Resources
Find the latest news & updates on AWS

Cloudtech Has Earned AWS Advanced Tier Partner Status
We’re honored to announce that Cloudtech has officially secured AWS Advanced Tier Partner status within the Amazon Web Services (AWS) Partner Network!
We’re honored to announce that Cloudtech has officially secured AWS Advanced Tier Partner status within the Amazon Web Services (AWS) Partner Network! This significant achievement highlights our expertise in AWS cloud modernization and reinforces our commitment to delivering transformative solutions for our clients.
As an AWS Advanced Tier Partner, Cloudtech has been recognized for its exceptional capabilities in cloud data, application, and infrastructure modernization. This milestone underscores our dedication to excellence and our proven ability to leverage AWS technologies for outstanding results.
A Message from Our CEO
“Achieving AWS Advanced Tier Partner status is a pivotal moment for Cloudtech,” said Kamran Adil, CEO. “This recognition not only validates our expertise in delivering advanced cloud solutions but also reflects the hard work and dedication of our team in harnessing the power of AWS services.”
What This Means for Us
To reach Advanced Tier Partner status, Cloudtech demonstrated an in-depth understanding of AWS services and a solid track record of successful, high-quality implementations. This achievement comes with enhanced benefits, including advanced technical support, exclusive training resources, and closer collaboration with AWS sales and marketing teams.
Elevating Our Cloud Offerings
With our new status, Cloudtech is poised to enhance our cloud solutions even further. We provide a range of services, including:
- Data Modernization
- Application Modernization
- Infrastructure and Resiliency Solutions
By utilizing AWS’s cutting-edge tools and services, we equip startups and enterprises with scalable, secure solutions that accelerate digital transformation and optimize operational efficiency.
We're excited to share this news right after the launch of our new website and fresh branding! These updates reflect our commitment to innovation and excellence in the ever-changing cloud landscape. Our new look truly captures our mission: to empower businesses with personalized cloud modernization solutions that drive success. We can't wait for you to explore it all!
Stay tuned as we continue to innovate and drive impactful outcomes for our diverse client portfolio.


Cloud migration and modernization: which one should SMBs choose?
As businesses look to scale, improve efficiency, and cut costs, they face the challenge of deciding which path to take. Cloud migration lets them shift existing applications and infrastructure to the cloud, often with minimal changes. On the other hand, cloud modernization requires re-architecting applications to fully ebrace cloud-native technologies for improved performance, scalability, and flexibility.
Choosing the right strategy is crucial, as it impacts long-term business growth, operational efficiency, and the ability to stay competitive. This blog explores both options, helping SMBs understand when and why each strategy is the best fit for their specific needs.
Key takeaways:
- Strategy depends on business goals: SMBs should choose between migration and modernization based on their immediate needs, budget, and long-term vision.
- Migration is fast, modernization is future-ready: Migration offers quick wins with minimal changes, while modernization enables scalability, performance, and cloud-native advantages.
- Modernization delivers long-term ROI: While costlier upfront, modernization helps SMBs reduce technical debt and unlock sustainable growth through optimized cloud infrastructure.
- AWS supports both approaches: Tools like Amazon EC2, RDS, Lambda, and Migration Hub help SMBs execute either strategy effectively with minimal disruption.
- Cloudtech reduces risk and complexity: With phased execution, compliance guardrails, and outcome-driven planning, Cloudtech ensures a smooth transition to the cloud.
Knowing the key distinctions between cloud migration and modernization
While both strategies involve moving to the cloud, they differ significantly in terms of scope, cost, and the benefits they deliver. Migration offers a quicker, more straightforward solution for businesses that need to move their systems to the cloud with minimal disruption, particularly in industries like retail or logistics.
On the other hand, modernization is better suited for SMBs in sectors like healthcare or finance where long-term scalability, security, and the ability to innovate are essential.
Knowing these differences allows SMBs to make informed decisions that align with their current priorities and future growth:

What factors should SMBs consider when choosing between migration and modernization?

Choosing between cloud migration and modernization depends on the specific needs of an SMB and their industry.
For instance, a small e-commerce store may migrate its order processing system to Amazon EC2 to reduce hardware costs and scale during high-traffic seasons. Migration helps these businesses get to the cloud quickly, improving performance and flexibility with minimal disruption.
A healthcare SMB with an EHR system might modernize by moving to a microservices architecture on Amazon ECS for better performance, integration, and compliance with healthcare regulations like HIPAA. Modernization allows these industries to meet growing demands, enhance security, and support innovation.
To help SMBs make an informed choice, it’s important to consider several factors, including business goals, budget, current infrastructure, and growth potential.
1. Assess business goals and priorities
Start by aligning the migration or modernization strategy with business goals. If the goal is to quickly scale operations or reduce IT costs, migration might be the best option. However, if the goal is to future-proof the business with a fully optimized, cloud-native infrastructure, modernization should be the priority.
Example: A healthcare SMB using an outdated EHR system may decide to migrate the system to Amazon EC2 for immediate scalability during periods of high patient volume.
However, if the healthcare provider aims for long-term growth and needs a system that can scale dynamically with minimal manual intervention, modernization might involve re-architecting the system with AWS Lambda and Amazon RDS to handle patient data more efficiently.
2. Determine budget and resource availability
If an SMB has a limited budget or tight timeline, migration is often the most viable option. It allows businesses to quickly move to the cloud without major changes to existing systems.
Example: A retail SMB using an on-premises CRM system could migrate it to Amazon EC2 to reduce hardware maintenance costs and enable scalability during peak seasons.
Benefits:
- Quick and cost-effective solution.
- Reduces the need for managing physical infrastructure.
- Immediate scalability without disrupting business operations.
Drawback: Does not fully utilize cloud-native features like Amazon RDS or AWS Lambda, potentially leading to higher ongoing costs for scaling or maintenance in the future.
On the other hand, SMBs with more resources for a long-term strategy may prefer modernization to take full advantage of cloud-native benefits. This approach requires more time and investment but provides better long-term scalability, performance, and cost savings.
Example: A growing e-commerce SMB may decide to modernize its platform by refactoring its architecture. They can migrate to Amazon RDS for a fully managed, scalable database and integrate AWS Lambda for automated functions like real-time inventory updates and customer notifications.
Benefits:
- Enables better performance and scalability through Amazon RDS and AWS Lambda.
- Reduces the need for manual updates and optimizes resource usage, leading to long-term cost savings.
- Prepares the system for future growth with cloud-native technologies.
Drawback: More resource-intensive and requires careful planning and expertise for implementation.

3. Evaluate current infrastructure and technical debt
If legacy systems are outdated and can’t easily integrate with modern cloud services, modernization might be necessary. For SMBs with technical debt, modernizing their infrastructure allows them to align with cloud-native capabilities, enabling better performance and scalability.
Example: An SMB in finance running a legacy accounting system on on-premises servers may face scaling issues and high maintenance costs. Migration to Amazon EC2 provides immediate benefits, but doesn't address inefficiencies in the system.
Modernizing the accounting system by moving to Amazon RDS for databases and using AWS Lambda for automated accounting processes can help reduce maintenance costs, improve performance, and prepare the business for future growth.
4. Scope long-term scalability and growth
For SMBs with aggressive growth plans, modernization is often the better choice. Cloud-native features like auto-scaling, serverless computing, and managed services ensure that the system grows with the business, supporting future demands.
Example: A healthcare SMB that anticipates a surge in patient data and usage may need more than just scalable cloud infrastructure. While migration to Amazon EC2 provides scalability, modernizing to a microservices architecture on Amazon ECS, coupled with Amazon RDS for managed databases, allows the business to handle large-scale data processing efficiently and cost-effectively.
Ultimately, there are several key questions that SMBs need to consider before deciding between the two options:
- Is the system built for future scaling? If scaling is crucial, modernization enables systems to handle growth efficiently. For example, a logistics SMB may modernize its fleet management system to support real-time processing during peak traffic.
- How quickly is growth expected? SMBs anticipating rapid growth should consider modernization. For instance, refactoring an e-commerce platform’s backend using Amazon CloudFront and AWS Auto Scaling can manage traffic spikes during seasonal sales.
- How efficiently does the current infrastructure support operations? If legacy systems are inefficient, modernization is essential. An SMB with an outdated ERP system may benefit from integrating cloud-native features like Amazon RDS or AWS SQS to improve performance and scalability.
- What resources and timeline are available for this change? For faster, cost-effective cloud adoption, migration is ideal. However, if long-term scalability and optimization are the goal, modernization requires more time and resources to achieve greater efficiency and security.
Choosing the right strategy—migration or modernization—depends on the SMB’s current needs and future vision. Carefully considering the business goals, budget, and growth potential will help guide the decision for a successful cloud journey.
Why is AWS the key to successful cloud migration and modernization projects?
As the leading cloud provider, AWS offers a comprehensive suite of integrated tools for migration, modernization, and scalability, including Amazon EC2, AWS Lambda, and Amazon RDS. Its vast global infrastructure ensures low latency and high availability, while security features like AWS IAM and AWS Shield protect sensitive data. AWS’s flexible pricing model optimizes costs based on usage, offering both immediate savings and long-term efficiency for SMBs.
This combination of comprehensive services, strong security, and cost-effectiveness makes AWS a superior choice for SMBs looking to migrate and modernize their cloud infrastructure.
AWS tools for migration and modernization:

1. AWS Migration Hub
Provides a central location to track the progress of migrations across various AWS services. It simplifies the migration process by offering visibility and control over multiple migrations at once.
Key features: It integrates with other AWS tools like AWS Application Discovery Service and AWS Database Migration Service (DMS), allowing SMBs to track migration tasks and troubleshoot in real time.
SMBs can use Migration Hub to manage the entire migration lifecycle, from planning and assessment to the execution and post-migration phase, ensuring a smooth transition with real-time monitoring and reporting.
2. AWS Database Migration Service (DMS)
It helps businesses migrate databases to the cloud with minimal downtime and zero data loss. This is especially critical for SMBs needing to move large, complex datasets efficiently.
Use case: When replatforming or modernizing a legacy system, DMS helps businesses seamlessly migrate databases to Amazon RDS or Amazon Aurora without major changes to the application.
This service minimizes operational disruption during database migration, offering continuous data replication and ensuring smooth transitions with minimal downtime.
3. AWS Server Migration Service (SMS)
It automates and accelerates the migration of on-premises servers to AWS. It is designed to handle rehosting (lift and shift) strategies.
Use case: SMBs can use SMS to quickly move entire server workloads to Amazon EC2, enabling scalability without the need for manual configuration.
SMS streamlines the migration of on-premises servers to EC2 instances, reducing the time and effort needed for migration while ensuring compliance and security.
AWS services for replatforming, refactoring, and modernization:

