Blogs


Turn complex processes into click-and-run efficiency with AWS workflow orchestration
Many SMBs juggle workflows through a patchwork of email chains, manual updates, and one-off scripts. It works, until a single link breaks, and the entire process grinds to a halt.
Consider a hospital’s critical lab test workflow. A single delay in collecting samples, processing results, or notifying the physician can mean hours lost in starting treatment. In emergencies, that lag could make the difference between recovery and deterioration. Managing these handoffs manually is like passing a baton in a dark room, someone’s bound to drop it.
AWS offers a smarter way forward: workflow orchestration using services like AWS Step Functions, EventBridge, and Lambda. These tools let SMB healthcare providers automate multi-step processes across labs, EHR systems, and care teams, ensuring results are processed, recorded, and communicated instantly. Workflows adapt to urgent cases, trigger follow-up actions, and scale without adding staff workload.
This article dives into how SMBs are using AWS workflow orchestration to simplify operations, reduce errors, and respond faster, turning complex processes into seamless, click-and-run efficiency.
Key takeaways:
- Automation eliminates manual delays and errors, enabling faster and more reliable workflows.
- AWS orchestration integrates diverse apps and systems, ensuring seamless data flow and coordination.
- Scalable workflows adjust automatically to changing demands, supporting business growth smoothly.
- Built-in monitoring provides clear visibility into workflow health, enabling proactive optimization.
- Working with experts like Cloudtech ensures workflows are designed and managed for lasting success.
How does AWS workflow orchestration help SMBs function smarter?
Growth often means an increase in moving parts, including more customers, more orders, more data, and more systems to manage. Without a coordinated approach, processes become a tangled web of manual updates, disconnected tools, and inconsistent data flow.
AWS workflow orchestration solves this challenge by connecting these pieces into a seamless, automated sequence, so tasks happen in the right order, at the right time, without human intervention at every step. Businesses can design workflows that span multiple applications and services, both inside and outside AWS.
This means a single event, like receiving a new customer order, can trigger a series of actions: processing payment, updating inventory, sending shipping requests, and notifying the customer, all in the right sequence and without delays.
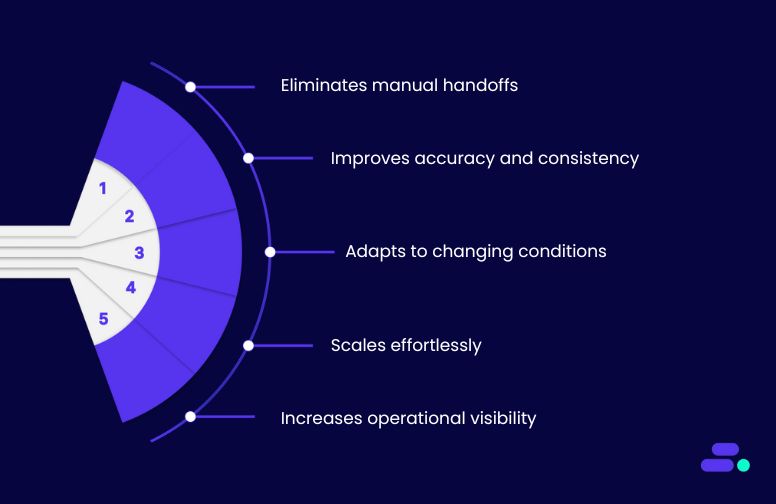
Implementing AWS workflow orchestration:
- Eliminates manual handoffs: No more chasing updates across emails or spreadsheets. Workflows progress automatically as soon as the previous step is complete.
- Improves accuracy and consistency: Automated execution means fewer human errors, more reliable data, and smoother customer experiences.
- Adapts to changing conditions: Workflows can branch into different paths depending on real-time inputs or outcomes (e.g., retry a payment, trigger a different fulfillment method).
- Scales effortlessly: Whether handling 10 transactions or 10,000, AWS-managed workflows scale up or down automatically, so performance never suffers.
- Increases operational visibility: Centralized workflow monitoring lets SMBs track progress, identify bottlenecks, and make quick adjustments before problems escalate.
Moving from a reactive, manual process model to proactive, automated orchestration, enables SMBs not only to save time but also gain the agility to respond to opportunities faster. It’s the difference between simply keeping up and getting ahead without adding more staff or infrastructure complexity.

Top 5 must-know AWS workflow orchestration techniques for SMBs
The lack of a structured approach to workflow orchestration means disconnected systems, repetitive manual tasks, and costly errors that slip through the cracks. Processes may work in isolation, but when growth hits or new tools are introduced, the patchwork begins to fray, slowing teams down and making operations harder to manage.
With the right orchestration strategy, every task is part of a coordinated system. Work moves from one step to the next without bottlenecks or missed handoffs.
AWS makes this possible by combining event-driven automation, integration across diverse applications, and built-in intelligence for handling exceptions. For SMBs, this shift transforms workflows from a series of manual checklists into a reliable engine for productivity and growth, and the following techniques outline exactly how to put that engine to work.
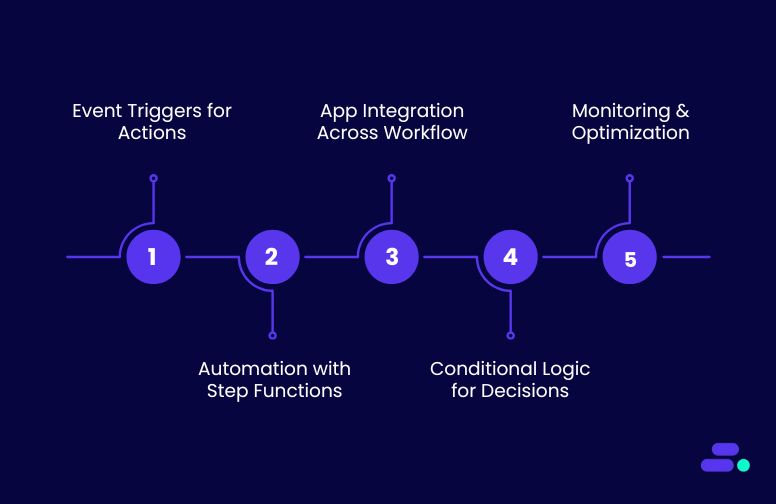
Technique 1: Event-driven triggers for teal-time actions
In traditional SMB operations, processes might rely on scheduled checks or manual intervention. Someone runs a report every few hours, a batch script updates records overnight, or staff manually verify data before moving to the next step. This creates delays, increases error risk, and slows down the entire workflow.
AWS flips this model with event-driven triggers, where actions happen the moment a relevant event occurs.
How this technique brings efficiency:
- Instant responsiveness: Amazon EventBridge captures events the second they occur (e.g., order creation, file upload, form submission) and routes them to the right process without human involvement.
- Seamless integration: Works across AWS services and external SaaS tools, connecting sales, operations, and customer systems into a unified, responsive network.
- Error reduction: Real-time triggers eliminate the lag and manual handling that often lead to duplicated tasks, missed updates, or outdated information.
Use Case: From manual lag to instant fulfillment
Before applying technique: A small online retailer receives orders through their e-commerce platform. Staff export order data to spreadsheets every few hours, manually verify payments, update inventory in a separate system, and finally send the order to the warehouse. If multiple orders come in between updates, stock levels can be inaccurate, and fulfillment may be delayed.
After applying technique: As soon as a customer places an order, AWS EventBridge detects the event from the e-commerce system. It triggers an AWS Step Functions workflow, which calls an AWS Lambda function to verify payment through the payment gateway. If payment is approved, another Lambda function updates stock levels in the inventory database and sends a fulfillment request to the warehouse system via an API.
The customer instantly receives a confirmation email through Amazon Simple Email Service (SES). No waiting for batch updates, no manual checks, just an automated, accurate, and immediate process from click to confirmation.
Technique 2: Step-by-step process automation with AWS Step Functions
Complex workflows often rely on multiple people, systems, and emails to move forward. A missed email, a failed file upload, or a miscommunication can stall progress for hours or even days. Each step depends on someone confirming that the previous one is done, creating bottlenecks and risking errors.
AWS Step Functions changes this by orchestrating workflows as clearly defined, automated steps, each dependent on the successful completion of the previous one, with built-in error handling and retries.
How this technique brings efficiency:
- Clear, structured flow: Breaks complex processes into distinct, manageable steps that execute in a precise sequence.
- Built-in reliability: Automatically retries failed steps and manages exceptions, ensuring workflows don’t stop due to temporary issues.
- Cross-service orchestration: Connects AWS services, APIs, and even external systems into one cohesive automated process.
Use Case: From scattered onboarding tasks to one seamless flow
Before applying technique: A small manufacturing SMB onboards new vendors through a patchwork process. It includes emailing for documents, manually verifying compliance, creating accounts in the ERP system, and sending bank details to finance for payment setup. Each step is tracked in spreadsheets, requiring multiple follow-ups and risking missed or inconsistent data.
After applying technique: AWS Step Functions coordinates the entire onboarding sequence. When a new vendor signs up, the workflow starts automatically: an AWS Lambda function verifies submitted documents, another function integrates with the ERP API to create the vendor account, and a third securely sends payment details to finance.
If any step fails, say, a document is missing, AWS Step Functions pauses the process, sends an Amazon SNS notification to the responsible team, and resumes once resolved. Every stage is tracked automatically, ensuring vendors are onboarded quickly, consistently, and without back-and-forth delays.
Technique 3: Integrating multiple applications across the workflow
In some SMBs, operations span multiple tools, like an e-commerce platform for sales, a shipping provider’s portal for deliveries, a CRM for customer data, and an accounting system for finances. Without integration, staff spend hours copying data from one system to another, risking typos, delays, and mismatched records. This manual effort not only slows things down but also creates blind spots when teams rely on outdated or incomplete information.
AWS workflow orchestration solves this by acting as the “translator” between systems. Using AWS Lambda functions, APIs, and services like Amazon EventBridge, data can move fluidly across platforms without manual intervention. This jeeps every tool in sync in near real time.
How this technique brings efficiency:
- Unified data flow: Ensures all connected systems reflect the same, up-to-date information.
- Fewer manual steps: Eliminates repetitive data entry, freeing staff to focus on higher-value work.
- Scalable connections: Works with both modern cloud tools and older legacy systems via APIs or middleware.
Use Case: From disconnected systems to a unified order pipeline
Before applying technique: A small specialty foods retailer manages online orders in their e-commerce site, manually updates stock in a local database, books shipments through a courier’s portal, and then sends weekly sales summaries to their accountant. Each step requires logging into different systems and copying data by hand, leading to mistakes and delays.
After applying technique: When an order is placed, Amazon EventBridge detects the event and triggers a Step Functions workflow. An AWS Lambda function updates the inventory database instantly, another books a shipment with the courier via their API, and a third sends order and payment details to the accounting system.
This happens within seconds, so inventory levels, delivery status, and financial records are always current, without a single spreadsheet or manual copy-paste.

Technique 4: Conditional logic for smarter decisions
In many SMB operations, decisions are still made by someone manually reviewing data, like approving an order, escalating an issue, or flagging a payment problem. This not only slows the process but also introduces inconsistency, as different people may follow slightly different rules.
AWS Step Functions changes this with choice states, enabling workflows to automatically take different paths based on real-time inputs. Instead of every request following the same route, the system can “think” in logic branches. This checks conditions, applying business rules, and routing tasks without human intervention.
How this technique brings efficiency:
- Automated decision-making: Eliminates delays caused by waiting for manual reviews.
- Consistency and compliance: Every decision follows the same rules and thresholds.
- Reduced operational load: Staff only step in for true exceptions or complex cases.
Use Case: From manual reviews to automated, rules-driven actions
Before applying technique: A small subscription-based software company processes customer payments once a month. If a payment fails, the finance team manually retries the transaction, sends a follow-up email, and flags the account for possible suspension. This requires staff attention multiple times a week.
After applying technique: An AWS Step Functions workflow runs as soon as the billing system detects a failed payment. Using a choice state, it retries the payment up to three times via an AWS Lambda integration with the payment gateway. If the third attempt fails, the workflow automatically sends an alert to customer support through Amazon SNS, while also notifying the customer via Amazon SES.
Finance only gets involved for unresolved cases. This frees their time while ensuring no failed payment slips through the cracks.
Technique 5: Built-in monitoring and optimization
Workflows are a “black box” for many businesses. Once a task starts, there’s little visibility until it’s complete. This makes it hard to spot bottlenecks, diagnose errors, or know where improvements can save time or money.
AWS workflow orchestration changes that with built-in monitoring and analytics. Tools like AWS Step Functions’ execution history, Amazon CloudWatch metrics, and AWS X-Ray tracing provide real-time and historical insights into how workflows run, where failures occur, and which steps consume the most resources. This data-driven visibility allows SMBs to refine workflows with confidence instead of relying on trial and error.
How this technique brings efficiency:
- Proactive issue detection: Spot errors or delays before they affect customers.
- Data-backed optimization: Adjust workflows for cost, speed, and reliability.
- Continuous improvement: Make iterative changes based on actual usage trends.
Use Case: From reactive troubleshooting to proactive refinement
Before applying technique: A small legal services firm relies on a manual review process for client document verification. If delays occur, they’re only noticed after customers complain. Staff investigate manually, often wasting hours retracing steps.
After applying technique: With Step Functions logging each state’s execution time and CloudWatch tracking performance metrics, the team sees that the document verification Lambda consistently takes the longest. They replace it with an AWS Textract-powered OCR workflow, cutting average processing time by 40%. Bottlenecks are now identified in minutes, not days, keeping client satisfaction high and costs in check.

Even if workflow automation feels like a daunting project for SMBs, Cloudtech makes it achievable. Its AWS experts create orchestration strategies that are business-ready on launch day, delivering efficiency, accuracy, and scalability right from the start.
How does Cloudtech make AWS workflow orchestration work for SMBs?
