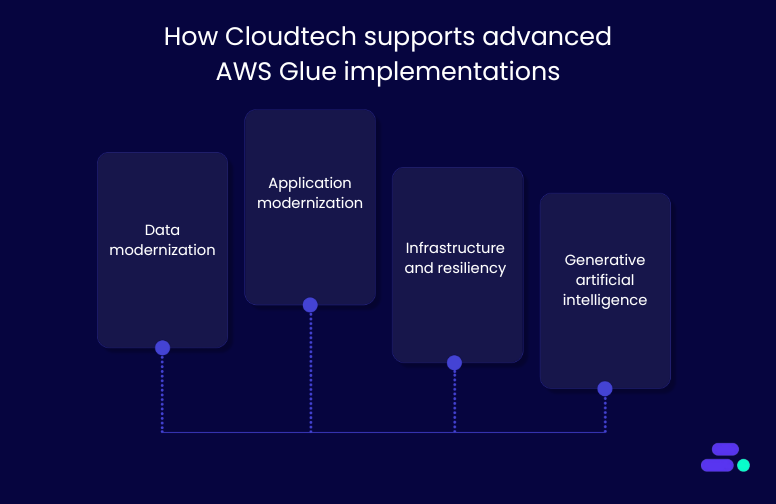
Cloudtech is an AWS Advanced Tier Services Partner focused on helping small and mid-sized businesses modernize data pipelines using AWS Glue and other AWS-native services. The team works closely with clients in regulated sectors such as healthcare and finance to ensure data workflows are secure, efficient, and audit-ready.
Cloudtech’s core service areas directly support scalable, production-grade AWS Glue implementations:
- Data modernization: Cloudtech helps businesses build efficient ETL pipelines using AWS Glue to standardize, validate, and prepare data for analytics. This includes designing schema-aware ingestion workflows and maintaining metadata consistency across data lakes and warehouses.
- Application modernization: Legacy systems are rearchitected to support Glue-native jobs, serverless execution, and Spark-based transformations, enabling faster, more flexible data processing tied to evolving business logic.
- Infrastructure and resiliency: Cloudtech configures secure, compliant Glue deployments within VPC boundaries, applying IAM controls, encryption, and logging best practices to maintain availability and data protection across complex ETL environments.
- Generative artificial intelligence: With integrated Glue pipelines feeding clean, labeled datasets into AI/ML workflows, Cloudtech enables businesses to power recommendation engines, forecasting tools, and real-time decision-making systems, all backed by trusted data flows.
Cloudtech ensures every AWS Glue implementation is tightly aligned with business needs, delivering performance, governance, and long-term scalability without legacy overhead.
Conclusion
AWS Glue delivers scalable ETL capabilities for businesses handling complex, high-volume data processing. With serverless execution, built-in transformation logic, and seamless integration across the AWS ecosystem, it simplifies data operations while maintaining performance and control.
Cloudtech helps SMBs design and scale AWS Glue pipelines that meet strict performance, compliance, and governance needs. From custom Spark logic to cost-efficient architecture, every implementation is built for long-term success. Get in touch to plan your AWS Glue strategy with Cloudtech’s expert team.
FAQ’s
1. What is ETL in AWS Glue?
ETL in AWS Glue refers to the extract, transform, and load processes executed on a serverless Spark-based engine. It enables automatic schema detection, complex data transformation, and loading into destinations like Amazon S3, Redshift, or RDS without manual infrastructure provisioning.
2. What is the purpose of AWS Glue?
AWS Glue is designed to simplify and automate data integration. It helps organizations clean, transform, and move data between sources using managed ETL pipelines, metadata catalogs, and job orchestration, supporting analytics, reporting, and compliance in scalable, serverless environments.
3. What is the difference between Lambda and Glue?
AWS Lambda is ideal for lightweight, real-time processing tasks with limited execution time. AWS Glue is purpose-built for complex ETL jobs involving large datasets, schema handling, and orchestration. Glue supports Spark-based workflows; Lambda is event-driven with shorter runtime constraints.
4. When to use Lambda or Glue?
Use Lambda for real-time data triggers, lightweight transformations, or microservices orchestration. Use AWS Glue for batch ETL, large-scale data processing, or schema-aware workflows across varied sources. Glue suits data lakes; Lambda fits event-driven or reactive application patterns.
5. Is AWS Glue the same as Spark?
AWS Glue is not the same as Apache Spark, but it runs on Spark under the hood. Glue abstracts Spark with serverless management, job automation, and metadata handling, enabling scalable ETL without requiring direct Spark infrastructure or cluster configuration.