1. Amazon EC2 (Elastic Compute Cloud)
It offers scalable computing capacity in the cloud. For replatforming, it provides the flexibility to migrate applications while optimizing them for cloud performance.
Use case: SMBs can move legacy applications to EC2 instances without re-architecting the system, allowing them to benefit from the cloud’s scalability and flexibility. For replatforming, EC2 instances can be customized to integrate with services like Amazon RDS for managed databases and Amazon CloudWatch for monitoring.
2. Amazon RDS (Relational Database Service)
It is a managed database service that automates database management tasks such as backups, patching, and scaling. This is particularly useful for replatforming or refactoring legacy systems with inefficient database management.
Use case: When SMBs move to Amazon RDS, they offload the management of databases, which improves scalability and performance while ensuring high availability. For refactoring, businesses can integrate Amazon Aurora to take advantage of cloud-native database features, reducing operational overhead and improving system performance.
3. AWS Lambda
It enables serverless computing, which means businesses can run code without provisioning or managing servers. It is essential for refactoring applications to fully optimize them for the cloud by using event-driven architectures.
Use case: By integrating Lambda, SMBs can reduce infrastructure costs and improve scalability. For example, businesses can refactor their traditional monolithic applications to microservices, each running as an independent Lambda function, leading to faster innovation and enhanced flexibility.
4. Amazon ECS (Elastic Container Service)
It is a fully managed container orchestration service that allows businesses to deploy, manage, and scale containerized applications.
Use case: For refactoring, SMBs can break down monolithic applications into microservices running as containers. This enables seamless scaling and management of workloads across distributed infrastructure, providing greater efficiency and fault tolerance.
5. AWS CloudFormation
It automates the process of setting up AWS resources using infrastructure as code. This service is critical for businesses modernizing their infrastructure by codifying cloud resource management.
Use case: SMBs can use CloudFormation to manage the entire lifecycle of their cloud resources, from provisioning to configuration, ensuring that infrastructure is repeatable, scalable, and secure.
By combining these AWS services with the expertise of an AWS partner, SMBs can not only transition to the cloud seamlessly but also ensure optimized performance, reduced operational costs, and robust security and compliance.
How does Cloudtech help SMBs successfully migrate or modernize with AWS?
With a focus on aligning business goals, technical readiness, and long-term scalability, Cloudtech helps businesses move to the cloud with confidence while optimizing performance and reducing operational risks. It offers a structured, outcome-driven approach to both cloud migration and modernization.
What Cloudtech delivers:
- Business-aligned cloud planning: Cloudtech starts with business goals, whether it's reducing costs, improving SLAs, or scaling operations. It uses AWS tools like Migration Evaluator to create outcome-driven migration strategies.
- Smart workload discovery: Using AWS discovery tools, Cloudtech maps applications, dependencies, and licensing to eliminate surprises and avoid costly migration issues.
- Team-wide cloud readiness: Cloudtech ensures both technical and non-technical teams are cloud-ready, from enabling autoscaling to helping finance teams manage AWS spend with Savings Plans and RIs.
- Built-in security & compliance: Security and compliance are built in from day one, with preconfigured IAM roles, KMS encryption, and AWS Config rules. This is ideal for SMBs in healthcare, fintech, and other regulated sectors.
- Low-risk, phased migration: Cloudtech avoids the “big bang.” Migrations are phased, observable, and reversible, using AWS CloudWatch and X-Ray to ensure control and confidence at every step.
Their structured, cloud-first approach minimizes risk and sets businesses up for success in the cloud.

Conclusion: achieving cloud success with the right strategy
Whether migrating legacy systems, replatforming for better performance, or modernizing for long-term scalability, choosing the right strategy is vital for SMBs. Without a clear plan, businesses risk inefficiencies, security gaps, and rising operational costs.
This is where having an AWS partner like Cloudtech can make a difference. It combines deep technical expertise with a business-first mindset, ensuring that each migration or modernization strategy aligns with the specific goals and challenges of SMBs.
Cloudtech doesn’t just migrate or modernize; it focuses on optimizing performance, security, and scalability using AWS tools like Amazon EC2, Amazon RDS, and AWS Lambda.
Ready to transform your infrastructure with the right cloud strategy? Connect with Cloudtech.
FAQs
1. How can businesses know when it's the right time to shift from migration to modernization?
The right time to modernize comes when the business starts to experience limitations in scalability, performance, or agility with the cloud infrastructure post-migration. If a business has migrated and finds that their systems are not taking full advantage of cloud-native capabilities like auto-scaling, serverless, or managed services, it's a sign that modernization will help them unlock greater efficiency and growth.
2. What specific challenges should SMBs expect when modernizing legacy applications?
Modernizing legacy systems involves re-architecting the infrastructure and codebase, which can be resource-intensive. The challenges often include refactoring complex applications, ensuring data consistency during the transition, and managing legacy dependencies. SMBs must also ensure that internal teams are trained to handle the cloud-native technologies being introduced, such as microservices or serverless computing.
3. How can Cloudtech help minimize downtime during the migration or modernization process?
Cloudtech uses a phased migration strategy, incorporating robust rollback plans, testing phases, and automation tools like AWS CloudFormation to ensure smooth transitions. By running parallel systems and performing testing on smaller workloads before full migration, Cloudtech minimizes disruptions to business operations and ensures systems remain available throughout the process.
4. What are the long-term financial implications of choosing migration over modernization, or vice versa?
Migration offers short-term cost savings but may incur higher long-term costs due to inefficiencies in utilizing cloud-native features. Modernization, although more expensive upfront, leads to long-term savings by optimizing performance, scaling more efficiently, and leveraging cloud-native tools like Amazon RDS and AWS Lambda. Cloudtech helps SMBs evaluate these trade-offs by conducting TCO (Total Cost of Ownership) analysis to align financial goals with the chosen strategy.
5. How does Cloudtech ensure that compliance requirements are met during cloud migration or modernization?
Cloudtech ensures that SMBs meet industry compliance standards by embedding security and compliance measures from day one. This includes configuring IAM roles, KMS encryption, and AWS Config rules for data protection. For regulated industries like healthcare and finance, Cloudtech ensures compliance with standards such as HIPAA or GDPR through AWS Security Hub and continuous monitoring tools, giving SMBs confidence that their cloud infrastructure meets all regulatory requirements.

A cloud migration roadmap that minimizes downtime and cost
For small and mid-sized businesses (SMBs), downtime and unexpected costs during a cloud migration can directly impact customer trust and operating margins. Every hour of disruption or unplanned spend can ripple through sales, support, and service delivery.
Consider a regional logistics firm that moved their core dispatch system to the cloud. The migration was meant to improve performance, but missing configuration details might have caused delays and unplanned rework. Drivers probably lost access to real-time updates for nearly a day. The team could have eventually resolved the issues but only after customer complaints and cost overruns.
Stories like this are common, not because the cloud fails, but because the planning phase gets rushed or underestimated. This article outlines the essential steps for building a practical cloud migration roadmap that minimizes downtime and cost.
Key takeaways:
- Choose strategy over speed: Minimizing downtime and cost begins with clear goals, realistic timelines, and cross-functional alignment.
- Inventory before migrating: A detailed workload and dependency map prevents missed connections and migration surprises.
- Build the foundation first: Set up secure, scalable AWS infrastructure before migrating to reduce rework and security gaps.
- Test with low-risk systems first: Early trial runs on internal apps help teams refine tools and processes before critical workloads.
- Track and adjust post-migration: Cost optimization and performance tuning don’t end at go-live. Ongoing visibility ensures long-term value.
A step-by-step cloud migration roadmap to minimize downtime and cost on AWS

Most cloud migration plans focus on simply moving workloads from on-prem to the cloud as quickly as possible. While that approach can work, it often leads to downtime, overspending, and unexpected technical setbacks.
This roadmap takes a different path. It’s designed specifically to help SMBs avoid disruption and control costs by starting with detailed workload discovery, early cost forecasting, and phased deployment strategies.
Instead of rushing to migrate everything at once, it emphasizes workload prioritization, pre-migration testing, and built-in rollback options. The result is a more predictable, efficient, and financially sound migration experience.
Phase 1: Define business goals and baseline costs
Clear goals give the migration purpose, whether it’s reducing overhead, improving uptime, or speeding up delivery. Without them, teams risk moving workloads blindly. Reviewing current usage and costs upfront also prevents budget surprises, since cloud pricing often differs from on-prem.
Recommended actions:
- Use AWS Migration Evaluator (formerly TSO Logic) to analyze on-prem workloads and generate a Total Cost of Ownership (TCO) report.
- Map business goals to technical outcomes (e.g., reducing infrastructure management by 30%, improving SLA response times, etc.).
- Involve finance and operations early to set guardrails around cloud spend.
Example: A small business runs 12 Windows servers on-premises to support internal applications. At first glance, all seem necessary. But after running AWS Migration Evaluator, they discover that four of the servers are consistently underutilized. They consolidate those workloads onto fewer instances and choose Amazon EC2 Reserved Instances for the rest. As a result, their projected cloud bill drops by 35%, with no impact on application performance.
Phase 2: Inventory and dependency mapping
Not all workloads should move at once, or even move at all. Some systems are deeply connected through shared databases, file paths, or scheduled jobs that aren’t obvious at first. If those links aren’t mapped ahead of time, migrating one app could break another.
For SMBs with lean IT teams, that kind of disruption can cause customer-facing issues and internal delays. By identifying dependencies early and sequencing migrations carefully, businesses can avoid downtime and reduce rework.
Recommended actions:
- Run AWS Application Discovery Service on key workloads to automatically detect interdependencies, usage patterns, and configuration data.
- Supplement discovery with AWS Systems Manager Inventory for complete metadata collection.
- Group workloads by priority and risk—e.g., move non-customer-facing apps first.
Example: A business plans to migrate its ERP system, assuming it’s self-contained. But during pre-migration checks with AWS Application Discovery Service, they uncover hardcoded file paths linking the ERP to an internal reporting database. If they’d migrated the ERP alone, reporting would have failed. Instead, they adjust their plan to migrate both systems together, avoiding broken reports and unplanned downtime.