Modern SMBs juggle multiple tools, teams, and processes, and when those aren’t connected, efficiency takes the hit. AWS workflow orchestration changes that by linking systems, automating tasks, and keeping every step running in sync. Cloudtech, as an AWS Advanced Tier Services Partner built exclusively for SMBs, ensures this transformation is done right from the start.
Instead of piecemeal automation, Cloudtech builds cohesive, cloud-native workflows that are easy to scale and maintain. Here’s what that looks like:
- Tailored to SMB realities: From design to monitoring, Cloudtech delivers orchestration strategies that fit lean teams, cutting out complexity and high overhead.
- Resilient by design: Fault-tolerant states, smart retries, and seamless failovers keep processes running, even when a single step encounters trouble.
- Performance-aware automation: Using AWS Step Functions, EventBridge, and Lambda, workflows are tuned to run faster, cost less, and eliminate redundant work.
- Empowered teams: Training, clear documentation, and best-practice guides mean SMBs can confidently adapt and grow their workflows over time.
With Cloudtech, workflows become a dependable, intelligent backbone for business growth.
See how other SMBs have modernized, scaled, and thrived with Cloudtech’s support →

Wrapping up
Efficient workflow orchestration lets SMBs run faster, reduce errors, and adapt quickly without piling on manual effort or disconnected tools. But the real magic isn’t in simply automating tasks. It’s in designing workflows that evolve alongside the business, handle exceptions gracefully, and optimize every moving part.
With Cloudtech’s deep AWS expertise, a focus on reliability, and a hands-on approach, SMBs can build orchestration solutions that are seamless from day one and scalable for years to come. When workflows run smoothly and intelligently, teams can spend less time firefighting and more time innovating, serving customers, and seizing opportunities.
Ready to streamline your operations? Get on a call with Cloudtech and discover how AWS workflow orchestration can become your SMB’s growth engine.
FAQs
1. What is AWS workflow orchestration?
AWS workflow orchestration is the process of coordinating multiple tasks, services, and applications so they work together seamlessly. Using tools like AWS Step Functions and Amazon EventBridge, SMBs can automate repetitive processes, handle decision logic, and integrate cloud and on-prem systems without manual intervention.
2. Why should SMBs care about workflow orchestration?
For SMBs, time and resources are often limited. Orchestration eliminates manual hand-offs, reduces human error, and ensures that business processes from order fulfillment to approvals run faster and more reliably. This leads to higher productivity, happier customers, and better use of IT budgets.
3. How does AWS Step Functions help in orchestration?
AWS Step Functions lets businesses design workflows as state machines, breaking complex processes into manageable steps with built-in retries, error handling, and conditional paths. It can integrate with over 200 AWS services and external APIs, making it ideal for unifying systems in a growing SMB environment.
4. Can workflow orchestration handle both cloud and legacy systems?
Yes. With AWS Lambda functions, API Gateway, and connectors, orchestration can bridge modern SaaS apps, AWS services, and even on-premise legacy systems, allowing data to flow smoothly between them without duplication or mismatches.
5. How can Cloudtech help SMBs get started with AWS workflow orchestration?
Cloudtech designs, builds, and manages tailored orchestration solutions for SMBs. From identifying automation opportunities to implementing AWS best practices and providing ongoing support, Cloudtech ensures workflows are reliable, scalable, and aligned with business goals from day one.

AWS auto scaling hacks: Always right-sized, never over-provisioned
Business scalability starts with simple upgrades, adding more servers, tweaking database queries, or using quick caching hacks. But as demand grows, these patches can turn into bottlenecks, driving up costs and slowing innovation.
Take an e-commerce flash sale, for example. Spikes in traffic can overwhelm systems, leading to slow checkouts, failed payments, and unhappy customers. Scaling reactively is expensive, risky, and often too late to save the moment.
AWS offers a smarter path: built-in scalability with auto scaling groups, serverless architectures, and managed services that adjust in real time. Workloads expand during peak demand and scale back automatically when usage drops, without manual intervention or infrastructure headaches.
This article explores how SMBs are using AWS scalability to handle unpredictable growth, stay cost-efficient, and deliver consistently high performance, no matter the load.
Key takeaways:
- Scalability isn’t just adding hardware: AWS enables dynamic scaling that adjusts in real time without manual intervention.
- Proactive scaling beats reactive fixes: plan for peak demand before it happens to avoid outages and slowdowns.
- Serverless and managed services cut overhead: focus on business growth instead of maintaining infrastructure.
- Elastic Load Balancing ensures reliability: evenly routes traffic to healthy resources for stable performance.
- Expert guidance accelerates results: AWS partners like Cloudtech help SMBs scale cost-effectively and avoid pitfalls.
Why is scalability crucial for SMBs seeking sustainable growth?
Growth can be exhilarating and exhausting for SMBs. As customer demand increases, the very systems that once ran smoothly can start straining under the pressure. Slow load times, delayed transactions, and spiraling infrastructure costs can quickly turn success into a scaling crisis.
Scalability is the ability to handle growth without losing efficiency or overspending, ensuring technology evolves in lockstep with business needs.
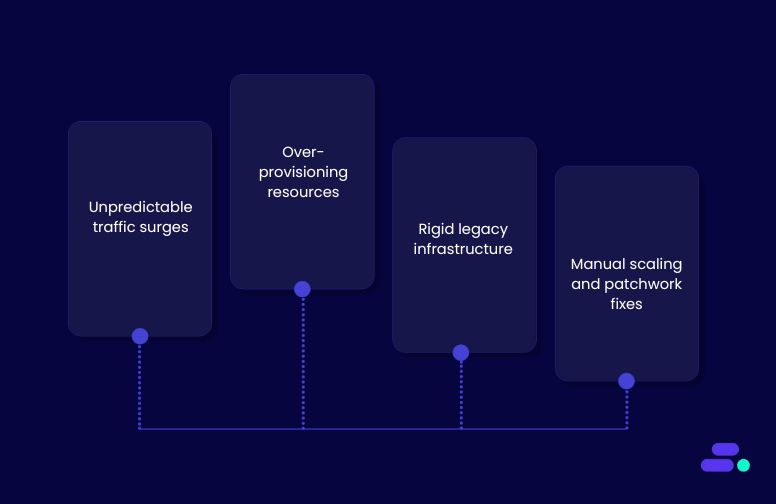
Common scalability challenges faced by SMBs include:
- Unpredictable traffic surges during product launches, flash sales, or seasonal peaks can overwhelm systems and cause downtime.
- Over-provisioning resources to “play it safe” leads to persistent underutilization and inflated cloud bills.
- Rigid legacy infrastructure can’t adapt quickly to changing workloads or integrate easily with modern services.
- Manual scaling and patchwork fixes consume IT resources and delay response times when performance issues arise.
The cost of reactive vs. proactive scaling: Reactive scaling is like calling extra staff in only after the store is already packed. By the time resources are added, customers may have left. This approach risks revenue loss, brand damage, and stressed operations.
Proactive scaling, on the other hand, anticipates demand patterns and uses automation to expand or contract resources ahead of time. With AWS services like Auto Scaling Groups, Elastic Load Balancing, and serverless options, SMBs can keep performance consistent while optimizing costs.
Core AWS scalability concepts every SMB should know:
- Vertical scaling (scale up): Upgrading existing resources for more power, useful for quick fixes but with physical limits.
- Horizontal scaling (scale out): Adding more instances or resources to distribute load, enabling near-unlimited growth potential.
- Elasticity: Automatically adjusting resources up or down in real time, so businesses only pay for what they use.
- Automation: Leveraging AWS tools to make scaling decisions automatically based on metrics like CPU usage, request rate, or queue length.
Ultimately, sustainable SMB growth hinges on infrastructure that doesn’t just “keep up” with demand. It predicts, adapts, and optimizes for it. AWS scalability gives SMBs that edge, helping them grow confidently without overextending resources or budgets.

7 proven AWS scaling strategies for future-proofing SMBs
Without a clear scaling strategy, SMBs often lurch from one crisis to another, scrambling to add capacity during traffic spikes, overspending on idle resources in quieter periods, and constantly firefighting performance issues. With a well-defined scaling strategy, capacity matches demand automatically, costs stay predictable, and systems remain fast and reliable, whether traffic triples overnight or dips to weekend lows.
The good news? AWS makes this level of precision and agility possible without the complexity of traditional scaling. By combining automation, elasticity, and the right architectural choices, SMBs can prepare for growth before it happens, not after it disrupts operations. Using scaling strategies can transform scaling from a reactive scramble into a competitive advantage.
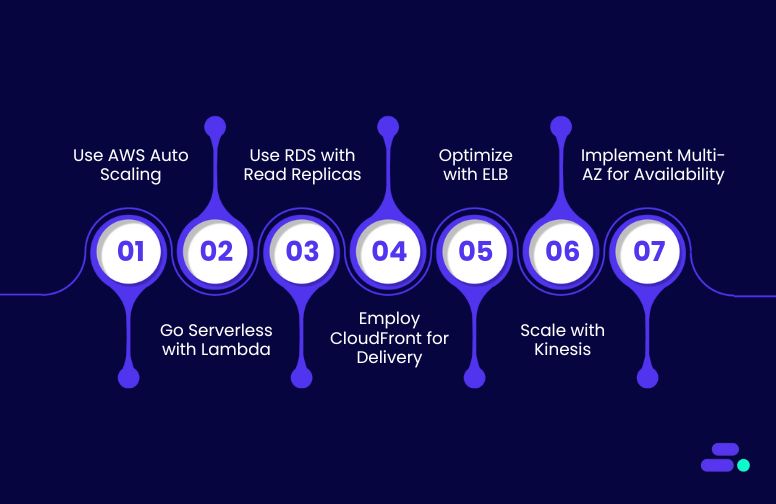
1. Utilize AWS Auto Scaling Groups for demand-driven growth
AWS Auto Scaling Groups (ASGs) automatically adjust the number of EC2 instances in a business environment based on pre-defined metrics such as CPU utilization, network throughput, or custom application signals.
This ensures that the infrastructure expands during heavy workloads and contracts when demand drops, so SMBs are never paying for unused capacity or leaving users frustrated with lag.
How it helps:
- Responds instantly to traffic spikes by adding capacity in real time, preventing slowdowns, failed requests, or outages.
- Optimizes cloud spend by automatically removing surplus instances during off-peak hours or seasonal lulls.
- Eliminates manual scaling guesswork, keeping performance steady without constant human intervention or emergency provisioning.
Use case: A national ticket booking platform faces unpredictable surges whenever top-tier concert tickets go live. The sudden spikes cause slow checkouts, payment errors, and customer complaints. After implementing ASGs, the system detects increased CPU load and launches additional Amazon EC2 instances within minutes, allowing thousands of concurrent bookings without a hitch.
Once the rush subsides, instances are terminated automatically, resulting in a 40% reduction in infrastructure costs while maintaining flawless performance during peak demand.
2. Go serverless with AWS Lambda
AWS Lambda enables SMBs to run code without provisioning or managing servers. The team uploads a function, sets a trigger, and Lambda automatically handles provisioning, execution, and scaling.
This serverless model removes the need for idle infrastructure and provides built-in scalability, allowing the business to concentrate on delivering value rather than managing compute resources.
How it helps:
- Eliminates infrastructure management, freeing IT teams from server maintenance, patching, and provisioning tasks.
- Scales instantly and seamlessly to accommodate bursts in traffic, whether from dozens or thousands of concurrent requests.
- Optimizes costs by charging only for the milliseconds code is executed, avoiding waste on unused capacity.
Use case: A small accounting SaaS previously relied on dedicated servers to process invoices year-round, despite seasonal fluctuations in demand. After adopting AWS Lambda, invoice processing functions trigger only when new documents are uploaded.
During tax season, request volumes spike 20x, yet Lambda scales automatically without delays. Once the season ends, both usage and costs drop dramatically, reducing infrastructure expenses by thousands annually while maintaining fast, reliable performance throughout the year.
3. Use Amazon RDS with Read Replicas
For SMBs with database-heavy workloads, Amazon RDS Read Replicas allow read traffic to be offloaded from the primary database, ensuring that transactional performance remains smooth even during peak activity. This approach improves responsiveness for end users while protecting the stability of write operations. Since RDS automates replication and failover processes, it eliminates the complexity and downtime often associated with manual scaling.
How it helps:
- Boosts query performance by distributing read requests to multiple replicas during traffic surges.
- Separates analytics from transactions, allowing reporting and BI tools to run without slowing down live customer transactions.
- Enables horizontal database scaling without requiring a full application redesign or complex database sharding.
Use case: An online learning platform’s primary database begins to struggle during new course launches when thousands of students access course pages and resources simultaneously. By introducing RDS Read Replicas, the platform routes most read requests to replicas while keeping the primary database dedicated to write operations.
Query times drop by 50%, course materials load instantly, and the launch-day experience remains flawless for learners worldwide.
4. Employ Amazon CloudFront for content delivery
Amazon CloudFront is a global content delivery network (CDN) that stores cached versions of a company’s static and dynamic content, such as images, videos, APIs, and web pages, at strategically located edge servers around the world. By serving requests from these edge locations instead of the primary origin server, CloudFront minimizes latency, optimizes bandwidth usage, and ensures a consistent experience for users no matter where they are.
For businesses with a geographically diverse audience, it provides the infrastructure needed to deliver high-performance content without investing in expensive global hosting setups.
How it helps:
- Speeds up content delivery by routing requests to the nearest edge location, reducing round-trip time and improving responsiveness.
- Reduces strain on origin infrastructure during traffic surges, helping maintain stability under heavy load.
- Boosts user satisfaction and engagement with faster page rendering, quicker video streaming, and smoother application performance.
Use case: A fast-growing fashion e-commerce brand announces a worldwide flash sale. Before adopting Amazon CloudFront, customers in Asia and Europe faced long load times for product pages filled with high-resolution images, leading to abandoned carts.
After implementing Amazon CloudFront, the content is cached closer to customers’ regions, reducing page load times by up to 60%. The result: higher engagement, fewer drop-offs, and a notable increase in international sales conversions.
5. Optimize with AWS Elastic Load Balancing (ELB)
AWS Elastic Load Balancing automatically distributes incoming application or network traffic across multiple targets, such as Amazon EC2 instances, containers, or IP addresses, ensuring no single resource is overwhelmed. It continuously monitors the health of registered targets, directing traffic only to those that are available and responsive.
ELB supports multiple load balancer types, including Application Load Balancer (ALB), Network Load Balancer (NLB), and Gateway Load Balancer (GWLB), allowing businesses to tailor performance and routing strategies to their specific workload needs. This flexibility makes it a foundational tool for building resilient, highly available applications on AWS.
How it helps:
- Eliminates single points of failure by distributing requests across multiple healthy resources.
- Balances workloads efficiently to maintain performance during sudden spikes or seasonal demand.
- Supports zero-downtime deployments through blue/green or rolling update strategies.
Use case: A digital marketing agency experiences frequent slowdowns on its client portals during high-traffic campaign launches. By introducing an Application Load Balancer, traffic is intelligently routed to multiple Amazon EC2 instances based on real-time health checks.
Even when demand tripled, page load times and application responsiveness remained consistent, ensuring better client experience and uninterrupted campaign performance.
6. Scale data processing with Amazon Kinesis
Amazon Kinesis enables real-time streaming data ingestion and processing at virtually any scale. It can capture, process, and store terabytes of data per hour from sources such as IoT devices, application logs, clickstreams, or financial transactions, without requiring infrastructure provisioning or complex scaling configurations.
Amazon Kinesis automatically adjusts to fluctuating data volumes, allowing organizations to act on insights instantly rather than waiting for batch processing. Its flexibility supports multiple consumers, so different teams or systems can process the same data stream for different purposes simultaneously.
How it helps:
- Manages massive data streams seamlessly without over-provisioning or manual scaling.
- Enables real-time analytics and dashboards, allowing immediate insight-driven decisions.
- Supports multiple parallel consumers, catering to diverse data processing needs across teams.
Use case: A logistics SMB needs to track fleet locations in real time. Previously, they relied on batched location updates every 15 minutes, frustrating dispatch teams who needed faster visibility. After implementing Amazon Kinesis, GPS updates stream continuously, giving dispatchers instant tracking and enabling quicker rerouting. This change improves delivery times by 25% and boosts customer satisfaction.
7. Implement multi-AZ deployments for high availability
Multi-AZ deployments spread application and database resources across multiple AWS Availability Zones (AZs) within a region. This architecture ensures that if one AZ experiences an outage, workloads automatically fail over to healthy resources in another zone without manual intervention.
By maintaining geographically separate yet tightly connected infrastructure, businesses gain both high availability and stronger disaster recovery readiness.
How it helps:
- Minimizes downtime by shielding applications from localized failures.
- Strengthens disaster recovery with automatic failover between zones.
- Maintains consistent performance even during maintenance events or outages.
Use case: A healthcare records platform experienced costly downtime when its single data center failed. After migrating to Multi-AZ deployments for Amazon RDS and EC2, any zone outage now triggers a failover to a standby instance in another AZ. Patient access remains uninterrupted, compliance SLAs are met, and operational resilience significantly improves.
Even if SMBs aren’t sure how to adopt these AWS scalability strategies, partners like Cloudtech can design and implement reliable solutions from day one.
How does Cloudtech help SMBs get AWS scalability right?
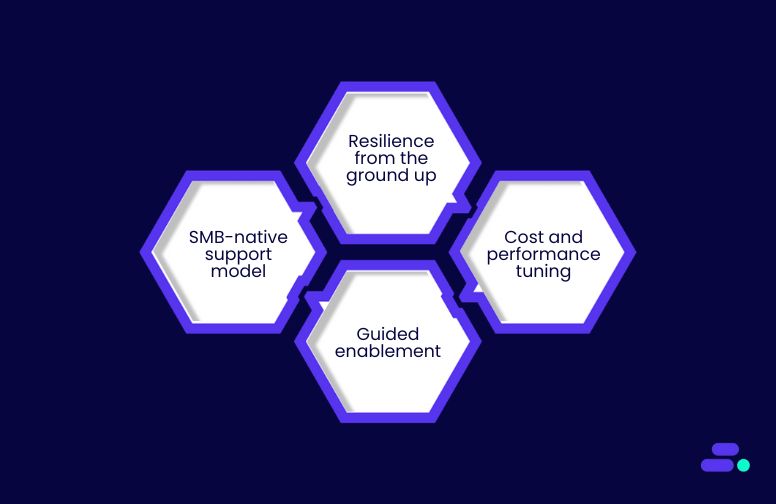
Scaling on AWS is about designing architectures that stay fast, resilient, and cost-efficient as the business grows. That’s where Cloudtech, an AWS Advanced Tier Services Partner built exclusively for SMBs, brings unmatched expertise.
As a managed cloud partner, Cloudtech helps small and mid-sized businesses move from reactive scaling fixes to proactive, future-ready architectures. Here’s how:
- SMB-native support model: Lean IT teams get 24/7 monitoring, quick incident response, and fine-tuned scaling strategies without enterprise overhead or vendor lock-in.
- Resilience from the ground up: Every deployment leverages Multi-AZ architectures, automated failover, load balancing, and caching for uninterrupted performance.
- Cost and performance tuning: Cloudtech continuously optimizes resources with AWS tools like Auto Scaling, CloudWatch, and Trusted Advisor to avoid over-provisioning while keeping response times low.
- Guided enablement: Beyond implementation, Cloudtech equips SMBs with the knowledge, documentation, and confidence to manage their own growth trajectory.
With Cloudtech, SMBs don’t just scale their AWS environments, they scale with purpose, turning cloud elasticity into a true competitive advantage.
See how other SMBs have modernized, scaled, and thrived with Cloudtech’s support →
Wrapping up
Cloud scalability enables SMBs to handle growth without compromising performance, availability, or cost control. But achieving that balance isn’t about throwing more resources at the problem, it’s about designing the right architecture from the start and evolving it as the business changes.
That’s where Cloudtech makes the difference. With a focus on cost optimization, resilience, and hands-on support, Cloudtech ensures scaling is smooth, predictable, and future-proof. When infrastructure scales flexibly, the business can focus on what matters most, like innovation, customers, and market opportunities.
Ready to future-proof your growth? Get on a call with Cloudtech and see how scalable AWS design can become your competitive edge.
FAQs
1. What does “scalability” mean in the AWS context for SMBs?
In AWS, scalability refers to the ability of cloud infrastructure to seamlessly adjust computing power, storage, and networking resources based on demand. For SMBs, this means their applications can handle sudden traffic spikes, seasonal peaks, or business growth without performance drops, downtime, or costly hardware upgrades.
2. Do SMBs need to predict future traffic to scale effectively?
Not necessarily. AWS services like Auto Scaling, Amazon Kinesis, and serverless platforms such as AWS Lambda allow resources to expand or contract automatically based on real-time usage metrics. This means SMBs can maintain performance without over-provisioning for hypothetical peak loads, saving both time and cost.
3. Is scaling on AWS expensive for small businesses?
In many cases, it’s more cost-effective than traditional on-premises scaling. AWS’s pay-as-you-go model charges only for actual usage, while tools like AWS Cost Explorer, Trusted Advisor, and AWS Budgets help track and optimize spending. Cloudtech also applies workload-specific tuning to ensure SMBs get maximum performance without unnecessary costs.
4. How quickly can Cloudtech help an SMB scale on AWS?
The implementation speed depends on the complexity of the existing environment and the scalability requirements. However, Cloudtech’s SMB-focused methodology, which includes rapid assessments, pre-tested architecture patterns, and automation templates, often enables businesses to achieve scalable deployments, such as Auto Scaling groups or Multi-AZ failover setups, in a matter of weeks instead of months.
5. What makes Cloudtech different from other AWS partners for scaling projects?
Cloudtech specializes exclusively in SMBs, understanding the budget constraints, lean team structures, and agility requirements that define smaller organizations. Their AWS-certified architects design for both immediate demand handling and long-term resilience, incorporating performance monitoring, cost optimization, and simplified management to avoid the complexity often seen in enterprise-focused solutions.

How to secure AWS Backup? A proven best practices guide
Data breaches cost organizations an average of $4.45 million per incident according to Statista. In this backdrop, it wouldn’t be far-fetched to say that backups are the primary defense against modern cyber threats.
But how secure are the data backups? Common gaps like unencrypted data, poor role isolation, or storing backups in the same account as production can expose critical assets and make recovery difficult.
Although services like AWS Backup offer a centralized, policy-driven way to protect data with encryption, immutability, access control, and cross-region isolation, securing backups requires more than just turning it on.
This guide breaks down proven best practices to help SMBs secure AWS Backup, ensure compliance, and strengthen long-term resilience.
Key takeaways:
- Backup isolation: AWS Backup uses vaults and immutability to prevent tampering and support recovery from ransomware, corruption, or human error.
- Core AWS methods: Native tools, such as EBS snapshots, RDS PITR, and cross-region replication, enable structured, policy-driven backups across services.
- Security controls: Utilize KMS encryption, role-based IAM, cross-account storage, and Vault Lock in compliance mode to achieve a hardened security posture.
- Testing and monitoring: Run regular restore tests and use CloudTrail, Config, CloudWatch, and Security Hub for backup visibility and drift detection.
Why is it important for SMBs to secure their data backups?
Data backups are more than just insurance for SMBs. They're often the last line of defense against downtime, ransomware, and accidental loss. But without proper security, backups can quickly become a liability rather than a safeguard.
Unlike large enterprises with dedicated security teams and redundant systems, SMBs have to contend with limited resources, making them prime targets for attackers. A poorly secured backup, such as one stored in the same account as production, or without proper encryption, can be exploited to:
- Delete or encrypt backups during a ransomware attack, leaving no clean recovery option.
- Gain lateral access to other resources through misconfigured roles or access permissions.
- Expose sensitive customer or financial data, leading to regulatory fines and reputational damage.
For SMBs, such incidents can result in weeks of downtime, lost customer trust, or even permanent closure. On the other hand, well-secured backups can help SMBs:
- Recover quickly and confidently after accidental deletions, application failures, or cyber incidents.
- Maintain compliance with regulations like HIPAA, PCI-DSS, or GDPR that mandate secure data handling and retention.
- Reduce business risk by ensuring data is encrypted, immutable, and isolated from day-to-day operations.
For example, consider a regional healthcare provider storing both primary and backup data in the same AWS account, without immutability or access restrictions. When a misconfigured script deletes production data, the backup is compromised too. They might have prevented this by implementing cross-account backups with AWS Backup Vault Lock.
In contrast, another SMB uses AWS Backup with encryption, vault isolation, and lifecycle policies. They can easily recover from a ransomware attack within hours, without paying a ransom or losing customer data.
Securing backups isn’t just a security best practice, but a business continuity decision. For SMBs, the difference between recovery and ruin often lies in how well their backups are protected.

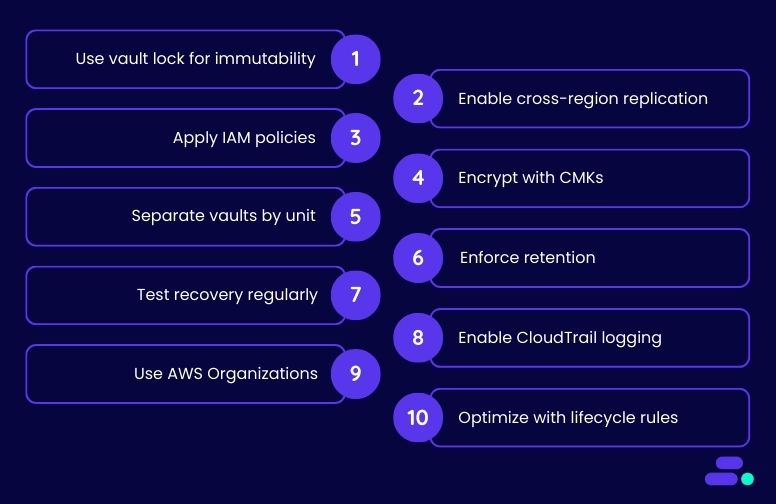
10 right ways to secure AWS Backup and avoid downtime
Setting up backups feels like the final checkbox in a cloud deployment, something done after workloads go live. But this mindset overlooks the fact that backups are a prime target in modern cyberattacks. Ransomware groups increasingly aim to encrypt or delete backup copies first, knowing it cripples recovery efforts.
A backup is only as good as its security. Without immutability, isolation, and proper permissions, even well-intentioned backup plans can fail when they're needed most. By securing AWS Backup from day one using features like vault locking, cross-region replication, and role-based access, SMBs can turn their backups into a resilient, trustable layer of defense, not a hidden point of failure. These practices form the foundation of a dependable backup security posture.
1. Use Backup Vault Lock for immutability
Backup Vault Lock is a feature in AWS Backup that enforces write-once, read-many (WORM) protection on backups stored in a vault. Once configured, backups cannot be deleted or modified, neither by admins nor malicious actors, until their defined retention period expires. This immutability is critical for protecting backups from ransomware, human error, and internal threats.
Why this matters:
- Prevents malicious deletion: Even if an attacker gains privileged access, they cannot erase or overwrite locked backups.
- Meets regulatory compliance: Immutability supports financial, healthcare, and legal mandates that require tamper-proof data retention (e.g., SEC Rule 17a-4(f)).
- Reduces insider risk: Vault Lock disables even root-level deletions, mitigating threats from disgruntled or careless admins.
How to implement with AWS: To enable immutability, configure Backup Vault Lock via the AWS Backup console, CLI, or SDK. Set a min and max retention period for each vault. Once the Vault Lock configuration is in place and finalized, it becomes immutable, and no one can shorten retention or disable WORM protection. It's recommended to test the policy before finalizing using AWS Backup’s --lock-configuration flags, ensuring alignment with compliance and data lifecycle needs.