Phase 3: Design a modular landing zone
This phase is about setting the stage before any workloads shift. Creating a secure, scalable foundation in AWS means building the environment that workloads will eventually run in without moving anything yet. This includes configuring identity and access (IAM), setting up networking (like VPCs and subnets), and putting guardrails in place with AWS Config, CloudTrail, and security controls like encryption and logging.
For SMBs, this is critical because it ensures the migration won’t hit security, compliance, or scalability issues later, when fixes are harder and more expensive to implement. By preparing a well-structured landing zone up front, businesses gain the flexibility to migrate at their own pace while keeping operations secure and costs predictable.
Recommended actions:
- Set up a landing zone using AWS Control Tower, which automatically configures account structure, logging (AWS CloudTrail, Config), and guardrails for IAM, network, and encryption
- Define workload-specific VPCs to isolate environments (e.g., dev/test/prod) with AWS VPC and Transit Gateway.
Tip: Use Service Control Policies (SCPs) to limit unapproved services and avoid cost drift.
Example: A business is preparing to move multiple workloads to AWS. Instead of building everything at once, they set up a modular landing zone using AWS Control Tower. They define separate accounts for dev, test, and production, each with its own guardrails for security and compliance. This structure lets them onboard teams gradually, control costs per environment, and roll out workloads in stages. As a result, they reduce risk, improve visibility, and make future expansions easier to manage.
Phase 4: Migrate low-risk, low-impact workloads first
This step helps SMBs validate their migration approach in a low-risk setting. By starting with a non-critical workload like an internal wiki, staging app, or reporting dashboard, teams can test IAM roles, automation scripts, tagging standards, and rollback procedures without disrupting customer-facing services.
It’s also a chance to fine-tune collaboration between IT, operations, and finance. If something goes wrong, the impact is minimal, and the lessons learned will strengthen the process for more complex cutovers down the line.
Recommended actions:
- Start with internal systems like file shares, intranet apps, or non-prod staging environments.
- Use AWS Application Migration Service (MGN) for lift-and-shift workloads with continuous replication to minimize cutover downtime.
- Enable Amazon CloudWatch to monitor metrics and AWS X-Ray for request tracing.
Example: During migration, an SMB team is unsure how long downtime will last or whether their cutover plan will hold. They choose to start with their internal documentation portal and use AWS MGN for replication. Through multiple test runs, they refine the process, fix minor misconfigurations, and confirm rollback options. By the time they execute the live cutover, downtime drops from a projected 2 hours to just 10 minutes, giving them a proven method they can now apply to higher-risk systems.
Phase 5: Optimize before scaling
This phase gives SMBs the opportunity to validate their assumptions about performance and cost in a low-risk environment. Before migrating high-impact systems like customer-facing applications or core databases, teams can monitor how cloud resources are being used.
They can also identify underutilized instances and apply optimizations such as Amazon EC2 Auto Scaling, AWS Savings Plans, or storage tiering in Amazon S3. These early adjustments not only improve efficiency but also prevent costly misconfigurations from being repeated at scale.
Recommended actions:
- Use AWS Compute Optimizer to right-size instances based on actual usage.
- Tag resources using AWS Resource Groups for cost tracking (e.g., Environment:Prod, Owner:Finance).
- Convert long-running workloads to Savings Plans or Reserved Instances after 1–2 months of baseline usage.
- Store cold data in Amazon S3 Glacier or Intelligent-Tiering to reduce storage costs.
Example: A business completes its migration and notices that its batch reporting jobs only run overnight. Initially, their Amazon EC2 instances stay on 24/7, incurring unnecessary costs. After reviewing usage patterns, they implement AWS Instance Scheduler to automatically start the instances in the evening and stop them in the morning. This simple change cuts their monthly compute bill by 40% without impacting performance.
Phase 6: Migrate critical workloads with fail-safe paths
This phase ensures that when SMBs move critical applications, like ERPs, customer portals, or payment systems, they have a controlled and reversible process. Implementing blue/green or canary deployments with AWS CodeDeploy allows changes to be tested in parallel without disrupting users.
Pre-migration testing environments mirror production setups using AWS CloudFormation or Elastic Beanstalk, while rollback paths (such as RDS snapshots or AMI backups) ensure services can be quickly restored if issues surface. This reduces downtime risk and builds team confidence during cutover.
Recommended actions:
- Use blue/green deployment strategies with AWS CodeDeploy or Amazon ECS with Application Load Balancer to validate changes before cutting traffic over.
- Pre-stage Amazon RDS snapshots and test read-replicas before switching production.
- Use Route 53 weighted routing to shift traffic gradually and enable rollback if issues arise.
Example: An e-commerce company moves its shopping cart and payment services using blue/green deployment on Amazon ECS. After deployment, a latency issue appears in the new version. Because the previous version is still live in the background, the team quickly redirects traffic back, restoring normal performance in under five minutes and avoiding any visible impact for customers.
Phase 7: Post-migration validation and continuous optimization
After migration, SMBs need to confirm that systems are stable, performant, and financially efficient. This involves monitoring workloads using AWS CloudWatch and reviewing spend through AWS Cost Explorer and Budgets. Tagging resources by team or function helps track usage trends, while tools like AWS Compute Optimizer recommend better instance types or scaling configurations.
Post-migration reviews also surface hidden issues, such as unused resources or underperforming services, so adjustments can be made before they impact user experience or monthly bills.
Recommended actions:
- Conduct a Well-Architected Review using the AWS Migration Lens.
- Enable AWS Budgets with alerts tied to department or project spend.
- Set up AWS Config Rules to enforce compliance (e.g., encryption, tagging, backup policies).
- Review usage monthly and adjust instance sizes, storage tiers, or autoscaling policies.
Example: A healthcare SMB notices that several Amazon EC2 instances sit idle during non-peak hours, especially for lightweight tasks like sending appointment reminders and processing intake forms. These workloads don’t require full-time compute resources, yet running them on Amazon EC2 racks up unnecessary costs.
By shifting these functions to AWS Lambda, the company moves to an event-driven model where compute runs only when triggered. This not only reduces infrastructure complexity but also eliminates idle-time billing, cutting their monthly cloud spend by 50% while maintaining fast, reliable performance for routine tasks.
For SMBs, cloud migration doesn’t need to mean disruption or ballooning budgets. By using AWS-native tools at each stage, from discovery to optimization, businesses can migrate with precision.
How Cloudtech helps businesses migrate with the least downtime and cost?
Cloudtech helps SMBs transition to AWS with precision, control, and minimal disruption. As an AWS Advanced Tier Services Partner, it combines deep technical expertise with a phased, business-aligned approach to ensure migrations stay on budget and avoid costly downtime.
- Cost-aware planning from day one: Cloudtech begins with a discovery process that maps current infrastructure and clarifies the business case for migration. Using AWS Migration Evaluator, AWS Pricing Calculator, and TCO analysis, the team identifies cost-saving opportunities such as right-sizing underutilized instances or switching to managed services like Amazon RDS or AWS Fargate.
- Pre-migration architecture built for stability: Before any workload is moved, Cloudtech sets up secure, compliant landing zones using AWS Control Tower or custom VPC architectures. This includes pre-configured IAM roles, logging (AWS CloudTrail, VPC Flow Logs), encryption via AWS KMS, and automated guardrails through AWS Config Rules. This minimizes rework and security missteps later.
- Smart sequencing and cutover design: Migrations are phased based on business criticality, not just technical readiness. Lower-risk systems are moved first to test tooling and processes. For critical workloads, Cloudtech designs cutovers using blue/green deployments, database replication (DMS), and health checks via Route 53 or ALB. This limits user-facing downtime and allows fast rollback if needed.
- Automation and Observability at Every Stage: Cloudtech leverages automation through AWS Systems Manager, AWS CloudFormation, and AWS CodePipeline to reduce human error and speed up deployment. Every stage is monitored using Amazon CloudWatch dashboards, alarms, and X-Ray traces to detect issues early and maintain performance visibility during the transition.
- Post-Migration Optimization and Cost Control: Once workloads are live, Cloudtech conducts follow-up reviews using AWS Cost Explorer and Compute Optimizer. Teams are coached on using AWS Budgets, tagging policies, and Reserved Instances or Savings Plans where appropriate, ensuring that ongoing spend aligns with business goals and usage patterns.
With this structured methodology, Cloudtech helps SMBs migrate without overextending resources, losing service continuity, or letting cloud costs spiral. The result is a smoother transition that unlocks the benefits of AWS while preserving business stability.

Closing thoughts
For SMBs, minimizing downtime and cost during cloud migration isn’t about moving fast, it’s about moving right. The businesses that succeed aren’t necessarily the ones with the most engineers, but the ones with a clear roadmap, realistic expectations, and a strong technical foundation.
Cloudtech helps SMBs build that foundation. From cost modeling and inventory to secure AWS landing zones and rollout design, every phase is handled with precision. Businesses migrating with Cloudtech gain more than technical support. They gain predictability, stability, and a real path to value.
Ready to migrate with minimal downtime and cost? Connect with Cloudtech.
FAQs
1. How can a business tell when it’s truly ready to begin migrating?
Migration readiness goes beyond having cloud accounts and tools in place. It requires alignment across teams, a clear inventory of workloads, documented dependencies, and contingency plans. If decisions are still driven by guesswork or deadlines rather than data, the organization may benefit from pausing to strengthen its foundation.
2. Should SMBs bring in external specialists for the migration?
Temporary support from cloud specialists can prevent costly errors, especially for SMBs without deep internal cloud experience. These professionals can help define sequencing, apply best practices, and coach internal teams. It will also ensure a smoother transition and better long-term outcomes.
3. What operational metrics should be tracked during and after migration?
It’s important to monitor more than just uptime. Businesses should track system utilization, cost per service, application latency, and error rates to detect performance issues or budget drift early. Tools like Amazon CloudWatch and AWS X-Ray help surface these metrics, but success depends on defining clear KPIs from the start.
4. How long does a typical SMB migration take when downtime and cost are priorities?
Timelines vary based on environment complexity. A straightforward lift-and-shift for a few applications might take several weeks. More integrated systems, especially in regulated sectors, may require phased migrations over several months. A slower, controlled migration often results in fewer disruptions and lower rework costs.
5. Is it possible to roll back to on-premise infrastructure if cloud operations become too expensive?
Rollback is technically possible in some cases, especially if workloads remain portable (e.g., containerized or VM-based). However, cloud-native services like AWS Lambda or Amazon RDS reduce reversibility. Instead of planning for a return to on-prem, businesses should focus on cost controls, such as monitoring, right-sizing, and budget alerts to keep operations sustainable in the cloud.

Refining the cloud migration project plan with this strategic guide
Cloud adoption keeps growing, but many businesses are still struggling to get it right. Gartner predicts that by 2028, 25% of organizations might not be satisfied with their cloud investments, mostly because of unclear planning, missed steps, or rising costs that weren’t accounted for early on.
For SMBs, this challenge is especially familiar. Teams are juggling daily operations while trying to modernize, often without dedicated cloud specialists or endless resources. The goals, including better performance, flexibility, and cost control are clear, but the path can feel murky without a practical and strategic plan.
That’s where a well-structured migration project plan makes the difference. It helps businesses start strong, avoid missteps, and stay aligned as they move to the cloud. This article breaks down the essential planning steps every SMB should take to make cloud migration smoother, smarter, and worth the investment.
Key takeaways:
- Start with strategy, not speed: Successful migrations begin with clear business goals, realistic timelines, and stakeholder alignment across departments.
- Dependencies and inventory matter: Hidden ties between workloads can cause costly surprises. Use AWS Application Discovery Service to surface them.
- Costs don’t optimize themselves: Budget guardrails, right-sizing, and AWS cost planning tools help avoid overspending post-migration.
- Security and compliance should lead, not follow: Early configuration of IAM, encryption, and compliance rules prevents risk in regulated environments.
- Small teams still need structure: Even lean SMB teams benefit from phased plans, rollback paths, and cloud-readiness assessments to stay in control.
Why do cloud migration projects fail and how to avoid it?
For many small and mid-sized businesses, cloud migration is a step toward a more flexible, efficient, and resilient operation. But the process is rarely as straightforward as it seems. Migrations tend to go off track not because the cloud doesn’t deliver, but because a few critical planning steps get skipped early on. And when internal teams are already managing multiple responsibilities, even small gaps can lead to delays or disruptions.
The good news is that most of these challenges are avoidable. With the right preparation, and by making full use of AWS’s built-in planning tools, SMBs can build the clarity and control needed to migrate with confidence.
1. Surfacing hidden dependencies early
Many business applications appear self-contained at first, but closer inspection reveals complex interconnections, including shared databases, background jobs, or hardcoded file paths that aren’t immediately visible.
For example, an inventory app might rely on a local database used by the finance system, or trigger nightly batch jobs stored on a legacy server. If those aren’t identified before migration, the app may fail in production, causing delays or data sync issues across teams.
How AWS helps:
- AWS Application Discovery Service scans on-prem environments to identify these dependencies, capturing traffic flows, system connections, and performance data.
- AWS Migration Hub serves as a central dashboard to organize discovery results, track migration readiness, and monitor progress across multiple systems.
2. Setting realistic timelines
Speed is often a priority, but rushing through migration steps can lead to problems that are harder and more expensive to fix later.
For instance, lifting and shifting a web application without validating DNS settings or load balancer configurations might result in outages or degraded performance after cutover. This will force teams to troubleshoot under pressure instead of addressing those issues in a controlled pre-migration phase.
What works better:
- Start with a pilot workload to establish timing, validate tools, and get the team comfortable with the process.
- Use Amazon CloudWatch and AWS X-Ray during and after the migration to monitor performance and catch potential bottlenecks early.
- Allow time post-migration for fine-tuning and feedback, not just for the cutover itself.
3. Bridging silos between teams
In many SMBs, roles overlap. IT, compliance, and operations may all be managed by the same small team. That makes coordination even more important.
For example, a team might move customer data to the cloud before verifying encryption or access controls, only to face compliance issues later. Aligning technical and regulatory requirements early helps avoid rework and keeps the migration on solid ground.
To maintain alignment:
- Host short, focused planning sessions that include all key stakeholders.
- Use the AWS Well-Architected Tool – Migration Lens to guide planning across security, cost, reliability, and operational efficiency. The tool offers a shared structure for discussion, even when cloud expertise is limited.
- Appoint a clear migration coordinator, whether internal or through a partner, to own progress tracking and decision-making.
For SMBs, cloud planning is about establishing enough structure to move forward without avoidable surprises. A thoughtful plan doesn’t slow down progress, but helps teams stay aligned, minimize risk, and respond quickly when issues arise.
With the right AWS tools and a clear process, even lean teams can manage migration successfully, on their terms and timeline.
What SMBs often miss in cloud migration planning