Use case: A mid-sized healthcare provider uses AWS Backup Vault Lock to protect patient records stored across Amazon RDS and EBS volumes. Given HIPAA compliance requirements and increasing ransomware risks, the team configures a 7-year retention policy that cannot be shortened. Even if attackers breach an IAM role or a new admin misconfigures access, their backups remain secure and unaltered, supporting both legal mandates and recovery readiness.
2. Enable cross-region backup replication
Cross-region backup replication in AWS Backup allows automatic copying of backups to a different AWS Region. This creates geographic redundancy, ensuring that backup data remains available even if an entire region faces an outage, disaster, or security incident. For SMBs, it’s a crucial step toward a more resilient and compliant disaster recovery strategy.
Why this matters:
- Protects against regional outages: If a primary AWS Region experiences a service disruption or natural disaster, backups in a secondary region remain safe and accessible.
- Strengthens ransomware resilience: Cross-region copies isolate backups from the production environment, limiting the blast radius of an attack.
- Supports compliance and BCDR mandates: Many regulatory frameworks and business continuity plans require off-site or off-region copies of critical data.
How to implement with AWS: Enable cross-region replication by configuring a backup plan in AWS Backup and selecting a destination Region for replication. Businesses can apply this to supported resources like EC2, RDS, DynamoDB, and EFS. Lifecycle rules can be defined to transition backups between storage classes in both the source and destination regions to manage costs. AWS Backup Vault Lock in both regions adds immutability and ensures that IAM roles and encryption keys (KMS) are properly configured in each region.
Use case: A regional financial services firm uses AWS Backup to secure its transaction logs and customer data stored in Amazon DynamoDB and Amazon RDS. To meet internal business continuity goals and regulatory guidelines under RBI norms, the company configures cross-region replication to a secondary AWS Region. In the event of a primary region disruption or data breach, IT teams can initiate recovery from the replicated backups with minimal downtime, ensuring operational continuity and compliance.
3. Apply fine-grained IAM policies
Fine-grained AWS Identity and Access Management (IAM) policies help organizations control who can access, modify, or delete backup resources. In AWS Backup, enforcing tightly scoped permissions reduces the attack surface and ensures that only authorized identities interact with critical backup infrastructure.
Why this matters:
- Minimizes accidental or malicious actions: By assigning the least privilege necessary, organizations prevent unauthorized users from deleting or altering backup data.
- Improves auditability and governance: Defined access boundaries make it easier to track actions, comply with audits, and meet regulatory requirements.
- Enforces separation of duties: Segregating permissions between backup operators, security teams, and administrators strengthens internal controls and limits potential abuse.
How to implement with AWS: Organizations can use AWS IAM to create custom permission sets that control specific backup actions such as backup:StartBackupJob, backup:DeleteBackupVault, and backup:PutBackupVaultAccessPolicy. These policies are attached to IAM roles based on team responsibilities, such as restoration-only access for support staff or read-only access for auditors.
To further tighten control, service control policies (SCPs) can be applied at the AWS Organizations level, and multi-factor authentication (MFA) should be enabled for privileged accounts.
Use case: A fintech startup managing critical transaction data across Amazon DynamoDB and EC2 volumes implements fine-grained IAM controls to reduce security risks. Developers can restore from backups for testing, but cannot delete or modify vault settings.
Backup configuration and policy changes are reserved for a small security operations team. This approach enforces operational discipline, limits exposure, and ensures consistent backup governance across environments.

4. Encrypt backups using customer-managed keys (CMKs)
Encryption protects backup data from unauthorized access, both at rest and in transit. AWS Backup integrates with AWS Key Management Service (KMS), allowing organizations to encrypt backups using Customer-Managed Keys (CMKs) instead of default AWS-managed keys, providing stronger control and visibility over data security.
Why this matters:
- Centralizes control over encryption: CMKs give businesses direct authority over key policies, usage permissions, and rotation schedules.
- Enables audit and compliance visibility: All encryption and decryption operations are logged via AWS CloudTrail, supporting regulatory and internal audit requirements.
- Strengthens incident response: If a breach is suspected, access to the CMK can be revoked immediately, rendering associated backups inaccessible to attackers.
How to implement with AWS: In the AWS Backup console or via API/CLI, users can specify a CMK when creating or editing a backup plan or vault. CMKs are created and managed in AWS KMS, where administrators can define key policies, enable key rotation, and set usage conditions.
It's best practice to restrict CMK usage to specific roles or services, monitor activity through CloudTrail logs, and regularly review key policies to ensure alignment with least privilege access.
Use case: A regional law firm backing up case files and email archives to Amazon S3 via AWS Backup uses CMKs to comply with legal confidentiality obligations. The security team creates distinct keys per department, applies granular key policies, and enables rotation every 12 months. If a paralegal’s IAM role is compromised, access to the key can be revoked without impacting other backups, ensuring client data remains encrypted and inaccessible to unauthorized users.
5. Separate backup vaults by environment or business unit
Organizing AWS Backup vaults based on environments (e.g., dev, staging, prod) or business units (e.g., HR, finance, engineering) allows teams to apply tailored access controls, retention policies, and encryption settings. This reduces the blast radius of misconfigurations or attacks.
Why this matters:
- Improves access control: Different IAM permissions can be applied per vault, ensuring only authorized users or services can manage backups within their scope.
- Simplifies compliance and auditing: Clear separation helps track backup behavior, retention policies, and recovery events by organizational boundary.
- Limits cross-impact risk: If one vault is misconfigured or compromised, others remain unaffected—preserving backup integrity for the rest of the business.
How to implement with AWS: Using the AWS Backup console, CLI, or APIs, teams can create multiple backup vaults and assign them logically, such as prod-vault, hr-vault, or analytics-dev-vault. IAM policies should be scoped to allow or deny access to specific vaults. Tags can further categorize vaults for billing or automation. Ensure each vault has appropriate retention settings and uses dedicated encryption keys if isolation is required at the cryptographic level.
Use case: A fintech startup separates backups for its production payment systems, internal HR apps, and test environments into distinct vaults. The production vault uses stricter IAM roles, a longer retention period, and a unique CMK. When a staging misconfiguration leads to an overly permissive role, only the staging vault is affected. Production backups remain protected, isolated, and compliant with PCI-DSS requirements.
6. Define and enforce retention policies
Retention policies in AWS Backup ensure that backups are kept only as long as they’re needed, no longer, no less. By defining and enforcing these policies, organizations reduce unnecessary storage costs, stay compliant with data regulations, and avoid the risks associated with overly long or inconsistent backup lifecycles.
Why this matters:
- Controls data sprawl: Unused backups take up space and increase costs. Automated retention ensures data is removed when no longer needed.
- Supports compliance: Regulatory requirements often dictate how long data must be retained, and automated policies help meet those timelines reliably.
- Reduces manual oversight: By enforcing lifecycle policies, teams avoid accidental deletions or missed cleanup tasks, reducing human error.
How to implement with AWS: AWS Backup lets users define backup plans with lifecycle rules, including retention duration. In the AWS Backup console or via CLI/SDK, admins can set retention periods per backup rule (e.g., 30 days for daily backups, 1 year for monthly snapshots).
Lifecycle settings can also transition backups to cold storage to optimize costs before deletion. Ensure these policies align with both internal data governance and external regulatory needs.
Use case: A regional insurance company configures automated retention for daily, weekly, and monthly backups across Amazon RDS and DynamoDB. Daily backups are kept for 35 days, while monthly backups are retained for 7 years to comply with regulatory audits. This setup ensures consistency, eliminates manual deletion tasks, and prevents accidental retention of outdated data, keeping the backup environment lean, compliant, and efficient.
7. Regularly test backup recovery (disaster recovery drills)
Backups are only as good as the ability to restore them. Regularly testing recovery through disaster recovery (DR) drills ensures that backups are functional, recoverable within required timelines, and aligned with business continuity plans. It’s a critical but often overlooked part of a good backup security strategy.
Why this matters:
- Validates backup integrity: Testing helps confirm that backups are not corrupted, misconfigured, or missing key data.
- Reveals recovery gaps: Simulated drills uncover overlooked dependencies, access issues, or timing failures in recovery workflows.
- Improves incident response: Practicing restores ensures teams can act quickly and confidently during real outages or ransomware events.
How to implement with AWS: AWS Backup supports point-in-time restores for services like Amazon RDS, EFS, DynamoDB, and EC2. Admins can simulate recovery by restoring backups to isolated test environments using the AWS Backup console or CLI.
For full DR simulations, include other AWS services like Route 53, IAM, and security groups in the drill. Document recovery time objectives (RTO) and recovery point objectives (RPO), and automate validation steps using AWS Systems Manager Runbooks.
Use case: A financial tech startup conducts quarterly DR drills to validate recovery of its Amazon Aurora databases and Amazon EC2-based applications. The team restores snapshots in a staging VPC, tests application availability, and verifies data integrity. These drills help refine RTOs, identify hidden misconfigurations, and give stakeholders confidence that the business can withstand outages or data loss events.
8. Enable logging with AWS CloudTrail and AWS Config
Visibility into backup activities is essential for detecting threats, auditing changes, and maintaining compliance. By enabling logging through AWS CloudTrail and AWS Config, businesses gain continuous insight into backup operations, configuration changes, and access patterns. All of these are vital for a secure and accountable backup strategy.
Why this matters:
- Detects unauthorized activity: Logs help identify suspicious actions like unexpected deletion attempts or policy changes.
- Supports forensic analysis: In the event of an incident, detailed logs provide the audit trail necessary to investigate and respond.
- Ensures compliance: Many regulations mandate detailed logging of backup access and configuration for audit purposes.
How to implement with AWS: Enable AWS CloudTrail to log all API activity related to AWS Backup, including backup creation, deletion, and restore events. AWS Config tracks configuration changes to backup vaults, plans, and related resources, ensuring changes are recorded and reviewable.
Use Amazon CloudWatch to create alerts based on log patterns. For example, alerting if a backup job fails or if someone attempts to change retention settings.
Use case: A digital marketing agency uses CloudTrail and AWS Config to monitor backup activity across its AWS accounts. When a contractor mistakenly attempts to delete backup plans, CloudTrail logs the action and triggers an alert through CloudWatch. The security team reviews the logs, confirms the mistake, and updates IAM permissions to prevent recurrence, all without compromising data availability or compliance standing.
9. Use AWS Organizations for centralized backup management
Managing backups across multiple accounts becomes complex without a centralized strategy. AWS Backup integrates with AWS Organizations, allowing businesses to manage backup policies, monitor compliance, and enforce security standards consistently across all accounts from a single management point. This centralization simplifies operations and improves governance.
Why this matters:
- Streamlines policy enforcement: Backup plans can be automatically applied across accounts, reducing manual errors and inconsistency.
- Improves visibility: Admins can monitor backup activity and compliance across the organization in one place.
- Supports scalable governance: Centralized control makes it easier to scale securely as the business adds new AWS accounts.
How to implement with AWS: Enable AWS Organizations and designate a management account. From AWS Backup, turn on organizational backup policies, and define backup plans that apply to organizational units (OUs) or linked accounts. These plans can include schedules, lifecycle rules, and backup vaults. Ensure trusted access is enabled between AWS Backup and Organizations to allow seamless policy distribution and monitoring.
Use case: A growing edtech company manages development, staging, and production workloads across separate AWS accounts. By using AWS Organizations, the operations team centrally enforces backup policies across all environments. They define separate plans for each OU, ensuring that production data has longer retention and replication, while dev environments follow shorter, cost-optimized policies, all without logging into individual accounts.
10. Use backup lifecycle rules to optimize storage and security
AWS Backup lifecycle rules automate the transition of backups between storage tiers, such as from warm storage to cold storage (e.g., AWS Backup Vault and AWS Glacier). This not only reduces long-term storage costs but also ensures that backup data follows a structured lifecycle that aligns with business and compliance needs. Lifecycle rules add predictability and security to backup management.
Why this matters:
- Optimizes costs: Automatically moving older backups to cold storage reduces storage bills without manual intervention.
- Enforces data lifecycle compliance: Ensures backups are retained and archived according to regulatory and business requirements.
- Reduces operational burden: Lifecycle automation reduces the need for manual data classification, transition, and deletion efforts.
How to implement with AWS: When creating a backup plan in AWS Backup, define lifecycle rules specifying when to transition backups from warm to cold storage (e.g., after 30 days) and when to expire them (e.g., after 365 days). Use AWS Backup console, CLI, or APIs to define these settings at the plan level. AWS handles the transitions automatically, maintaining backup integrity and security throughout the lifecycle.
Use case: An accounting firm backs up client data daily using AWS Backup across Amazon EFS and RDS. To balance retention requirements and storage costs, the IT team sets lifecycle rules to transition backups to cold storage after 45 days and delete them after 7 years. This ensures long-term availability for audits while keeping expenses predictable, all with zero manual oversight.
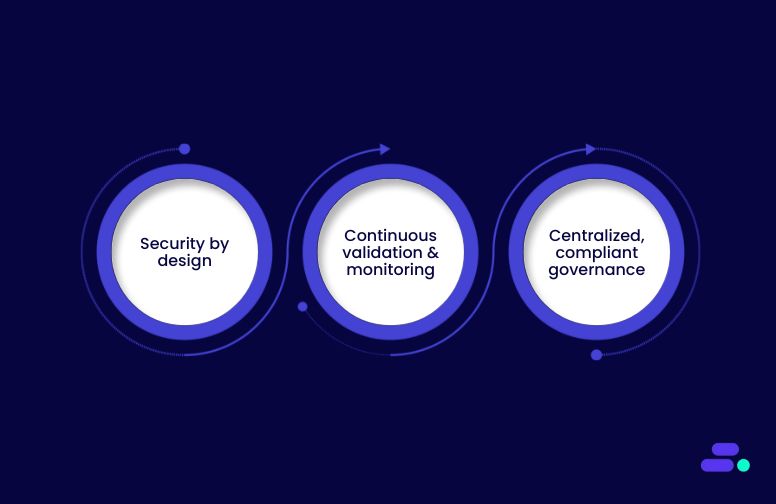
How can Cloudtech help SMBs secure their AWS Backups?
SMBs looking to secure their AWS backups face increasing risks from ransomware, misconfigurations, and compliance complexity. Cloudtech, an AWS Advanced Tier Partner, brings specialized capabilities that go beyond basic AWS setup, helping businesses build resilient, secure, and fully auditable backup environments tailored to their size and risk profile.
Why SMBs choose Cloudtech:
- Built-in security by design: Cloudtech architects resilient, multi-AZ, immutable, and auditable backup systems from the ground up. This includes applying Vault Lock, cross-region replication, and cold storage lifecycle strategies with strict compliance mapping (HIPAA, SOC 2, PCI-DSS).
- Ongoing validation and monitoring: Rather than relying on manual checks, Cloudtech sets up continuous backup monitoring using AWS CloudTrail, AWS Config, and CloudWatch. They also schedule and validate disaster recovery drills, ensuring that restore paths actually work when needed.
- Centralized, compliant governance: From IAM policy enforcement to secure key management and cross-account vault separation, Cloudtech builds governance into the backup architecture. Their AWS-certified architects help SMBs enforce least privilege, define retention policies, and meet audit requirements, all without hiring in-house AWS experts.
In summary, Cloudtech brings strategic AWS depth and operational maturity to SMBs that can’t afford backup failures. Their security-first, compliance-ready approach helps organizations confidently protect their data, avoid costly breaches, and simplify long-term governance.
Conclusion
Securing AWS backups requires deliberate strategies around encryption, access control, and automated enforcement. Features like Vault Lock, cross-account isolation, and lifecycle policies must work in concert to guard against both operational failures and malicious threats.
Regular recovery testing, configuration monitoring, and compliance validation ensure that backups remain dependable when it matters most. As ransomware and insider risks increasingly target backup infrastructure, immutability and automation are no longer optional.
For SMBs wanting to adopt these best practices and establish a secure, audit-ready, and resilient backup posture, Cloudtech brings the AWS-certified expertise, automation capabilities, and tailored support to help them get there.
Connect with Cloudtech or book a call to design a secure, compliant AWS backup solution tailored to your business.
FAQ’s
1. What is the difference between AWS Backup and EBS snapshot?
AWS Backup is a centralized backup service that supports multiple AWS resources. EBS snapshots are specific to volume-level backups. AWS Backup can manage EBS snapshots along with other services under a unified policy and compliance framework.
2. Is AWS Backup stored in S3?
Yes, AWS Backup stores backup data in Amazon S3 behind the scenes, using highly durable storage. However, users do not access these backups directly through S3; access and management occur through the AWS Backup console or APIs.
3. How much does an AWS backup cost?
AWS Backup costs vary by resource type, storage size, retention duration, and transfer between regions or accounts. Charges typically include backup storage, restore operations, and additional features like Vault Lock. Pricing is detailed per service on the AWS Backup pricing page.
4. When to use EBS vs EFS?
EBS is used for block-level storage, ideal for persistent volumes attached to EC2 instances. EFS provides scalable file storage accessed over NFS, suitable for shared workloads requiring parallel access, such as content management systems or data pipelines.
5. Is AWS Backup full or incremental?
AWS Backup performs incremental backups after the first complete copy. Only changes since the last backup are saved, reducing storage use and backup time while preserving restore consistency. The service handles this automatically without requiring user-side configuration.

Why are SMBs choosing serverless step functions over cron jobs and custom code?
Backend automation mostly starts with quick fixes using cron jobs, custom scripts, or ad-hoc code. But as systems grow, these solutions become brittle, hard to debug, and tough to scale.
Consider a patient intake process, which includes verifying insurance, updating EHRs, and notifying staff. With cron jobs or custom code, failures might go unnoticed until they impact care. Serverless Step Functions offer a better path with automated, scalable workflows that handle errors, retries, and dependencies without constant oversight.
SMBs can design these processes as visual, reliable workflows, fully managed, event-driven, and scalable by default. No more maintaining background scripts or worrying about what happens if a step fails at 3 AM.
This article explores why SMBs are making the shift from legacy automation methods to serverless step functions, and how this move is helping them streamline operations.
Key takeaways:
- AWS Step Functions simplify workflow automation by coordinating tasks like validation, API calls, and notifications without managing servers.
- Built-in error handling and retries ensure processes run reliably, reducing manual rework and system downtime.
- Parallel execution boosts efficiency, allowing multiple tasks (like scheduling and notifications) to run simultaneously.
- AWS Step Functions scales automatically, making it ideal for SMBs looking to grow without adding operational overhead.
- Working with an AWS Partner like Cloudtech accelerates implementation and ensures automation aligns with real SMB goals.
The hidden costs of cron jobs and custom glue code
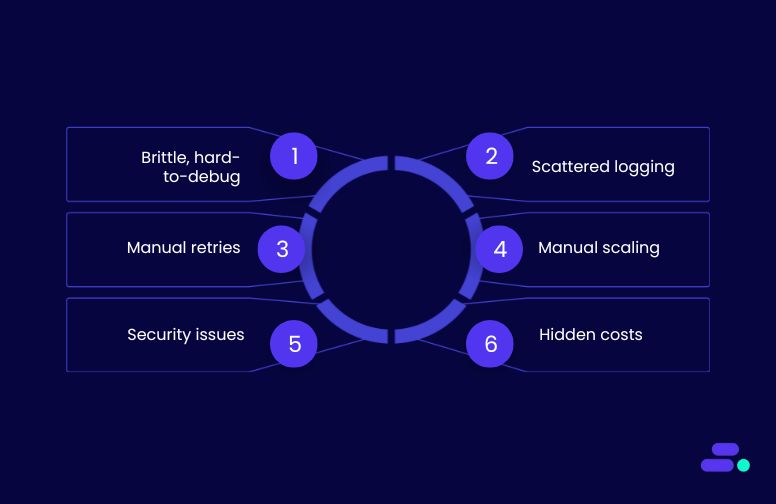
At first, cron jobs and glue code feel like quick wins. They’re simple, familiar, and seem to get the job done. But over time, what starts as a straightforward script might turn into a fragile patchwork that introduces more problems than it solves, especially for growing businesses operating in the cloud.
The operational pain points behind the scenes:
- Brittle and hard to debug: Cron jobs lack built-in error handling or visibility. If a task fails silently at 2 a.m., teams may not know until users complain, or worse, sensitive workflows go incomplete.
- Scattered logging and monitoring: Logs are often stored across different systems (or nowhere at all), making it hard to trace issues or maintain compliance. Debugging becomes time-consuming and frustrating.
- Manual retries and failure recovery: When a job fails, someone has to step in and manually re-trigger it or fix the data it left half-processed. This reactive approach slows teams down and increases risk.
- Scaling is manual or non-existent: Most cron jobs run on fixed infrastructure. As load increases, performance suffers, or teams need to intervene to scale manually, neither of which supports agility.
- Security and access management headaches: Scripts and jobs often use hardcoded credentials or shared environments, creating security gaps that are difficult to audit or manage.
- Hidden maintenance costs: Over time, teams spend more effort maintaining brittle code than delivering new features. And when the person who wrote the job leaves, knowledge often walks out the door too.
Why this doesn’t scale in the cloud: Modern cloud-native environments thrive on automation, observability, and scalability. Cron jobs and glue code weren’t designed for this. They may seem like the fastest route early on, but they’re rarely the most sustainable or cost-effective as the business grows.
That’s why SMBs are shifting toward orchestrated, serverless solutions like AWS Step Functions. They offer a structured, fault-tolerant way to automate complex workflows, with less operational baggage.
How do AWS Step Functions deliver scalable, reliable, and maintainable workflows?
As SMBs grow, so do the demands on their backend systems. What once worked with a few cron jobs or scripts often becomes a tangled web of logic. For lean teams, especially in regulated industries, even a minor workflow failure can lead to compliance risks, lost productivity, or customer frustration.
To better understand the relevance of serverless step functions over cron jobs and custom code, take the example of a growing healthcare clinic. Onboarding a new patient involves several steps, many of which were traditionally manual or loosely automated. With AWS Step Functions, that is no longer the case:
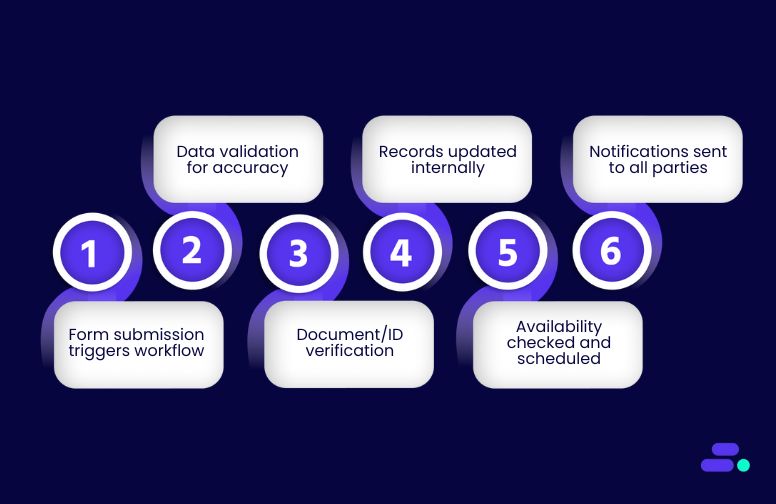
Step 1: Intake form submission triggers the workflow
The patient intake journey begins the moment someone fills out an online form, maybe on a clinic’s website or patient portal. Traditionally, this would require backend polling, manual data entry, or cron-based checks to process form submissions. With AWS Step Functions, the process becomes instant, event-driven, and serverless.
Here’s how it works behind the scenes:
- Amazon API Gateway receives the HTTP POST request from the form and acts as the front-door to the workflow, providing a secure and scalable entry point.
- AWS Lambda processes the incoming request, sanitizes data if needed, and then directly starts the Step Function execution using the AWS SDK.
- AWS Step Functions picks up the baton immediately, no need for persistent infrastructure or background schedulers to monitor form submissions.
Outcome: The moment a patient submits the form, the automation begins in real time. This ensures no delays, removes the need for backend polling scripts, and guarantees that no intake request falls through the cracks, even during peak load. It's fast, secure, and fully managed from the first click.
Step 2: Validate patient data
After intake submission, the next critical step is validating patient information. This includes ensuring required fields are present, checking for formatting errors, and verifying identifiers like insurance numbers. In many SMB healthcare setups, this would typically involve handwritten scripts or manual admin review, both prone to error and delay. With AWS Step Functions, validation becomes automated, consistent, and fault-tolerant.
Here’s how AWS handles this step:
- AWS Lambda handles validation logic, such as checking for missing fields, malformed contact details, or mismatched insurance number formats.
- AWS Step Functions' built-in error handling automatically catches failures and retries based on a configurable policy, no need for custom retry logic or manual intervention.
- ResultPath and Catch blocks in AWS Step Functions allow seamless branching, sending invalid entries to a remediation workflow or alert queue without breaking the entire process.
Outcome: Patient data is reviewed and validated in real time, with failed attempts retried automatically and consistently. This reduces human error, saves staff time, and ensures that only clean, verified data moves forward, essential for compliance, billing, and patient safety.
Step 3: Document verification
Once patient data is validated, the next step is verifying supporting documents such as ID proof, insurance cards, or medical history forms. In traditional SMB environments, this often involves email attachments, manual uploads, or local storage, all of which are error-prone and hard to scale. With AWS, this entire step becomes automated and intelligent.
Here’s how AWS handles this step:
- Amazon S3 securely stores uploaded documents, providing durable, scalable storage that integrates easily with downstream services.
- AWS Lambda picks up the file event and invokes Amazon Textract, which automatically extracts key identity data (e.g., name, date of birth, insurance details) using AI-powered OCR.
- AWS Step Functions monitors the output from Textract. If the document is unreadable or incomplete, it routes the case to a manual review queue (e.g., via Amazon SQS or a custom admin dashboard), ensuring the rest of the workflow continues unaffected.
Outcome: SMBs can automate identity verification without compromising on accuracy or compliance. The system intelligently handles bad scans or missing info without disrupting the broader process, freeing up staff to focus only on exceptions while scaling smoothly during high patient volumes.
CTA Button Link:
Step 4: Patient record update in EHR
After verifying documents, the final step in onboarding is updating the patient’s information in the clinic’s Electronic Health Record (EHR) system. Traditionally, this might involve a staff member manually entering data into multiple systems, which is a time-consuming and error-prone process. With Step Functions, this step is programmatically automated and resilient to failure.
Here’s how AWS handles this step:
- AWS Lambda packages the verified patient data and makes a secure API call to the external EHR system. This could be a RESTful endpoint exposed by a third-party provider.
- AWS Step Functions defines retry logic using exponential backoff and timeout policies. If the EHR system is temporarily down or responds with an error, the function automatically retries without manual intervention.
- Failure handling is built in. If all retries fail, the Step Function can trigger an alert (e.g., via Amazon SNS) or route the request to a dead-letter queue for follow-up.
Outcome: The patient record is updated in real time, reliably and securely. Even if the external system is intermittently unavailable, the workflow stays resilient, reducing admin effort, preventing data loss, and ensuring compliance with healthcare data handling requirements.
Step 5: Check appointment availability and schedule
Once patient records are updated, the next step is to schedule their appointment, often a bottleneck when done manually or handled sequentially in code. With AWS Step Functions, this part of the workflow can be both parallelized and automated, improving speed and patient experience.
Here’s how AWS handles this step:
- AWS Lambda invokes the appointment scheduling microservice (or API) to check for available time slots based on doctor schedules, patient preferences, or clinic hours.
- AWS Step Functions' Parallel State enables this to run alongside other actions like sending a confirmation email or updating the CRM without waiting for one to finish before the other starts.
- Conditional branching can be added if no slots are available. For e.g., prompt the patient to choose another time or notify staff for follow-up.