Many SMBs approach cloud migration with clear goals, but fall into traps that stem from rushing or skipping the foundational steps. These aren’t just technical oversights. They're planning missteps that directly impact timelines, budgets, and business continuity.
Mistake 1: Assuming cloud costs will auto-optimize
Many teams expect the cloud to be cost-efficient by default, only to be surprised by unexpectedly high bills. Workloads left running 24/7, over-provisioned instances, or untagged resources are frequent culprits.
Fix it early:
- Use the AWS Pricing Calculator to model costs before migration.
- Set up AWS Budgets and Cost Explorer to monitor usage post-migration.
- Utilize Savings Plans or Spot Instances where appropriate.
Example: Consider a company that migrated its analytics jobs to Amazon EC2 without reviewing runtime patterns. The workloads continued running 24/7, even though most data processing only happened during business hours. This led to unnecessary compute costs.
With upfront planning, they could have analyzed usage trends, implemented scheduled execution, and applied AWS Savings Plans. That would’ve aligned their infrastructure with actual demand and avoided tens of hours of idle compute time each week, saving over 35% in monthly costs.
Mistake 2: Leaving security and compliance until the end
Security and compliance are often treated as post-launch concerns, especially when IT teams are lean. But cloud-native environments require different access controls, logging policies, and data protection strategies from on-prem setups.
Fix it early:
- Use the AWS Well-Architected Tool (Security and Operational Excellence lenses) to assess gaps before migrating.
- Set up AWS Identity and Access Management (IAM) roles and policies in parallel with planning.
- Enable AWS CloudTrail for auditing and AWS Config for resource compliance checks from day one.
Example: An SMB migrated its internal file storage to Amazon S3 but left the default permissions unchanged. As a result, some buckets were unintentionally accessible to the public, something the team only discovered during a later audit.
With better planning, they could have enabled Amazon S3 Block Public Access settings during setup and used AWS Config Rules to continuously monitor bucket permissions. This would have prevented the exposure risk entirely and ensured compliance from day one.
Mistake 3: Over-focusing on tools, under-investing in process
It’s easy to lean on tools and automation to drive the migration forward. But without defined processes for testing, handoffs, or rollback, even well-executed technical steps can cause business disruption.
Fix it early:
- Use AWS Migration Hub to centralize visibility into workload progress and dependencies.
- Define operational checklists that include manual handoffs, team signoffs, and escalation paths.
- Run dry-runs or blue/green tests using AWS Elastic Beanstalk or Amazon Route 53 traffic shifting.
Example: A team deployed a new backend service on Amazon ECS without establishing a rollback plan. When a critical bug appeared post-launch, recovery took several hours, disrupting users and internal operations.
If rollback procedures had been part of the original plan, they could have used blue/green deployments with AWS CodeDeploy to validate changes in a staging environment and switch traffic safely. That would have enabled fast rollback with minimal downtime and user impact.
Mistake 4: Ignoring failure recovery strategies
Many SMBs fail to consider what happens if the migration doesn’t go as planned. Without a clear failure recovery strategy, teams may struggle to recover quickly, leading to prolonged disruptions and costly downtimes.
Fix it early:
- Plan for failure scenarios and establish detailed recovery protocols.
- Use Amazon Machine Images (AMIs) or CloudFormation templates to facilitate quick recovery.
- Leverage AWS Backup or snapshots for data and system state protection.
Example: A company migrated its application to the cloud without planning for potential failures. During the migration, an unexpected issue caused a service outage. Without a well-defined recovery plan in place, the team spent hours troubleshooting and manually fixing the problem.
Had they implemented automated recovery procedures and taken regular snapshots of critical systems, they could have easily rolled back to a stable state, minimizing downtime and preventing disruption to their users.
Good planning isn’t about slowing down but reducing friction and making sure teams don’t have to clean up after the fact.
What does a good migration project plan include?
Once the early risks are surfaced and the right people are in the loop, the next step is to build structure around how the migration will actually unfold. For SMBs, this isn’t about over-engineering. It’s about creating just enough clarity to avoid costly surprises and keep teams moving in sync.
1. Prioritizing what actually drives the business
At this stage, the focus shifts from infrastructure mapping to business context. It's not just about what runs where but what matters most to operations.
- Which systems directly affect customer experience or revenue?
- What can tolerate a brief disruption—and what can’t?
- Are there time windows that are off-limits for cutovers?
This context shapes both the migration order and the fallback strategy. Without it, even well-executed migrations can create unintended ripple effects across teams.
For example: A scheduling tool might seem low-priority on paper, but if it’s tied to customer booking or billing, moving it without a fallback could interrupt revenue. On the other hand, a test environment with limited dependencies might be a great first move to prove out the process.
2. Turning alignment into shared ownership
Stakeholder alignment is important, but real progress comes from clearly assigning responsibilities within the plan.
- Who owns each application, and who signs off after migration?
- Who’s monitoring cost, performance, or compliance post-cutover?
- What’s the communication path if something doesn’t go as expected?
Clear ownership reduces friction during execution, especially in smaller teams where responsibilities often overlap.
For instance: If a CRM is being migrated, someone from sales or support should be involved in sign-off, not just IT. Similarly, finance should know who’s monitoring spend in the new environment, and what the thresholds are for raising flags.
Having named owners avoids the “who's responsible for this?” scramble when issues arise after go-live.
3. Guardrails for budget and usage
Cloud costs can climb quickly if no one’s watching. Good planning includes clear visibility into expected usage and ways to keep spend in check. At the planning stage, it’s important to:
- Forecast usage patterns, not just resource specs
- Identify workloads suited for Savings Plans or Reserved Instances
- Set budgets and alerts early using tools like AWS Budgets and Cost Explorer
When usage scales quickly post-migration, these controls prevent budget surprises and help SMBs stay in control.
For example: An SMB plans to move a reporting application to the cloud and assumes it will need to run around the clock. But after reviewing usage patterns, they realize most reports are generated during business hours. By adjusting the instance schedule and applying AWS Savings Plans, they avoid unnecessary costs and reduce projected monthly spend, savings that wouldn’t have been possible without that planning step.
Recommended AWS tools:
- AWS Pricing Calculator for up-front modeling
- Cost Explorer and Budgets to track actual usage and set alerts
4. Smart sequencing of workloads
Trying to migrate everything at once introduces unnecessary risk. A stronger approach is to group workloads into waves, starting with those that are low-risk but high-value for testing the process.
- Begin with internal tools or systems with rollback flexibility
- Schedule customer-facing or regulated workloads with more margin for error
- Build in checkpoints between waves to validate performance and user experience
This phased approach reduces pressure on internal teams.
For example: An SMB might begin with a low-risk system like an internal documentation tool or intranet site. Migrating this type of workload first gives the team a chance to test access controls, automation workflows, and rollback procedures in a controlled environment. Lessons learned here can then be applied to more critical systems, like customer-facing apps, reducing risk and improving execution as the migration scales.
5. Readiness checks that go beyond infrastructure
Technical readiness is only part of the picture. Teams also need to be ready to support the new environment from day one.
Case in point: An SMB moved its helpdesk system to AWS, but overlooked post-migration access controls. End users were locked out for hours, and support tickets stalled during a key product launch. The migration itself succeeded, but operational readiness wasn't in place.
Smart steps to include:
- Run a mock cutover or simulate failover
- Set up Amazon CloudWatch dashboards and alarms ahead of time
- Ensure team members know who to call and what steps to take if things break
A good migration plan doesn’t just reduce risk, it saves time, lowers cost, and helps everyone stay focused on the bigger goal: building a cloud foundation that actually works for the business.
For SMBs that need a structured path, Cloudtech offers migration planning support that’s tailored to business goals, compliance needs, and real-world constraints.
Questions to answer before migration begins
Successful cloud migrations rarely start with technology. They start with clarity. For SMBs, answering a few key questions upfront can prevent delays, miscommunication, and costly surprises. These help ensure the migration effort aligns with real business priorities.
- What is driving the migration? Whether it’s cost savings, improved scalability, compliance, or retiring aging infrastructure, a clear objective helps teams stay focused and make informed trade-offs during execution.
- Which systems are business-critical, and what level of risk is acceptable? Not every workload needs the same treatment. Understanding which applications directly impact customers or revenue helps prioritize efforts and define acceptable downtime windows.
- Who needs to be involved across departments? In SMBs, IT teams might work closely with operations, finance, and compliance. Including cross-functional input early helps avoid delays caused by missed requirements or misaligned expectations.
- Is the proposed timeline realistic? Migration mostly runs in parallel with day-to-day responsibilities. Timelines that don’t reflect team capacity or testing requirements can create unnecessary pressure and increase the chance of errors.
- How will success be measured? Whether it's performance, cost reduction, uptime, or agility, defining specific outcomes makes it easier to assess progress and adjust the approach if needed.
These questions form the foundation of a plan that works. SMBs that take the time to clarify their goals, constraints, and stakeholders often move faster and with fewer disruptions once execution begins.
How Cloudtech helps businesses strategically plan their migration?

Cloudtech helps SMBs build a clear, execution-ready migration strategy, one that aligns business goals with technical realities from day one.
- Business-first discovery and prioritization: Cloudtech starts with outcome-driven planning, using AWS tools like Migration Evaluator and TCO calculators to align goals with KPIs such as cost reduction, SLA improvement, or deployment speed.
- Workload assessment and dependency mapping: Through tools like AWS Application Discovery Service and Systems Manager Inventory, Cloudtech uncovers hidden dependencies, outdated components, and unused resources that could otherwise slow down or inflate migration.
- Cloud readiness beyond IT: Cloudtech evaluates team readiness, billing fluency, and shared responsibility alignment to ensure the broader organization, not just IT, is prepared for the shift.
- Security and compliance by default: IAM, encryption, logging, and guardrails are built in from the start, especially valuable for SMBs in regulated industries.
- Phased execution with rollback safety: Instead of high-risk cutovers, Cloudtech uses modular migration patterns with test automation and rollback checkpoints to maintain control at every stage.
With this structured approach, SMBs gain confidence that their cloud investment will deliver real business outcomes.
Closing thoughts: planning is the first migration milestone
For SMBs, a clear migration plan isn’t extra work. It’s the first real step toward reducing risk, controlling costs, and unlocking long-term cloud value. The right strategy surfaces risks early, aligns teams, and sets the stage for execution that actually delivers.
Cloudtech supports SMBs with a structured, AWS-aligned approach, from clarifying goals and auditing workloads to assessing team readiness and designing secure, scalable landing zones. For businesses ready to migrate with confidence, Cloudtech helps turn well-built plans into tangible results.
Connect with Cloudtech to get started with your cloud migration project plan.
FAQs
1. Why does strategic planning matter if we’re just lifting and shifting?
Even simple migrations involve changes to infrastructure, access, and cost structure. Without proper planning, hidden dependencies or security gaps can lead to downtime or budget overruns. A solid plan helps SMBs stay in control and avoid surprises, no matter the migration method.
2. Can’t AWS tools handle most of the complexity automatically?
AWS offers great tools like Application Discovery Service, Migration Hub, and the Well-Architected Tool. But these tools need clear direction and context. They highlight issues and patterns, but decisions still need human oversight to prioritize and act.
3. How do we avoid overspending after migrating?
Unexpected costs often come from over-provisioned resources or a lack of usage visibility. SMBs can manage this by right-sizing workloads in advance, using Savings Plans or Reserved Instances where appropriate, and setting up AWS Budgets or Cost Anomaly Detection.
4. Is it safe to move core systems first?
Starting with critical systems adds risk. A better approach is to begin with low-impact workloads, like internal apps or documentation platforms. These early migrations help teams test processes and tools before touching high-risk environments.
5. What if our team doesn’t have deep cloud experience yet?
That’s common for many SMBs. It's important to assess team readiness as part of the planning process. Teams can upskill using AWS training resources, but outside help from partners like Cloudtech can also bridge early gaps and keep the project on track.