Outcome: The system instantly finds a matching slot and confirms the appointment, while other tasks (like sending notifications) continue in parallel. This reduces patient wait times, eliminates scheduling delays, and enables the clinic to operate more efficiently even during peak hours.
Step 6: Notify patient and staff
Once the appointment is locked in, timely communication is critical, not just for patient experience, but also for operational coordination. Instead of relying on separate tools or manual follow-ups, AWS Step Functions lets users automate this step with full traceability.
Here’s how AWS handles this step:
- AWS Lambda sends a confirmation email to the patient using a service like Amazon SES or a third-party provider integrated via API.
- Amazon SNS (Simple Notification Service) is optionally triggered to send an SMS alert, either to the patient, front-desk staff, or both.
- AWS Step Function execution history captures every notification attempt, making it easy to audit or troubleshoot if a message fails to send.
Outcome: Every stakeholder receives timely updates, and the entire process is visible in one place. No more guesswork, missed messages, or siloed systems. Notifications are consistent, auditable, and automated, ensuring patients feel cared for and staff stay informed.
Do these benefits apply for SMBs in other sectors?
While the above use case followed a healthcare clinic automating patient intake and scheduling, the same workflow structure applies to SMBs across industries. Whether it’s a logistics firm automating shipment tracking, a financial services company validating KYC documents, or an e-commerce business handling returns, the building blocks remain the same:
- An event (form submission, file upload, payment, etc.) triggers a Step Function using API Gateway and Lambda.
- The workflow automatically coordinates the required steps, from validation to external API calls to notifications.
- Tasks run in parallel where possible, and errors are handled without human intervention.
The real power lies in how AWS Step Functions deliver enterprise-grade orchestration with zero infrastructure burden.
For the healthcare SMB, this means no more background scripts or fragile cron jobs. For other SMBs, it means reliable, scalable, and auditable workflows without hiring an ops team. With AWS Step Functions, automation becomes a strategic asset, not a maintenance headache.
Even if SMBs are unsure of how the transition to AWS Step Functions affects their workflow, AWS partners like Cloudtech can help them with the implementation. With deep expertise in architecting serverless workflows, Cloudtech helps SMBs design and implement automation that’s reliable from day one.
Why do SMBs trust Cloudtech to implement step functions right?
Orchestrating complex workflows with AWS Step Functions isn’t just about wiring services together, it’s about designing for scalability, resilience, and long-term maintainability from day one. That’s where Cloudtech, an AWS Advanced Tier Services Partner built exclusively for SMBs, brings unique value.
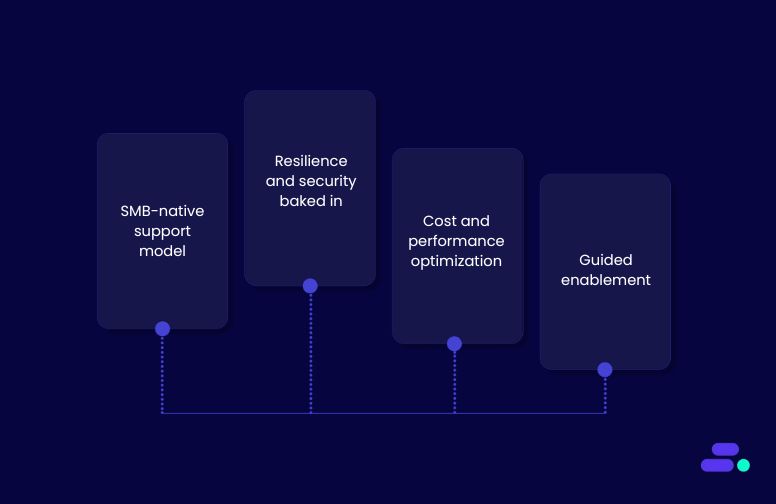
As a managed cloud partner, Cloudtech helps small and mid-sized businesses go beyond automation experiments to real-world, production-ready outcomes. Here’s how:
- SMB-native support model: Lean teams get 24/7 monitoring, fast incident response, and patch management, without enterprise complexity or vendor lock-in.
- Resilience and security baked in: Every Step Function architecture includes IAM best practices, automated retries, backup strategies, and multi-AZ failover.
- Cost and performance optimization: Cloudtech continuously tunes workflows using tools like AWS CloudWatch, Trusted Advisor, and X-Ray, ensuring automation stays efficient as businesses grow.
- Guided enablement: Beyond implementation, Cloudtech helps SMBs build internal confidence, offering knowledge transfer, architectural clarity, and proactive recommendations.
With Cloudtech, SMBs gain more than a serverless workflow. They gain a strategic partner that helps turn AWS automation into a business advantage.
See how other SMBs have modernized, scaled, and thrived with Cloudtech’s support →
Wrapping up
Serverless automation with AWS Step Functions gives SMBs the ability to streamline operations, reduce errors, and scale workflows without managing infrastructure. But unlocking that value consistently requires more than tools. It takes guidance, experience, and a partner who understands the unique needs of growing businesses.
That’s where Cloudtech comes in. As an AWS Advanced Tier Partner focused solely on SMBs, Cloudtech doesn’t just deploy automation, it delivers long-term business value. With a proactive, cost-conscious approach to managed services, they help SMBs move faster, operate smarter, and avoid the common pitfalls of DIY cloud.
When operations are on autopilot, innovation can take the driver’s seat. Ready to make your workflows more resilient, and your business more agile? Get on a call and find out how Cloudtech can help you scale with confidence.
FAQs
1. Do SMBs need coding expertise to use AWS Step Functions?
Not always. While defining workflows typically involves JSON using Amazon States Language (ASL), AWS also provides a visual editor that makes it easy to view and manage workflows. With the right AWS Partner, even teams with limited coding resources can implement and operate Step Functions effectively.
2. Can Step Functions integrate with existing SMB systems?
Yes. Step Functions integrate easily with both AWS services and external systems via Lambda functions, API Gateway, and SDKs. Whether an SMB uses ERP platforms, CRMs, or industry-specific tools, workflows can be designed to automate and orchestrate across these systems seamlessly.
3. What happens if part of a workflow fails?
AWS Step Functions include built-in error handling, retries, and fallback paths. If a task fails, such as a timeout or a downstream API error, the system can automatically retry or trigger an alternate step, preventing silent failures and minimizing disruption.
4. Is this scalable as the business grows?
Absolutely. Step Functions are serverless and scale automatically with demand. Whether an SMB runs a few workflows a day or thousands, there’s no infrastructure to manage. This makes it especially well-suited for growing companies that need reliable automation without added operational complexity.
5. How does an AWS Partner like Cloudtech help?
Cloudtech helps SMBs implement Step Functions in a way that’s secure, efficient, and tailored to their unique workflows. As an AWS Advanced Tier Partner focused on SMBs, Cloudtech supports everything from initial architecture design to long-term optimization, ensuring each workflow delivers measurable business value.

Why are SMBs opting for cloud managed services?
According to Gartner, more than 85% of organizations will have embraced a cloud-first strategy by 2025. But for most of these organizations, especially SMBs, managing cloud infrastructure in-house might feel like trading one set of IT challenges for another. From talent shortages to escalating costs, maintaining secure, scalable environments often stretches lean teams beyond capacity.
That’s why more SMBs are turning to cloud managed services, not just to offload technical work, but to unlock real business agility. The value goes beyond uptime. With 24/7 monitoring, built-in security, and cost-optimized operations, SMBs can shift focus from fire-fighting IT issues to delivering innovation.
This article will dive deeper into the key reasons why SMBs are increasingly choosing managed cloud services over in-house operations.
Key takeaways:
- MSPs simplify cloud complexity: Managed Service Providers handle infrastructure, automation, security, and cost optimization, so SMBs can focus on growth, not IT management.
- They turn cloud into a business advantage: Beyond maintenance, MSPs help SMBs modernize applications, improve performance, and extract more value from AWS investments.
- Cost control is proactive, not reactive: With real-time monitoring, rightsizing, and savings plans, MSPs ensure cloud spending stays aligned with business needs.
- Support is continuous, not just during office hours: MSPs offer 24/7 monitoring, automated incident response, and escalation paths to safeguard critical workloads.
- MSPs are partners in strategy, not just support: The right MSP brings cloud expertise, business alignment, and shared accountability to help SMBs scale with confidence.
How can cloud managed services help SMBs?
Managing cloud infrastructure in-house often becomes a bottleneck for SMBs. Hiring and retaining skilled cloud professionals is costly and time-consuming, and internal IT teams are frequently stretched thin maintaining uptime, updates, and security.
Take the case of a healthcare provider managing its patient data and telemedicine platform on the cloud. While it gives scalability, the in-house IT team is overwhelmed, juggling patch management, uptime monitoring, and security audits, all while lacking deep cloud expertise. Hiring additional DevOps engineers isn't financially viable, and gaps in backup and compliance threaten patient data integrity.
By partnering with a cloud managed service provider (MSP), they can offload day-to-day operations like system monitoring, patching, and security updates. The MSP implements automated backup policies, ensures HIPAA compliance, and introduces 24/7 alerting through AWS-native tools. The result? Improved uptime, faster support response times, and a reduction in operational IT costs.
This shift allows the internal team to refocus on improving the patient experience, rolling out new features and digital services without being slowed down by infrastructure worries.
Key benefits of working with an MSP include:
- Cost savings: Reduce the need for full-time cloud experts, on-prem infrastructure, and ad hoc consulting by shifting to predictable, subscription-based models.
- 24/7 monitoring and support: Ensure round-the-clock availability and fast incident response without the need for internal shift rotations.
- Enhanced security posture: Get continuous vulnerability monitoring, patch management, and compliance reporting, often using AWS-native tools like GuardDuty, CloudTrail, and Config.
- Scalability on demand: Easily scale infrastructure up or down based on real-time business needs, without long procurement cycles.
- Access to cloud expertise: Tap into certified professionals who stay updated with evolving AWS best practices, architectures, and compliance requirements.
Cloud managed services turn reactive IT into a proactive, value-driving function without the burden of building everything in-house.
Top 5 reasons why SMBs choose cloud managed services
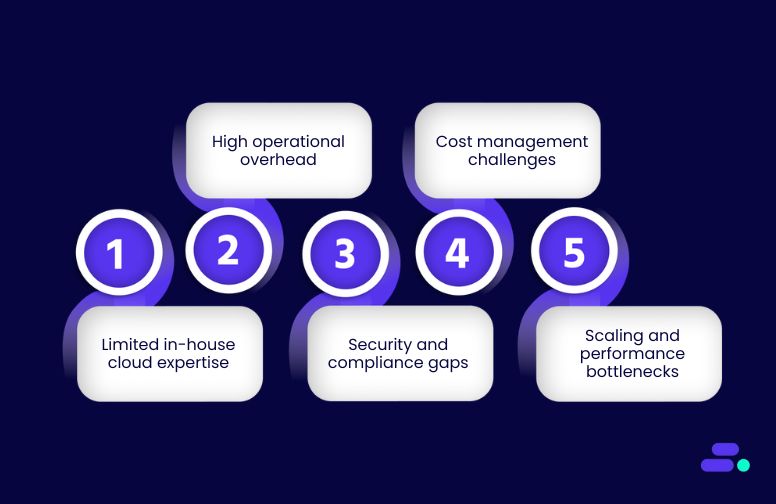
SMBs dealing with limited budgets, human resources shortages, and growing cloud complexity partner with a managed service provider (MSP) for strategic benefits, including enterprise-grade cloud capabilities, proactive support, and operational resilience without the overhead of building internal teams.
There are several reasons why a SMB might choose to work with a MSP. It’s not just about outsourcing IT but unlocking agility, reducing risk, and focusing on growth.
1. Limited in-house cloud expertise
Many SMBs begin their cloud journey without the specialized knowledge required to navigate AWS’s complex ecosystem. Hiring AWS-certified professionals such as cloud architects, DevOps engineers, or security experts is expensive. Attracting and retaining them in a competitive market adds further pressure. For small teams, building in-house capability can take months, delaying key cloud initiatives.
How this impacts business:
- Misconfigurations expose vulnerabilities: Poorly implemented IAM roles, insecure Amazon S3 buckets, or misconfigured VPCs can lead to security incidents or compliance breaches.
- Overprovisioned resources inflate costs: Without deep understanding of AWS pricing models, teams often choose oversized Amazon EC2 instances or underutilize services, leading to significant cost inefficiencies.
- Innovation slows down: Internal teams are pulled into reactive support and troubleshooting, diverting focus from product development and business growth.
MSP Solution: A cloud MSP or an AWS partner brings instant access to AWS-certified experts who apply proven architectural patterns and best practices from the start. They’ll know how to utilize tools like AWS Control Tower for multi-account governance, AWS Well-Architected Framework to identify and fix workload risks, and AWS CloudFormation or Terraform for consistent, repeatable infrastructure deployment. MSPs can also help optimize cost through right-sizing, usage monitoring, and implementation of Savings Plans or Reserved Instances, while ensuring workloads are secure, compliant, and well-architected.
2. High operational overhead
Managing cloud operations, including patching, backups, scaling, monitoring, can quickly overwhelm small IT teams, especially when they’re already juggling daily support, user requests, and legacy infrastructure. As the number of cloud services grows, maintaining performance, reliability, and compliance becomes increasingly complex.
How this impacts business:
- Uptime and performance suffer: Without proactive monitoring and auto-remediation, downtime incidents take longer to detect and resolve, frustrating users and customers.
- Manual monitoring misses critical events: Relying on scripts or ad hoc checks means serious issues like CPU spikes, failed backups, or misbehaving apps can go unnoticed until they cause major disruptions.
- Internal resources are drained: Skilled staff spend time managing maintenance windows, updates, or backup schedules instead of focusing on improving applications or customer experience.