Avoid common pitfalls with this cloud migration readiness checklist
Cloud migration is full of promise, but it also comes with complexity. Studies show that up to 80% of migrations underperform when businesses skip the upfront planning. But for SMBs that take a structured, thoughtful approach, the cloud delivers real advantages, including agility, scalability, and long-term cost control.
Most SMBs approach cloud migration with clear goals, scalability, cost efficiency, or improved performance, but the process can feel overwhelming without a structured entry point. Before making technical decisions, it's important to take stock of existing infrastructure, surface hidden dependencies, and involve cross-functional teams early.
A pre-migration checklist gives businesses a practical way to reduce risk, align priorities, and set up a migration path that actually supports day-to-day operations. This article outlines the key questions every SMB should ask to ensure their migration starts strong, stays on track, and delivers lasting business value.
Key takeaways:
- Define business-aligned objectives before migration to ensure every step supports measurable outcomes.
- Inventory workloads thoroughly to avoid lifting unnecessary or obsolete systems into the cloud.
- Evaluate cloud readiness beyond technology, including team skills, workflows, and cross-functional alignment.
- Build security and compliance into the plan early, rather than patching vulnerabilities post-migration.
- Use a phased migration strategy with clear architecture and rollback paths to reduce disruption and ensure continuity.
Why does a pre-migration checklist matter for SMBs?
Cloud migration is most successful when treated as a coordinated transformation that brings every part of the business into alignment. With a clear readiness framework in place, teams can confidently set the stage for a smooth, strategic transition.
A pre-migration checklist serves several key purposes:
- Clarifies business and technical objectives: A checklist helps stakeholders align on outcomes early, so technical teams can design around them, not guess.
- Reduces risk of downtime or data loss: Mapping out which applications depend on which systems helps avoid breaking business-critical workflows during migration.
- Ensures stakeholder buy-in across teams: IT alone can’t drive cloud success. The checklist ensures everyone understands the scope, impact, and shared responsibilities before work begins.
- Establishes a baseline for cost and resource planning: It helps identify underused systems, workloads that can be retired, or apps that need refactoring. Businesses shouldn’t overspend on lift-and-shift mistakes.
- Surfaces compliance or integration gaps early: A structured checklist process flags gaps, such as missing encryption, logging, or third-party SLAs, before they become blockers later.
Ultimately, a pre-migration checklist is how SMBs move with intent. It turns a high-stakes transition into a strategic growth opportunity, and ensures teams aren’t solving problems after it’s too late to course-correct.
A pre-migration checklist for successful cloud transition
Consider two healthcare SMBs planning to migrate their legacy electronic health record (EHR) systems to AWS. One follows a structured pre-migration checklist, evaluating infrastructure, defining clear goals, mapping data flows, and identifying compliance requirements. The other dives in without fully considering app dependencies or security configurations.
The result? The first clinic experiences a smooth, phased migration with minimal downtime, meets HIPAA standards from the start, and quickly begins using AWS analytics tools to improve patient engagement. The second faces unplanned outages, broken integrations with third-party labs, and costly rework to fix compliance gaps.
SMBs that invest in readiness can move faster, avoid common pitfalls, and start realizing the benefits of cloud transformation sooner. A solid checklist is the foundation. The right partner makes it actionable.
1. Are businesses migrating for the right reasons?
Many SMB migrations stall or fail not because of technical missteps, but because there’s no clear ‘why’ behind the move. Cloud migration should directly support business goals such as reducing tech debt, improving system reliability, accelerating product delivery, or enhancing customer experiences.
Before writing a single line of code or provisioning cloud resources, leadership teams should define what success looks like. That might include KPIs like:
- 20% reduction in infrastructure maintenance costs
- Faster onboarding for new users or remote clinics
- Eliminating downtime during peak usage
Avoid “because IT said so” migrations:
When migration is driven solely by aging hardware or vendor pressure, teams often skip the foundational work needed to get value from the cloud. Stakeholders should agree on what the migration enables, be it automation, innovation, or compliance.
Watch for these warning signs:
- No TCO or ROI model: Costs are estimated based on lift-and-shift, not optimized AWS services (e.g., Amazon EC2 vs. AWS Lambda).
- Limited cross-team input: Finance, compliance, and customer teams aren’t involved in planning.
- Unclear migration scope: Critical workloads are lumped together without prioritization or business justification.
Example (Fintech SMB): A digital lending startup rushes to migrate its loan origination platform without aligning with business goals. It overlooks AWS data residency controls, impacting its ability to expand into new regions due to regulatory gaps. Meanwhile, a competitor takes time to define objectives, like reducing loan processing time using serverless backends and real-time analytics, designs an AWS-native architecture accordingly, and captures faster time-to-revenue post-migration.
How AWS partners like Cloudtech help: Cloudtech works with SMBs to validate business goals early in the process using AWS-native tools such as:
- AWS Migration Evaluator to assess on-prem TCO vs. cloud
- AWS Trusted Advisor to identify cost savings and security gaps
- Well-Architected Framework reviews to align plans with AWS best practices
This ensures the migration is driven by strategy, not guesswork, and that every step ties back to real business value.
2. Do businesses know what they’re migrating?
One of the most common reasons cloud migrations go over budget or underperform is because organizations don’t fully understand what’s running in their current environment. For SMBs, this step is critical. Without a comprehensive inventory of infrastructure, applications, and interdependencies, teams risk migrating outdated, unused, or tightly coupled workloads that don’t belong in the cloud or aren’t ready for it.
A full inventory is essential, not optional:
Every workload, VM, database, storage system, and license must be accounted for, along with the way each component is used across departments. This includes:
- User traffic patterns and usage frequency
- Integration dependencies (e.g., shared storage, authentication services)
- Compliance requirements and data residency obligations
- Support and maintenance ownership
AWS provides powerful tools to streamline this:
- AWS Migration Evaluator helps SMBs calculate cloud readiness and cost savings by analyzing on-prem usage patterns.
- AWS Application Discovery Service automatically maps server and network dependencies to avoid surprises.
- AWS Systems Manager Inventory collects OS, software, and config data across hybrid environments for better visibility.
Why discovery without validation leads to poor outcomes: Too many SMBs execute “lift and shift” projects without filtering out legacy clutter or mapping hidden dependencies. This leads to increased cloud costs and system failures post-migration. A better approach includes a pilot migration, where a low-risk workload (like a test environment or internal dashboard) is moved first to surface technical gaps.
Example (Healthcare SMB): A regional medical practice begins migrating its patient management system but fails to realize it relies on an on-prem directory service for authentication. As a result, staff are locked out of critical systems for hours. In contrast, another clinic that runs a pilot first detects the issue early and deploys AWS Directory Service to ensure seamless login functionality in the cloud environment.
Where AWS partners like Cloudtech come in: Cloudtech works closely with SMBs to lead structured discovery and validation phases. Their team uses AWS-native tooling and custom scripts to produce:
- A prioritized inventory of what should and shouldn’t move
- A dependency map highlighting key integrations and risks
- Recommendations on pilot candidates based on business impact
With this insight, Cloudtech ensures that SMBs migrate the right workloads, at the right time, in the right way, minimizing surprises and maximizing business value.
3. Have businesses evaluated cloud readiness beyond tech?
Migrating to the cloud is an operational shift that impacts every team. For SMBs, this means looking beyond application compatibility or compute requirements and asking: Are the people, processes, and policies truly ready to support a cloud-native operating model?
Even when the infrastructure is technically cloud-ready, unprepared teams or outdated workflows can lead to cost overruns, misconfigurations, and organizational friction.
Why this matters for SMBs:
- Ops teams often lack hands-on experience with cloud-native tooling like AWS Systems Manager or AWS CloudFormation.
- Finance and procurement may be unfamiliar with usage-based billing, reserved instance strategies, or cost tagging policies.
- Legal and compliance teams may not fully understand the AWS Shared Responsibility Model, particularly when it comes to HIPAA, PCI DSS, or SOC 2 alignment.
- Executive teams may underestimate the cultural and process shift needed, from quarterly release cycles to continuous delivery.
Without readiness across these functions, even technically sound migrations can fall short of delivering long-term value.
Common signals of incomplete cloud readiness:
- Relying on traditional ticketing-based provisioning instead of self-service or infrastructure as code.
- No internal policies for managing IAM roles, tagging strategy, or resource lifecycle.
- Cloud spend is viewed as a black box, with no mechanisms for forecasting or accountability.
- Business units lack understanding of cloud-native security or operational responsibility.
Example: A regional diagnostics lab prepares to move its EHR system to AWS. Its IT team is ready, but compliance leads haven’t reviewed AWS HIPAA-eligible services or data encryption protocols. Cloudtech steps in to conduct a tailored MRA, aligns departments with AWS compliance guidance, and delivers a phased training plan. The result: A secure, audit-ready migration with full stakeholder buy-in.
How Cloudtech helps SMBs build true cloud readiness: As an AWS Advanced Consulting Partner focused on SMBs, Cloudtech provides a structured readiness framework that spans people, platform, and process. This includes comparing managed service availability (e.g., Amazon HealthLake for healthcare, Amazon Comprehend for document processing in fintech), regional support, and long-term scalability.
4. Will security and compliance hold up under scrutiny?
Security and compliance can’t be retrofitted after cloud migration, especially for SMBs in regulated industries like healthcare and fintech. Without predefined guardrails, teams risk exposing sensitive data, misconfiguring access controls, or falling short of industry mandates such as HIPAA or PCI-DSS.
Instead, security and compliance should be designed into the migration plan from the outset. This means assessing readiness across identity management, data protection, network controls, and auditability.
Key readiness questions to ask:
- Has the business defined IAM roles with least-privilege access using AWS IAM Access Analyzer?
- Is data encryption enforced using AWS KMS or customer-managed keys across all storage and transit layers?
- Are AWS CloudTrail and AWS Config enabled to capture and track configuration changes across all AWS accounts?
- Does the business have AWS WAF rules and Amazon GuardDuty alerts in place to monitor real-time threats?
Why this matters for SMBs:
- Fintechs must ensure PCI DSS compliance for payment processing and secure audit logs for financial oversight.
- Healthcare providers must align with HIPAA, meaning encryption in transit and at rest, identity segmentation, and strong data residency controls.
- Even non-regulated SMBs are increasingly scrutinized by customers and partners on how they protect data, especially with rising ransomware and insider threats.
Common risks when security isn’t addressed up front:
- IAM policies are overly permissive (“admin: *”), making breaches more damaging.
- Encryption isn’t consistently enforced across Amazon S3, RDS, or EBS volumes.
- No audit trail is available because AWS CloudTrail wasn’t configured early.
- Developers use personal IAM users or access keys instead of roles.
- Misconfigured VPCs expose internal services to the public internet.
Example (Healthcare SMB): A multisite diagnostic center plans to move its EHR (Electronic Health Record) backend to AWS. Before migrating, it runs a readiness check and discovers that existing logs don’t meet audit requirements. By enabling AWS CloudTrail with centralized logging, encrypting data with AWS KMS, and configuring VPC endpoint policies to restrict data egress, they preemptively meet HIPAA audit controls before touching a single production workload.
How Cloudtech helps: Cloudtech helps SMBs establish “secure-by-design” AWS environments by preconfiguring identity boundaries, encryption policies, and compliance checks. With tools like AWS Config, IAM Policy Validator, and Security Hub, Cloudtech ensures every workload is built with audit readiness and threat resilience from day one.
5. Does the business have a partner plan in place?
Many SMBs underestimate the complexity of cloud migration until they're already knee-deep in execution. Without the right guidance, it's easy to overspend, misconfigure services, or overlook critical steps like rollback planning and workload sequencing.
Having an AWS partner in place early, not just during execution, can make the difference between a smooth migration and a drawn-out disruption. A qualified partner helps SMBs understand the architectural trade-offs, navigate AWS service options, and account for downtime, compliance, and team capacity.
What a good partner prevents:
- Overspending by rightsizing Amazon EC2 instances and recommending reserved capacity or serverless where appropriate.
- Downtime risks by sequencing migrations to include blue/green deployments or database replication.
- Team fatigue by automating tasks through CloudFormation or Systems Manager.
Example (Fintech SMB): A payment gateway provider attempts to migrate its transaction processor directly to AWS without a phased cutover. Lacking experience with Amazon RDS replication, they face unexpected downtime during DNS failover. A partner would have helped them build a hybrid architecture with real-time replication, pre-tested routing policies via Amazon Route 53, and a clear rollback plan, avoiding revenue loss during the switch.
Setting the foundation for long-term success: Once SMBs know what to migrate, why it matters, and who to involve, the final piece is ensuring that every box on the pre-migration checklist is actioned with the right expertise.
That’s where Cloudtech comes in, not just as a migration partner, but as a strategic guide through every phase of transformation.
How Cloudtech helps businesses fulfill the pre-migration checklist?
Cloudtech enables SMBs to move to AWS with a structured, outcome-focused approach. It ensures that every phase of cloud migration is backed by technical readiness, operational alignment, and long-term scalability.
- Strategic alignment through outcome-driven planning: Cloudtech begins with a business-first discovery process, aligning migration goals with measurable KPIs, like reducing operational overhead, improving SLAs, or accelerating deployment cycles. Using AWS Migration Evaluator and TCO tools, Cloudtech quantifies value and prioritizes workloads based on business impact, not just technical urgency.
- Deep workload assessment and dependency mapping: Before migration, Cloudtech performs a comprehensive workload inventory using AWS Application Discovery Service, Systems Manager Inventory, and custom telemetry. This uncovers hidden dependencies (e.g., on-prem authentication or EHR connectors), licensing constraints, and underutilized resources to avoid unnecessary lift-and-shift.
- Cloud readiness validation across teams and processes: Cloudtech assesses operational maturity beyond tech. It verifies whether workflows support autoscaling, finance teams understand AWS billing (Savings Plans, RI), and stakeholders are aligned on shared responsibility, ensuring the entire organization is cloud-ready.
- Pre-configured guardrails for security and compliance: Security and compliance are embedded from day one. Cloudtech pre-configures IAM roles, KMS encryption, AWS Config rules, WAF protections, and VPC flow logs, which is essential for SMBs in regulated sectors like healthcare and fintech.
- Modular, phased migration architecture with rollback safety: Avoiding risky “big bang” moves, Cloudtech designs modular landing zones and phased VPC rollouts with rollback plans, test automation, and observability using CloudWatch and X-Ray. Each stage is validated before progressing.
Together, these capabilities help SMBs migrate with confidence by minimizing risk, maximizing ROI, and ensuring cloud transformation delivers lasting business value.
Wrapping up
A successful cloud migration starts with asking the right questions. Without a clear plan, SMBs risk fragmented architectures, compliance gaps, and rising costs. A pre-migration checklist helps avoid those pitfalls by building a secure, scalable, and business-aligned foundation.
Cloudtech supports SMBs with a structured approach: from clarifying migration goals to auditing workloads, assessing team readiness, and designing AWS-compliant landing zones. By aligning strategy, surfacing hidden risks, and embedding cloud-native best practices, SMBs gain a springboard for growth and innovation.
Those ready to migrate with confidence can rely on Cloudtech to turn plans into real outcomes. Connect with Cloudtech to start the conversation.
FAQs
1. Why is a pre-migration checklist essential for SMBs?
It ensures all foundational elements, like identity management, workload dependencies, cost projections, and business SLAs, are evaluated before any code or data moves. This avoids surprises like unexpected latency, access issues, or budget overruns during execution.
2. How detailed should the initial workload inventory be?
Extremely detailed. The inventory should capture server specs, storage usage, network throughput, licensing constraints, OS versions, and app interdependencies. Tools that map communication patterns between workloads can also reveal hidden coupling that may affect re-architecture decisions.
3. What’s the risk of skipping security reviews before migration?
Without pre-migration security planning, businesses risk deploying workloads with permissive IAM roles, publicly exposed Amazon S3 buckets, or unencrypted data at rest/in transit. This can lead to compliance failures under HIPAA, PCI-DSS, or SOC 2, depending on the industry.
4. Can SMBs migrate incrementally without disrupting operations?
Yes. Incremental migration using blue/green deployments, AWS Landing Zones, or hybrid VPN/Direct Connect configurations ensures that DNS cutovers and service redirects are seamless. This approach allows rollback paths and avoids downtime for critical systems.
5. What if internal teams aren’t fully cloud-ready?
Cloud-native environments shift operational models, so teams need to understand concepts like auto scaling, managed services (e.g., RDS, Lambda), tagging strategies, and shared responsibility. Bridging skill gaps before the move is key to preventing post-migration drift or cost sprawl.

From on-prem to cloud: a practical migration roadmap for SMBs
Businesses migrating from on-prem to cloud save up to 31% in IT costs. Instead of pouring resources into legacy IT, they are investing in innovation, growth, and customer impact.
SMBs in healthcare and fintech are especially eager to make the change. For them, migrating to the cloud is more than just about staying ahead. Legacy on-premises systems introduce operational risks, including limited agility, fragmented data, and higher vulnerability to outages or compliance issues. The longer organizations delay modernization, the more these risks compound.
The good news is that AWS offers them a cost-effective and scalable foundation to modernize their infrastructure without disrupting business operations. This article explores how SMBs can move from on-premise to the cloud with a strategy that reduces cost, minimizes downtime, and sets the stage for long-term growth.
Key takeaways:
- Cloud migration is a business strategy, not just IT modernization: SMBs must align cloud goals with broader business outcomes to bring agility, cost savings, and growth.
- A structured roadmap ensures long-term sustainability: Phased execution, clear objectives, and AWS-native design help reduce risk and avoid rework.
- Post-migration optimization is critical: Tools like AWS CloudWatch, AWS Cost Explorer, and AWS Trusted Advisor help fine-tune performance and control costs.
- Ongoing governance keeps the cloud environment secure and compliant: Automated policies, tagging standards, and regular audits prevent drift and ensure accountability.
- Partnering with AWS experts like Cloudtech accelerates success: From planning to post-migration support, Cloudtech ensures every step achieves the required business value.
Why is migrating from on‑premise to the cloud crucial for SMB growth?
When SMBs cling to on‑premise systems, they inadvertently anchor themselves to legacy limitations. These include costly infrastructure refresh cycles, inflexible scaling, fragmented data silos, and manual maintenance. For growth-oriented SMBs, especially in regulated sectors like healthcare and fintech, this translates into slower innovation, operational inefficiencies, and a competitive disadvantage.
In contrast, cloud migration fosters a modern operating model:
- Scalable infrastructure on demand: Rather than investing in upfront hardware, SMBs can provision compute, storage, and networking resources precisely when needed. This flexibility supports bursts of demand (e.g., rapid growth, seasonal peaks) without wasted capacity or long procurement cycles.
- Significant cost gains: Studies show that migrating legacy workloads can reduce IT spend by a large margin. SMBs can reallocate savings toward hiring, product development, or customer acquisition, turning technology from a cost center into a growth driver.
- Improved agility and speed to market: Cloud-native architectures, automation tools, and continuous integration pipelines allow teams to roll out new features or services faster. This is especially valuable for customer-driven innovation in healthcare or fintech, where compliance requirements and regulatory timelines can otherwise slow progress.
- Strong foundation for future capabilities: Moving to AWS paves the way for advanced data analytics, GenAI workflows, and AI-enabled automation. SMBs can begin extracting insights from historical data, deploying predictive tools, or automating core processes without overhauling their stack again later.
- Enhanced resilience and reliability: Cloud infrastructure enables high availability through multi‑AZ and multi-region designs, managed backup/restore, and disaster recovery workflows that shift risk from downtime to continuity. SMBs that adopt resilient cloud architectures are better positioned to maintain uptime and trust, especially during disruptions or regulatory audits.
Ultimately, migrating to the cloud is a strategic shift. By moving beyond on‑prem legacy systems, SMBs gain agility, cost efficiency, scalability, and the transformational capabilities needed to compete and grow confidently in today’s digital economy.
A sustainable on‑prem to cloud migration roadmap
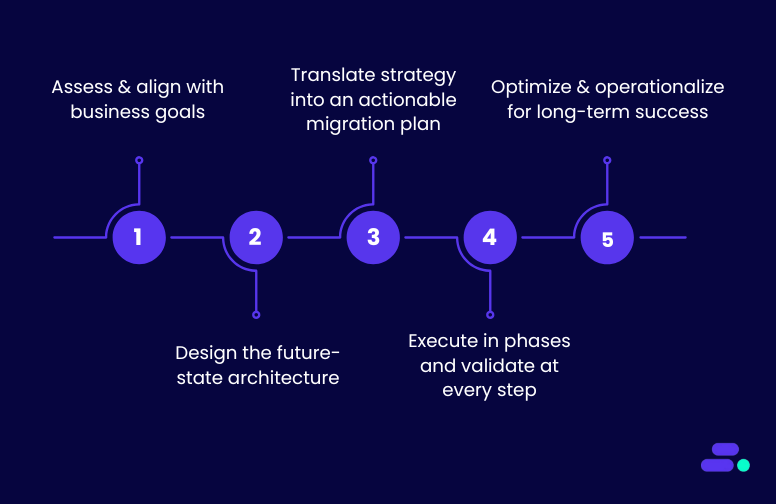
Cloud migration is all about re-architecting for long-term performance, security, and scalability. For SMBs, jumping into AWS without a structured roadmap often leads to fragmented environments, cost overruns, and missed opportunities for automation or modernization.
A sustainable migration requires a clear understanding of existing workloads, a well-defined future-state architecture, and guardrails for governance, security, and cost control. Without this, businesses risk replicating on-prem inefficiencies in the cloud or adopting services that don’t align with their actual needs.
When migrating, businesses need a roadmap that reflects a repeatable, scalable migration strategy designed specifically for SMBs.
Step 1: Assess and align with business goals
A successful cloud migration starts with understanding what businesses already have and what they’re trying to achieve. This step is about aligning IT modernization with core business outcomes like faster product delivery, lower operational costs, or enabling new data-driven services.
Businesses should start with a comprehensive assessment of their current environment. Tools like AWS Migration Evaluator or AWS Application Discovery Service help automatically scan and map existing infrastructure, capturing details like CPU usage, memory requirements, and license dependencies. For SMBs running legacy systems (e.g., on-prem ERP, SQL Server, or file storage), this helps identify what’s worth migrating as-is, what needs replatforming, and what can be retired.
But technology alone isn’t enough. Business alignment matters. Define concrete, measurable goals. For example:
- Reduce CapEx-heavy infrastructure spend by 30% over 12 months.
- Enable secure remote access to key systems for distributed teams using AWS WorkSpaces.
- Prepare 12 months of customer data for analysis in Amazon Redshift or Amazon Bedrock.
Bring in stakeholders from finance, compliance, operations, and engineering early. They’ll help validate priorities like cost controls, regulatory compliance (e.g., HIPAA or PCI), and future plans for AI, data analytics, or customer platforms. These inputs ensure the AWS landing zone is aligned with the business roadmap from the outset.
Pro tip: Cloudtech guides clients through this phase with structured assessments that map workloads, flag risks, and translate cloud capabilities into real-world outcomes. This clarity up front prevents missteps down the line and ensures the migration moves the business forward.
Step 2: Design the future-state architecture
Once the business objectives are defined, SMBs need to architect a cloud environment that supports those goals not just today, but years down the line. A future-state AWS architecture should prioritize scalability, security, and compliance from the ground up.
This phase isn’t about lifting and shifting everything at once but building the right foundation to grow on.
Key areas to address in this phase include:
- Availability and resilience: Choose AWS Regions and Availability Zones strategically to ensure high availability and disaster recovery. Multi-AZ deployments are used for fault-tolerant applications, while latency-sensitive workloads are placed closer to end users.
- Governance and access control: Implement AWS Control Tower to set up a secure, multi-account environment. Use AWS Organizations for centralized billing and policy management, and configure AWS IAM for fine-grained role-based access control.
- Security and compliance readiness: Integrate services like AWS KMS (for data encryption), AWS CloudTrail (for auditing), and AWS Config (for compliance tracking). These help SMBs meet standards like HIPAA, SOC 2, or PCI-DSS without relying on patchwork solutions later.
- Compute and storage planning: Use Amazon EC2 or container services like AWS ECS/EKS based on workload type. Opt for Amazon S3 Intelligent-Tiering or EFS depending on access frequency and data type to keep storage costs optimized.
- Future-readiness: Architect for emerging needs like AI integration (Amazon Bedrock), serverless processing (AWS Lambda), and remote collaboration (Amazon WorkSpaces, AppStream 2.0). Cloudtech ensures the architecture supports future acquisitions, product expansions, or shifts in operating models.
A strong architectural plan ensures that SMBs modernize with intention. With expert guidance from a partner like Cloudtech, each decision is grounded in AWS best practices and aligned with long-term business strategy.
Step 3: Translate strategy into an actionable migration plan
A cloud migration should unfold in carefully planned phases. For SMBs, this step is about converting their architecture blueprint into a clear, executable strategy with ownership, timelines, and risk controls built in. Even well-designed migrations stall or backfire due to overlooked interdependencies or unprepared teams. This can be avoided with a structured process:
1. Workload prioritization
Start by identifying low-risk, high-value workloads to migrate first, like backup systems, development environments, or non-customer-facing apps.
Use tools like:
- AWS Migration Hub: For centralized tracking
- AWS Application Migration Service (MGN): For lift-and-shift scenarios
- AWS DMS: To migrate live databases with minimal downtime
2. Role assignment and ownership
Define clear responsibilities across technical and non-technical teams:
- Who provisions infrastructure (e.g., via AWS CloudFormation)
- Who signs off on application validation
- Who manages rollback and recovery if needed
3. Built-in fail-safes
Mitigate risks by baking resilience into the plan:
- Set up AWS Backup to capture the state before each phase
- Use AWS Elastic Disaster Recovery (DRS) for failover testing
- Document rollback conditions and escalation paths
4. Prepare the people
Migration isn’t just tech. It’s enablement. Upskill internal teams with:
- Access control policies via AWS IAM
- Logging and alerting via Amazon CloudWatch and AWS Security Hub
- Role-based cloud operations training (via AWS Skill Builder or partners)
5. Keep everyone in the loop
Frequent, transparent communication keeps momentum:
- Share timelines and scope changes
- Flag upcoming user-facing changes
- Provide live support during go-live windows
With the right planning framework and tooling, SMBs can avoid common migration pitfalls and achieve faster adoption.
Step 4: Execute in phases and validate at every step
Cloud migration is an iterative process. Moving everything at once might seem faster, but for SMBs, it’s a high-risk gamble. The smarter path is to migrate in stages, using each phase to test assumptions, improve processes, and build team confidence.
Start with what’s safe and valuable: Begin with internal tools, dev/test environments, or archival data. These workloads have fewer dependencies and won’t disrupt business if issues arise.
Use AWS Application Migration Service (MGN) for rehosting VMs and AWS Snowball for large data transfers when bandwidth is limited.
Validate after each phase:
- Run pilot deployments in a staging VPC that mirrors production
- Use Amazon CloudWatch to monitor baseline performance metrics
- Test for compatibility, latency, and cost variance before scaling further
Incorporate feedback into the next wave: Use lessons from each round to fine-tune IAM permissions, storage classes (e.g., Amazon S3 Standard vs. AWS Intelligent-Tiering), and tagging strategies
If workloads require refactoring for better performance, shift to services like Amazon ECS, Amazon RDS, or AWS Lambda in later phases
Control risk while keeping momentum:
- Back up workloads using AWS Backup before cutover
- Monitor every transition with CloudTrail and AWS Config to ensure nothing breaks compliance
- Communicate clearly with stakeholders between each phase to avoid user confusion or downtime
A phased, validated approach ensures each step forward strengthens the foundation for future innovations.
Step 5: Optimize and operationalize for long-term success
Migration is only the starting point for driving real business value from the cloud. Once workloads are stable on AWS, SMBs must shift focus to optimization and governance to ensure long-term sustainability.
Start by tightening performance, cost, and security controls using AWS-native tools:
Optimize day-to-day operations with:
- Amazon CloudWatch for real-time monitoring, custom dashboards, and proactive alerts
- AWS Trusted Advisor to flag cost inefficiencies, security risks, and underused resources
- AWS Cost Explorer to break down usage trends, set thresholds, and track spend across teams
Governance should be baked into every layer of operations.
Implement cloud governance through:
- Resource tagging strategies for ownership, cost allocation, and lifecycle management
- AWS Organizations with Service Control Policies (SCPs) to enforce consistent policies across environments
- AWS Backup to centralize data protection and align with recovery objectives
As the cloud environment matures, regularly reassess architecture and usage patterns. For example, migrating Amazon EC2-based applications to Amazon ECS Fargate or AWS Lambda could reduce operational overhead. Similarly, consider converting steady workloads to Savings Plans or Reserved Instances to optimize spend.
AWS partners like Cloudtech can help SMBs successfully maintain and evolve their AWS environment post-migration. It brings technical rigor and business context to every phase, whether that’s dependency mapping, phased cutovers, or designing cloud-native architectures.
How does Cloudtech ensure that on-prem to cloud migration is successful?
Cloudtech, an AWS Advanced Tier Services Partner, specializes in helping SMBs modernize their infrastructure and operations by transitioning to scalable, secure, and future-ready AWS environments.
Backed by AWS-certified architects and a human-centric methodology, Cloudtech’s migration approach delivers impact at every phase:
1. Cloud assessments grounded in business objectives
Every engagement begins with a structured Cloud or Infrastructure Assessment to evaluate legacy systems, interdependencies, compliance requirements, and cost inefficiencies. This allows Cloudtech to map a clear AWS adoption strategy that reflects both technical baseline and growth goals.
Whether migrating EHR systems for healthcare compliance or restructuring data flows for fintech scale, Cloudtech ensures migrations are aligned with real business outcomes.
2. Architecture design that balances resilience and agility
Once priorities are identified, Cloudtech architects the target AWS environment using AWS-native building blocks:
- Multi-AZ redundancy for uptime
- Scalable compute (Amazon EC2, AWS Lambda, AWS Fargate)
- Intelligent storage (Amazon S3, Amazon EFS, Amazon Glacier)
- Modern identity and access controls (AWS IAM, AWS Organizations)
Security, compliance, and scalability are foundational for on-prem to cloud migrations. Cloudtech designs environments that are secure and ready for what’s next, whether that’s AI, analytics, or application modernization.
3. Structured migration delivery with minimal disruption
Cloudtech follows a phased implementation model—Engage, Discover, Align, Deliver, and Enable—to ensure migrations are smooth and non-disruptive.
Each phase includes:
- Workload prioritization and sequencing (e.g., dev/test before production)
- Tool-driven migration execution (AWS MGN, DMS, etc.)
- Security-first posture from day one
Cloudtech also supports hybrid-to-cloud and cloud-to-cloud transitions, ensuring flexibility and future-proofing.
4. Preparing the team for cloud-first operations
Migration is organizational as much as it is technical. Cloudtech equips internal teams through targeted enablement:
- Training on IAM, backup strategies, and AWS-native operations
- Knowledge transfer workshops post-deployment
- Ongoing governance setup with tagging standards, audit trails, and compliance controls
This hands-on support ensures SMBs adopt AWS successfully and thrive in it.
5. Long-term optimization and innovation
After migration, Cloudtech shifts focus to long-term success:
- Cost Optimization using tools like AWS Cost Explorer and AWS Trusted Advisor
- Performance tuning and architecture refinement
- AI-readiness and data modernization, enabling future analytics and GenAI use cases
Cloudtech also offers ongoing managed services to monitor workloads, automate governance, and continuously align cloud operations with business strategy.
What sets Cloudtech apart is the boutique approach that tailors cloud strategies to the way SMBs work. With services spanning data modernization, application modernization, infrastructure resiliency, and generative AI, Cloudtech delivers migrations that are secure, scalable, and built for growth.
Wrapping up
Modernization doesn’t stop at “the move.” SMBs will need help optimizing workloads, containing costs, securing environments, and upskilling teams to operate in a cloud-native world. Without a clear post-migration strategy, it’s easy to lose traction or face unexpected setbacks.
With Cloudtech, SMBs stay cloud-smart for the long haul. From fine-tuning performance and eliminating waste to implementing security baselines and enabling DevOps workflows, Cloudtech helps SMBs build maturity after migration. Backed by AWS-native automation and long-term governance, SMBs gain the confidence to grow, innovate, and scale without reverting to old IT habits.
Whether it is bringing agility, reducing overhead, or enabling new innovation, Cloudtech ensures the move to AWS delivers sustainable, measurable results to businesses. Connect with Cloudtech to start the conversation.
FAQs
1. How can SMBs identify which on-prem workloads to move first?
Cloudtech starts with a workload assessment to prioritize systems based on technical debt, operational risk, and business value. Low-risk, high-maintenance apps, like file servers, dev/test environments, or aging databases, are often ideal for Phase 1 migration.
2. How does Cloudtech minimize downtime during migration?
By using tools like AWS Application Migration Service (MGN) and Database Migration Service (DMS), Cloudtech supports live replication, near-zero downtime cutovers, and phased transitions. This ensures critical operations continue running while workloads move.
3. What if the current team lacks cloud experience?
Cloudtech doesn’t just migrate infrastructure, it upskills teams. From AWS-native training and documentation to hands-on enablement, Cloudtech ensures the staff is equipped to manage, secure, and scale the new environment from day one.
4. Can SMBs migrate to AWS in phases without creating silos?
Yes. Cloudtech uses landing zones and modular architecture to enable phased migration while maintaining security, connectivity, and consistency across hybrid environments. This makes it possible to modernize gradually, without fragmenting operations.
5. How to maintain performance and cost control post-migration?
Cloudtech implements AWS Cost Explorer, CloudWatch, and Trusted Advisor to monitor usage, rightsize instances, and enforce tagging strategies. Ongoing reviews help keep the environment efficient, aligned with growth, and ready for continuous optimization.