MSP Solution: A cloud MSP or an AWS partner streamlines operational burden by delivering round-the-clock monitoring, automation, and incident management. Using AWS-native tools like Amazon CloudWatch (for real-time performance metrics and alerts), AWS Systems Manager (for fleet-wide automation and patching), and AWS Backup (for centralized backup orchestration), MSPs reduce downtime risks and human error. They implement scaling policies, define runbooks, and proactively manage SLAs, ensuring critical workloads remain available, secure, and performant with minimal internal effort.
3. Security and compliance gaps
SMBs may sometimes lack the tools, time, and expertise required to maintain enterprise-grade cloud security. Implementing continuous monitoring, data encryption, identity access management, and audit readiness across environments demands dedicated effort and specialized skills. For lean IT teams, this might be deprioritized until an incident forces action.
How this impacts business:
- Increased risk of breaches or ransomware: Without intrusion detection, patch management, and network segmentation, attackers can exploit misconfigurations and outdated systems.
- Failure to meet regulatory standards: Regulations like HIPAA, GDPR, or SOC 2 require constant tracking of data handling practices, encryption, and access logs. Failing to do so results in fines and reputational damage.
- Loss of customer trust and legal exposure: A single publicized security incident or compliance violation can erode customer confidence and invite lawsuits or contract cancellations.
MSP Solution: A cloud MSP or an AWS partner provides layered, AWS-native security and governance from day one. They use AWS IAM to enforce least-privilege access, AWS GuardDuty for continuous threat detection, and AWS KMS for encryption key management. AWS Config enables real-time tracking of resource changes and drift from security baselines. MSPs also handle compliance mapping (e.g., to CIS benchmarks or HIPAA frameworks), automate auditing and remediation, and provide ongoing visibility into the security posture through centralized dashboards and alerts, reducing risk without overloading internal teams.
4. Cost management challenges
Cloud services like AWS offer unmatched scalability and pay-as-you-go pricing, but this also means a labyrinth of services, pricing models, and billing intricacies. For SMBs without cloud financial expertise, costs can escalate quickly due to lack of proactive governance, architectural inefficiencies, or simply forgetting to turn things off.
How this impacts business:
- Idle resources and overprovisioning inflate bills: Unused EC2 instances, unattached EBS volumes, or underutilized RDS databases silently accumulate costs every month.
- No visibility means poor forecasting: Without consolidated billing, tagging strategies, or cost anomaly detection, finance teams struggle to track usage or plan budgets effectively.
- Inefficient architecture increases long-term TCO: Choosing the wrong storage class (e.g., using Amazon S3 Standard when Infrequent Access would suffice) or not using auto-scaling can lead to high operational overhead.
MSP Solution: A Cloud MSP or an AWS partner helps SMBs establish financial discipline on AWS from day one. They set up detailed tagging policies, budgets, and alerts using AWS Budgets, Cost Explorer, and AWS Cost Anomaly Detection. MSPs also implement architectural optimizations. This includes auto-scaling groups, rightsizing recommendations, and Amazon S3 lifecycle policies to match consumption to actual demand. They review architecture regularly and guide adoption of Savings Plans, Reserved Instances, or spot instances where appropriate, aligning cloud spend with business value and preventing bill shock.
5. Scaling and performance bottlenecks
As an SMB’s user base grows or application workloads increase, their cloud infrastructure must scale seamlessly to maintain performance and reliability. However, designing for elasticity, managing service quotas, and ensuring availability across regions or Availability Zones (AZs) is complex. Without proactive planning, systems become vulnerable to traffic spikes or component failures.
How this impacts business:
- Downtime or degraded performance during peak loads: Inability to handle traffic surges can crash applications or lead to sluggish experiences.
- Loss of revenue and brand reputation: Users expect responsive services; delays or outages can result in churn, cart abandonment, or lost transactions.
- Reactive scaling leads to inefficiencies: Without automated scaling or forecasting, teams scramble to provision resources manually, often too late or too expensively.
MSP Solution: Cloud MSPs and AWS partners design infrastructure with scalability and resilience at the core. They implement AWS Auto Scaling, Elastic Load Balancing (ELB), and Amazon EC2 Spot Fleets to adjust capacity dynamically based on demand. To ensure high availability, MSPs distribute workloads across multiple Availability Zones and architect for fault tolerance using services like Amazon Route 53, Amazon RDS Multi-AZ, and Amazon S3 cross-region replication.
They also use tools like AWS Fault Injection Simulator and Amazon CloudWatch Synthetics to simulate failures and proactively identify bottlenecks, ensuring the system performs reliably under pressure and scales as the business grows.
Why should SMBs choose Cloudtech as their AWS partner?
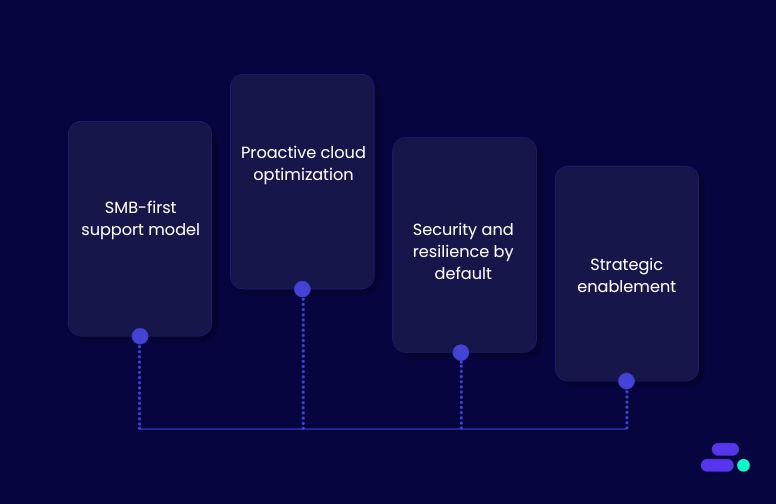
Behind every resilient, cost-efficient cloud operation is a partner who not only knows AWS, but knows how small and mid-sized businesses work. Cloudtech, an AWS Advanced Tier Services Partner focused exclusively on SMBs, delivers managed cloud services that go beyond maintenance. It helps companies scale with confidence, operate securely, and stay focused on what they do best.
Here’s how Cloudtech stands out as a Managed Service Provider for SMBs on AWS:
- SMB-first support model: 24/7 monitoring, incident response, and patch automation designed for lean teams, without bloated contracts or vendor lock-in.
- Proactive cloud optimization: Continuous performance, cost, and security tuning using AWS-native tools like Amazon CloudWatch, Trusted Advisor, and Config.
- Security and resilience by default: Built-in multi-AZ architecture, automated backups, IAM best practices, and GuardDuty for always-on protection.
- Strategic enablement: Cloudtech goes beyond ticket handling, delivering hands-on guidance, cost control, and knowledge transfer to help SMBs scale with confidence.
With a strong track record of helping small and mid-sized businesses succeed on AWS, Cloudtech brings enterprise-grade expertise with SMB-aligned execution. That means faster outcomes, clearer ROI, and a partner that grows with the business.
See how other SMBs have modernized, scaled, and thrived with Cloudtech’s support →
Wrapping up
Managing cloud environments in-house often means choosing between focus and fire drills. That’s why having the right AWS partner makes all the difference, not just by keeping systems running, but by driving smarter operations, lower costs, and faster innovation.
What makes Cloudtech different is its SMB-first approach to managed services. It is proactive, cost-aware, and aligned to business goals. With deep AWS expertise and a track record of success, they don’t just support cloud transition, they help SMBs thrive on it.
Ready to simplify operations and scale with confidence? Discover how Cloudtech’s managed services can power your next phase of growth.
FAQs
1. How is Cloudtech different from a traditional managed service provider (MSP)?
Unlike traditional MSPs that focus on legacy infrastructure and ticket-based support, Cloudtech is a cloud-native AWS Advanced Tier Partner. Their model emphasizes automation, scalability, and continuous improvement. Cloudtech’s team designs and manages environments using AWS best practices, including auto-scaling, serverless orchestration, and proactive monitoring, enabling SMBs to move faster, stay secure, and evolve continuously without being held back by legacy IT processes.
2. Is managed cloud support from Cloudtech affordable for small and mid-sized businesses?
Yes. Cloudtech’s services are built specifically for SMBs and are designed to be cost-effective without compromising quality. Instead of one-size-fits-all contracts, they offer flexible, outcome-based support tiers. Clients only pay for what they need, resulting in better ROI, reduced cloud waste, and faster access to cloud benefits.
3. What kind of support does Cloudtech offer outside regular working hours?
Cloudtech offers proactive 24/7 cloud monitoring and alerting for critical workloads as part of its managed services model. Using AWS-native tools like Amazon CloudWatch, AWS Config, and CloudTrail, the Cloudtech team ensures that infrastructure performance, availability, and security are continuously tracked, even outside standard business hours. While real-time issue detection is automated, any critical incidents are escalated based on agreed SLAs. For SMBs without in-house night or weekend coverage, this provides confidence that their environments are being actively observed, even when their team is offline.
4. How does Cloudtech help optimize and control AWS costs over time?
Cloudtech takes a proactive approach to cloud cost management. Their team continuously monitors usage with AWS Cost Explorer, Trusted Advisor, and CloudWatch metrics, identifying opportunities to rightsize infrastructure, reduce waste, and apply appropriate pricing models like Savings Plans and Reserved Instances. By aligning spend with business goals, Cloudtech ensures SMBs stay lean, predictable, and financially efficient on AWS.
5. Will SMBs still retain control and visibility over their AWS environment with Cloudtech?
Absolutely. Cloudtech promotes a shared ownership model. Clients retain full access, visibility, and governance over their AWS accounts. As part of every engagement, Cloudtech provides clear documentation, monitoring dashboards, and knowledge transfer to ensure internal teams are empowered, not sidelined. Their goal is to enhance the client’s capabilities, not replace them, offering expert guidance while keeping businesses in the driver’s seat.

Demystifying serverless: How do modern apps run without servers?
Serverless architecture is a cloud-native model where developers build and run applications without managing servers. Instead of provisioning or maintaining infrastructure, services like AWS Lambda automatically execute code in response to events and scale based on real-time demand. This frees up time and resources, making it especially valuable for small and medium-sized businesses (SMBs).
For example, a healthcare SMB can use AWS Lambda, API Gateway, and Amazon S3 to build a serverless patient intake system that handles forms, stores records, and sends notifications, without managing servers. This cuts infrastructure costs by over 60%, boosts data availability, and simplifies HIPAA compliance, letting teams focus on care, not maintenance.
This article walks through the fundamentals behind serverless architecture, the AWS services enabling it, and how it empowers SMBs to innovate efficiently and securely.
Key takeaways:
- Serverless cloud computing runs code on AWS with no servers to manage, billing only for actual execution.
- Core stack: event‑driven functions (FaaS), managed back‑end services (BaaS), and auto‑scaling data pipelines that link front‑end and back‑end.
- Best suited to bursty or asynchronous workloads like APIs, ETL, real‑time analytics, and IoT, where SMBs need quick releases and minimal ops overhead.
- Key trade‑offs like cold‑start delays, runtime limits, monitoring complexity, and potential vendor lock‑in are mitigated by least‑privilege IAM, encrypted data, and robust observability.
- Cloudtech guides SMBs through a five‑phase AWS roadmap, delivering secure pipelines, compliant data lakes, and GenAI‑ready foundations.
How does serverless architecture work? A simple breakdown
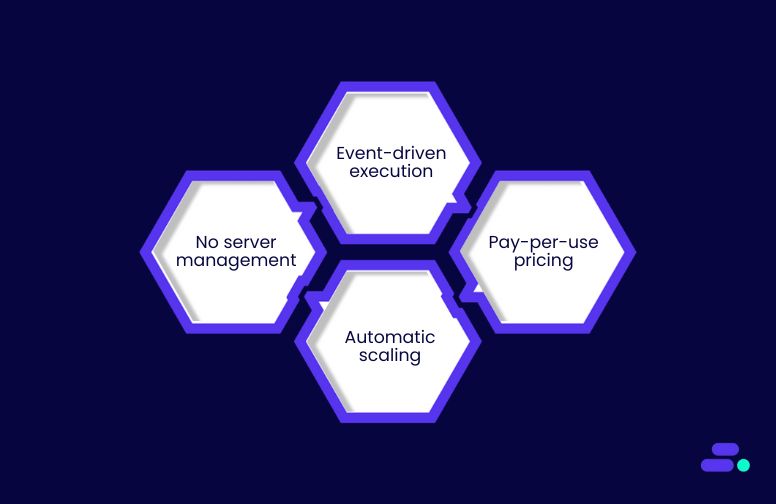
Serverless architecture is a cloud-native model where the cloud provider (like AWS) automatically manages the infrastructure. Instead of provisioning servers, scaling compute, or handling maintenance tasks, developers simply write and deploy code. Serverless apps are built to run inside short-lived, stateless containers such as AWS Lambda, which are triggered by specific events and shut down after execution.
Unlike traditional apps that run continuously, serverless apps execute only when needed, like when a user makes a request or a file is uploaded. This event-driven, on-demand execution model helps SMBs stay lean and agile, eliminating idle resource costs and manual scaling.
The key characteristics of serverless apps include:
- No server management: All infrastructure is managed by the cloud provider
- Event-driven execution: Code runs only in response to specific triggers
- Automatic scaling: Resources scale up or down with workload changes
- Pay-per-use pricing: SMBs charged only for actual compute time used
This model significantly benefits SMBs by speeding up development, reducing operational burden, and aligning cloud costs directly with usage.
Serverless also simplifies how frontends and backends interact. Web and mobile apps can invoke backend functions directly through services like Amazon API Gateway, enabling real-time communication without the need for persistent server infrastructure. These backend functions, running on AWS Lambda, can process data, call APIs, or store outputs in services like Amazon S3 or DynamoDB, all without manual scaling or server setup.