How can SMBs perform HIPAA compliant disaster recovery?
Recent data shows that while 89% of organizations provide HIPAA Privacy Rule training and 81% cover the Security Rule, only 50% actually test employees on this training at least annually. For SMBs, this gap underscores the risk: disaster recovery plans must not only ensure system uptime but also safeguard protected health information (PHI) in line with HIPAA standards.
Aligning disaster recovery strategies with HIPAA’s privacy, security, and breach notification rules empower SMBs to reduce the likelihood of compliance failures, avoid costly penalties, and maintain patient trust even in the face of outages or cyber incidents.
This article outlines how SMBs can design disaster recovery strategies that meet HIPAA requirements without adding unnecessary complexity. It covers practical steps, AWS-native tools, and expert approaches to protect PHI while ensuring business continuity.
Key takeaways:
- HIPAA-aligned DR is non-negotiable: Ensuring PHI availability, integrity, and recoverability is essential for both compliance and patient trust.
- Define clear recovery objectives: RTO and RPO must be set for critical systems like EHRs, billing, and lab apps to meet HIPAA standards.
- Automate and secure backups: AWS Backup, Amazon RDS snapshots, Amazon S3 versioning, and S3 Object Lock help prevent data loss, tampering, and accidental deletion.
- Test, monitor, and audit continuously: Regular disaster recovery drills, AWS CloudTrail logs, AWS Config, AWS Security Hub, and Amazon GuardDuty ensure operational readiness and regulatory compliance.
- Partnering with Cloudtech accelerates compliance: Cloudtech combines deep AWS expertise with healthcare SMB experience to implement robust, HIPAA-compliant disaster recovery strategies efficiently and reliably.
What happens when disaster recovery isn't aligned with HIPAA compliance?
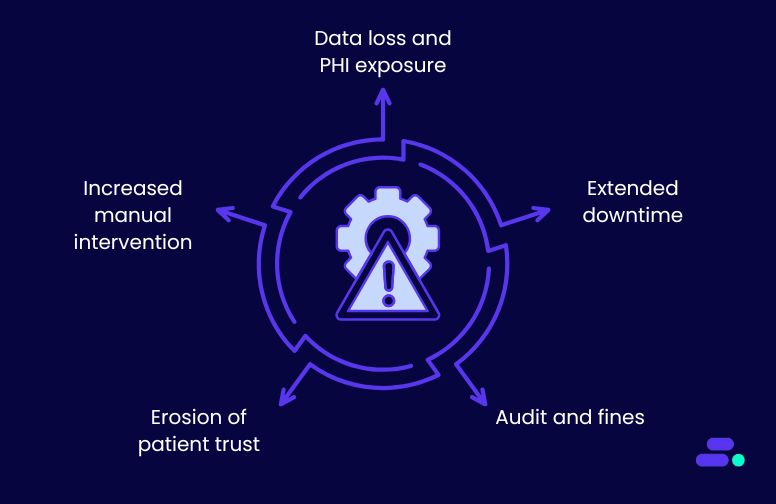
A recovery strategy that isn’t HIPAA-compliant exposes the organization to regulatory penalties, potential breaches of sensitive data, and loss of patient trust. In other words, it’s a compliance gap with real legal and financial consequences.
Key risks of non-aligned disaster recovery:
- Data loss and PHI exposure: Without HIPAA-compliant backups, PHI may be permanently lost or exposed in an outage, violating the privacy and security rules.
- Extended downtime: Non-compliant DR plans often lack recovery time objectives (RTOs) and recovery point objectives (RPOs) that meet HIPAA’s standard for timely access to health data.
- Audit and fines: HIPAA requires covered entities and business associates to demonstrate compliance. Gaps in disaster recovery can result in failed audits, leading to fines that range from thousands to millions of dollars.
- Erosion of patient trust: Beyond penalties, patients expect their health data to remain secure and accessible. A breach of this trust can be more damaging than financial loss.
- Increased manual intervention: Without automation and monitoring (as encouraged by AWS best practices), IT teams face delays in restoring services, creating compliance and operational risks.
In short, a disaster recovery plan that isn’t HIPAA-aligned exposes healthcare SMBs to data vulnerabilities, regulatory consequences, and reputational damage. Aligning DR with HIPAA ensures not only legal compliance but also resilience, continuity of care, and patient confidence.