There are multiple types of serverless computing that serve different layers of the application stack. Each plays a distinct role in simplifying development and reducing infrastructure management:
- Function-as-a-Service (FaaS): Runs discrete, event-driven functions without persistent infrastructure. (e.g., AWS Lambda)
- Backend-as-a-Service (BaaS): Offers managed services for common backend needs like auth, storage, and databases. (e.g., Amazon Cognito, AWS Amplify)
- Serverless databases: Scale automatically and require no server maintenance. (e.g., Amazon DynamoDB, Aurora Serverless)
- Serverless containers: Containers that run and scale without manual provisioning. (e.g., AWS Fargate)
- Serverless edge computing: Executes functions closer to users to reduce latency. (e.g., AWS Lambda@Edge)
To see where FaaS fits within the broader cloud landscape, it helps to compare it with other service models. FaaS offers maximum abstraction, where developers write only the function logic, and the cloud handles the rest. Other models offer varying levels of control and responsibility:
Combining the right serverless components allows SMBs to reduce complexity, scale on demand, and build modern applications faster, all while keeping costs predictable and operations lightweight.
How can SMBs run applications on serverless architecture?
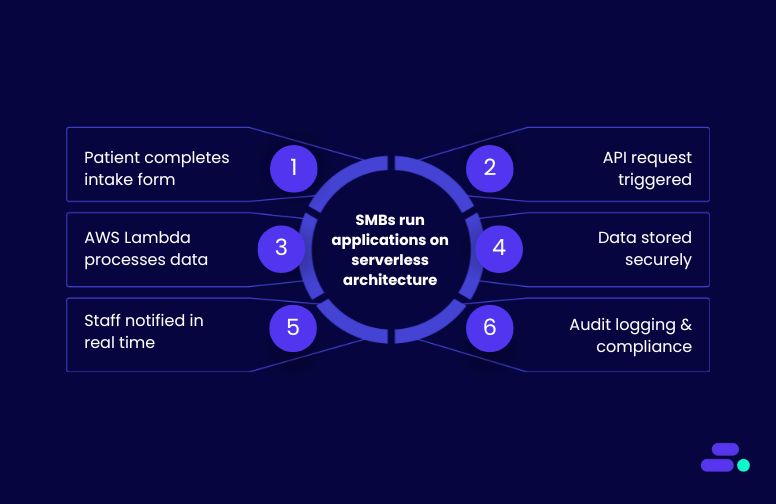
Serverless apps run in response to events, like form submissions or file uploads, using managed cloud services. Instead of operating on always-on servers, each component executes on demand, scales automatically, and requires no infrastructure management. Services like AWS Lambda, API Gateway, and DynamoDB handle compute, APIs, and data, so developers can focus on functionality, not infrastructure.
Consider a healthcare SMB modernizing its patient intake process. Using AWS serverless tools, it builds an app that collects patient data online, validates it, stores it securely, notifies staff in real time, and logs activity for compliance, all without managing a single server.
Step 1: Patient fills out the online intake form
The journey begins when a patient opens the clinic’s website or mobile app to complete a digital intake form. The form collects essential details like name, symptoms, insurance info, and optional document uploads.
The frontend of the application is serverless and static, hosted on:
- AWS Amplify for rapid development and deployment of web/mobile apps
- Or Amazon S3 with CloudFront for secure, low-latency static hosting
All content is served via a global CDN, ensuring speed and availability across regions. The serverless frontend allows instant scaling and simplified deployment without maintaining web servers.
Step 2: Form submission triggers an API request
When the patient submits the form, the data is sent to the backend using HTTPS. But instead of routing to a traditional server, the request is handled by a serverless API endpoint.
Amazon API Gateway acts as the secure entry point:
- It accepts, validates, and routes incoming API calls
- It supports throttling, authentication (e.g., via Amazon Cognito), and monitoring
- It integrates directly with AWS Lambda without requiring server infrastructure
API Gateway offloads the complexity of managing and securing APIs, helping SMBs launch secure backends faster.
Step 3: AWS Lambda processes the incoming data
The API call triggers a Lambda function, which contains the core logic for processing the patient submission. The function performs multiple tasks in milliseconds:
- Validates input (e.g., required fields, data types, document size)
- Performs lightweight logic (e.g., checking symptom severity, tagging high-priority cases)
- Formats data for storage or additional processing
- Lambda runs in an isolated, ephemeral container, spinning up only when triggered and shutting down after execution
- It scales automatically per request, ensuring zero performance lag under load
Lambda allows SMBs to run secure, scalable backend logic without provisioning compute infrastructure.
Step 4: Data is stored in secure, scalable storage
Once validated, patient information and documents need to be stored securely for later retrieval and processing.
Amazon DynamoDB is used for storing structured data:
- Patient name, symptoms, contact info, and form metadata
- Fast, scalable NoSQL database with automatic scaling and low-latency performance
- Supports fine-grained access control and encryption at rest
Amazon S3 stores unstructured data like:
- Uploaded documents (insurance cards, test results)
- Each file can be encrypted using SSE-S3 or SSE-KMS for HIPAA-compliant storage
These services offer scalable, pay-as-you-go storage that complies with healthcare data regulations and eliminates the need for physical servers or database licenses.
Step 5: Clinic staff is notified in real time
Once the form is submitted and data is stored, the system triggers a notification to the clinic’s admin or triage team.
A second Lambda function or AWS Step Functions orchestrates the post-submission flow:
- Determines priority based on patient symptoms
- Sends alerts via Amazon SNS (email or SMS) or posts to a Slack channel
- Optionally logs an entry into a clinic-facing dashboard using a service like Amazon AppSync (GraphQL-based real-time API)
Real-time communication ensures clinics can act on urgent cases immediately, improving patient outcomes and operational efficiency.
Step 6: Audit logging and compliance
Every API call, function execution, and data access is logged for auditing and compliance, which is crucial in healthcare where regulations like HIPAA require full traceability.
Amazon CloudWatch captures:
- Lambda invocation logs, function errors, and performance metrics
- Alarms can be set for anomalies or failures
AWS CloudTrail tracks:
- API Gateway calls
- IAM usage and access events
- Data changes or actions performed by clinic staff or applications
Built-in logging and audit trails help SMBs meet regulatory obligations without building custom monitoring systems.
By using AWS serverless tools, the healthcare SMB builds a scalable, secure, and event-driven patient intake system that:
- Launches faster than traditional web apps
- Costs less to run and maintain
- Automatically adapts to traffic spikes (e.g., flu season or viral outbreak)
- Provides a seamless, responsive experience for patients
- Keeps operations compliant without a dedicated DevOps team
This allows them to outpace competitors who are stuck in legacy hosting models, enabling rapid innovation, real-time care delivery, and higher patient satisfaction.
Also Read: Building Modern Data Streaming Architecture on AWS
5 ways serverless helps SMBs outpace competitors
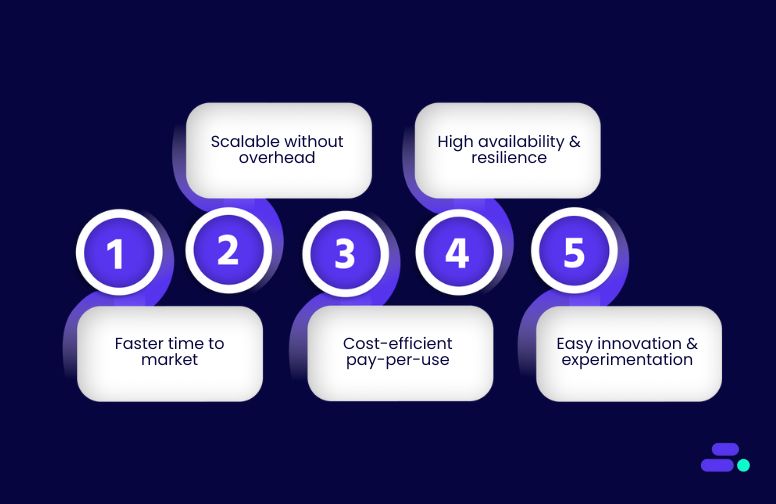
SMBs can’t afford to be slowed down by traditional infrastructure models. Serverless architecture offers them a strategic edge, leveling the playing field with enterprise-grade scalability, agility, and efficiency, all without the heavy investment.
Serverless architecture helps SMBs move faster, do more with less, and stay ahead of the competition.
1. Accelerated time to market
Serverless allows developers to focus entirely on business logic rather than infrastructure. With services like AWS Lambda, teams can deploy new features or entire services in hours instead of weeks. This agility is critical when competing against larger players with more resources.
For example, a regional e-commerce SMB uses AWS Lambda and Amazon API Gateway to roll out flash-sale features during festive seasons. Because there’s no infrastructure setup delay, the business can respond to market trends and customer demands within days, gaining a first-mover advantage in local markets.
2. Enterprise-grade scalability without the overhead
Serverless architectures scale automatically with user demand. Whether it’s ten users or ten thousand, services like AWS Lambda, Amazon DynamoDB, and Amazon S3 adjust instantly without needing manual provisioning or load balancer configuration.
For example, a telehealth startup built its appointment and consultation app using AWS Lambda and Amazon DynamoDB. During a sudden spike in demand (e.g., a local flu outbreak), the system scaled automatically to handle thousands of concurrent users, without performance dips or IT intervention.
3. Radical cost efficiency with pay-per-use
SMBs often struggle with budget constraints. Serverless removes the need for idle infrastructure spend. Businesses only pay for what they use. Every millisecond of execution is billed, not the time the server sits idle.
For example, a bootstrapped fintech firm replaces its legacy backend with AWS Lambda-based microservices. Instead of paying for always-on servers, it now only incurs charges when functions are triggered. This can be during customer logins, transactions, or report generation. This shift cuts monthly infrastructure costs by over 65%, allowing funds to be reinvested in product development.
4. Built-in high availability and resilience
Serverless apps automatically inherit the availability and fault-tolerance of the cloud platform. AWS services distribute functions across multiple availability zones, reducing the risk of downtime or single points of failure.
For example, a digital document management SMB serving law firms builds its workflow engine using AWS Lambda, Step Functions, and S3. Even during regional outages or traffic surges, the system continues operating smoothly, ensuring clients can access time-sensitive documents without interruption, an advantage over competitors with legacy on-prem systems.
5. Frictionless innovation and experimentation
Serverless lowers the barrier to trying new ideas. There’s no upfront infrastructure cost, no long deployment cycles, and failures don’t tie up resources. Teams can run experiments, A/B tests, or new services quickly and kill them just as easily if they don’t work.
For example, a media startup experiments with a personalized recommendation engine using AWS Lambda, Amazon Personalize, and Amazon API Gateway. The team deploys it to a small user group, tests engagement, and iterates based on real-time feedback. Because it’s serverless, there’s no infrastructure lock-in or cost risk, unlike competitors who need months of planning before launching similar features.
To fully realize the benefits of serverless architecture, SMBs need more than just cloud tools. They need a clear strategy and experienced guidance. That’s where Cloudtech comes in.
How does Cloudtech support secure serverless data modernization?
For SMBs adopting serverless cloud computing, success depends on both secure workloads and a modern data foundation. Cloudtech combines these with AWS-native solutions designed for scale, speed, and compliance.
- Streamlined, secure data pipelines: Cloudtech designs event-driven data pipelines using AWS Lambda, Glue, and Kinesis, enabling real-time processing without server management. These architectures are built with security-first principles, including role-based access and audit logging.
- Scalable storage and analytics: Using Amazon S3, Redshift, and Aurora, Cloudtech creates data lakes and warehouses that handle growth, concurrency, and cost-efficiency, crucial for SMBs scaling up without infrastructure overhead.
- Compliance-ready by design: Whether it’s HIPAA, FINRA, or internal governance, Cloudtech ensures data architectures meet regulatory requirements through native AWS tools like CloudTrail, AWS Config, and IAM.
- GenAI-ready architecture: Cloudtech prepares data environments for future generative AI use cases, ensuring clean, structured inputs and scalable backend support.
- Human-centric implementation model: Through a five-stage process—Engage, Discover, Align, Deliver, Enable—Cloudtech tailors modernization strategies to each SMB’s goals, ensuring long-term security, usability, and performance.
This approach ensures that SMBs not only adopt serverless securely but also build a data infrastructure that supports ongoing innovation and growth.
Conclusion
For SMBs, embracing serverless architecture is a strategic move toward speed, efficiency, and long-term agility. By removing the burden of infrastructure management, serverless frees up teams to focus on what truly matters: building great products, responding to customers faster, and scaling without friction.
But realizing this potential requires more than just picking the right AWS services, it takes the right approach. That’s where Cloudtech helps SMBs move from complex, costly on-prem systems to streamlined, serverless environments that support faster innovation, lower overhead, and lasting competitive advantage.
If your business is ready to modernize and move faster, serverless is the smarter path forward—and Cloudtech is here to help you take it. Connect today with Cloudtech!
FAQs
1. Is serverless cloud computing a good fit for growing SMBs?
es. Serverless is ideal for SMBs that want to scale efficiently without managing infrastructure. It offers automatic scaling, high availability, and pay-as-you-go pricing, making it a smart option for businesses with evolving workloads and limited IT resources.
2. Can serverless be used in compliance-heavy industries like healthcare or finance?
Absolutely. When configured properly, AWS serverless services support industry regulations such as HIPAA, FINRA, and GDPR. Built-in tools like AWS IAM for access control, AWS CloudTrail for auditing, and AWS Config for compliance tracking help ensure secure and standards-aligned deployments.
3. Can serverless integrate with existing legacy systems?
Yes. Serverless functions can be triggered via APIs, queues, or event streams, making them compatible with most legacy environments. This allows businesses to gradually modernize without disrupting existing systems or workflows.
4. How does serverless affect cloud costs for SMBs?
Serverless pricing is based on actual usage, which can significantly reduce costs for applications with intermittent or unpredictable demand. However, for consistently high workloads, other models may be more cost-effective. The key is choosing serverless where it offers the most operational and financial value.
5. What kind of support does Cloudtech provide throughout the serverless transition?
Cloudtech offers end-to-end support, from initial AWS assessments to designing, deploying, and optimizing serverless applications. Their certified architects help SMBs build secure, scalable systems and provide training, documentation, and long-term support to ensure ongoing success.