Step-by-step process for performing HIPAA compliant disaster recovery
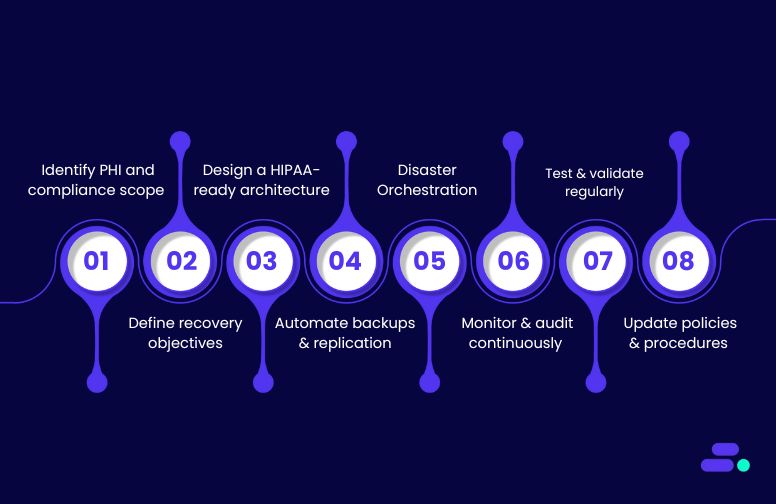
AWS is well-suited for HIPAA-aligned disaster recovery (DR) because it provides secure, compliant infrastructure with built-in resilience. Features like multi-AZ replication, automated backups, and encrypted storage ensure protected health information (PHI) is both highly available and safeguarded.
On top of this, AWS offers tools to make DR both fast and auditable. AWS Elastic Disaster Recovery (DRS) enables quick failover across Regions, while AWS CloudTrail and AWS Config deliver the logs needed for HIPAA reporting. These tools enable SMBs to design DR strategies that not only minimize downtime but also maintain HIPAA’s required safeguards for confidentiality, integrity, and availability of PHI.
SMBs can follow a step-by-step process to perform HIPAA compliant disaster recovery:
1. Identify PHI and compliance scope
Before building disaster recovery, SMBs need a clear understanding of where protected health information (PHI) resides and how it flows across their systems. This ensures every workload that stores or processes PHI is covered under HIPAA safeguards, minimizing compliance gaps and protecting patient trust.
How to do this with AWS:
- Use AWS Macie to automatically scan and classify PHI within S3 buckets.
- Leverage AWS Config to track PHI-related workloads and validate that they meet HIPAA-required configurations.
- Centralize resource visibility with AWS Organizations to map which accounts and workloads fall under HIPAA compliance obligations.
Use case: A regional healthcare SMB uploads patient records and lab results into Amazon S3. They use AWS Macie to detect PHI such as social security numbers and health IDs, then apply AWS Config rules to verify encryption at rest and in transit.
Through AWS Organizations, they centralize compliance policies across multiple accounts, ensuring PHI workloads are scoped properly before defining their disaster recovery plan.
2. Define recovery objectives
HIPAA requires healthcare organizations to ensure PHI remains available and intact during a disaster. To achieve this, SMBs must define recovery time objectives (RTO), like how quickly systems must be restored, and recovery point objectives (RPO), like how much data can be lost without violating compliance.
By aligning these objectives with business-critical systems such as electronic health records (EHRs), billing platforms, and lab applications, SMBs can prioritize recovery where it matters most.
How to do this with AWS:
- Use AWS Elastic Disaster Recovery (AWS DRS) to set RPO/RTO targets and replicate workloads with minimal data loss.
- Leverage Amazon CloudWatch metrics to monitor workload performance against defined RTO thresholds.
- Run compliance-driven simulations with AWS Fault Injection Simulator (FIS) to validate if recovery objectives meet HIPAA availability standards.
Use case: A mid-sized healthcare SMB running an EHR system on Amazon RDS defines an RPO of 15 minutes and an RTO of 1 hour. They use AWS DRS to continuously replicate the EHR database across Availability Zones, configure CloudWatch alarms to track recovery SLAs, and regularly test scenarios with AWS FIS.
This ensures that, even during outages, PHI remains both available and compliant with HIPAA’s integrity and availability requirements.
3. Design a HIPAA-ready architecture
To meet HIPAA’s requirements for confidentiality, integrity, and availability of PHI, SMBs need to design their disaster recovery architecture with both resilience and security in mind.
This means workloads must withstand outages across Availability Zones (AZs) or even Regions, while ensuring PHI is encrypted, access-controlled, and isolated from unauthorized traffic. A HIPAA-ready architecture balances technical robustness with strict compliance safeguards.
How to do this with AWS:
- Enable multi-AZ and multi-Region deployments with services like Amazon RDS, Amazon S3 Cross-Region Replication, and AWS Elastic Disaster Recovery for fault tolerance.
- Encrypt PHI at rest and in transit using AWS Key Management Service (KMS) and enforcing TLS across all communication channels.
- Apply least-privilege IAM policies and network segmentation with AWS Identity and Access Management (IAM), Amazon VPC, and security groups to restrict access to PHI workloads.
Use case: A regional healthcare SMB runs its billing and patient management system on Amazon RDS and Amazon EC2. To ensure HIPAA alignment, they configure multi-AZ failover for their RDS database, use S3 cross-region replication to back up billing records, and encrypt all PHI with KMS-managed keys.
Their security team enforces IAM role-based access and VPC segmentation so only authorized clinicians and billing staff can reach the sensitive workloads. This design ensures resilience against outages while maintaining HIPAA-grade data security.
4. Automate backups and replication
A HIPAA-aligned DR plan requires that PHI is continuously protected without relying on manual processes. Automated backups and replication not only reduce human error but also ensure that data can be quickly restored in case of outages, corruption, or accidental deletion. By combining immutability and versioning, SMBs create an auditable, compliant trail of PHI data protection.
How to do this with AWS:
- Enable AWS Backup to centralize and automate backups across services like Amazon RDS, Amazon EFS, and DynamoDB.
- Use Amazon RDS automated snapshots and point-in-time recovery to protect EHR or billing databases.
- Configure Amazon S3 versioning and Object Lock to prevent tampering or accidental deletions of PHI backups.
Use case: A growing healthcare SMB runs its electronic lab results system on Amazon RDS and stores patient reports in Amazon S3. They configure AWS Backup to automatically capture daily RDS snapshots and enforce Object Lock on S3 buckets holding PHI.
If a staff member accidentally deletes or modifies a report, the SMB can restore it from an immutable backup, ensuring compliance with HIPAA’s data integrity and availability requirements.

5. Implement disaster recovery orchestration
A HIPAA-compliant DR plan cannot stop at backups, it must also ensure rapid workload recovery in the event of an outage. Orchestration brings automation and repeatability, reducing recovery times and minimizing human error during stressful failover scenarios. By continuously testing and validating DR runbooks, SMBs align with HIPAA’s requirement to maintain PHI availability.
How to do this with AWS:
- Use AWS Elastic Disaster Recovery (DRS) to replicate workloads from primary to standby environments with minimal downtime.
- Configure automated failover workflows using AWS CloudEndure or Step Functions to orchestrate multi-tier application recovery.
- Regularly test recovery plans through controlled failover drills to validate compliance with HIPAA’s availability standards.
Use case: A healthcare SMB hosting its billing and claims system on Amazon EC2 replicates workloads to a secondary Region using AWS DRS. They set up automated failover playbooks with AWS Step Functions to bring critical services online within their defined RTO. Twice a year, the IT team runs simulated failover tests to confirm systems can recover quickly while meeting HIPAA’s operational availability rules.
6. Monitor and audit continuously
HIPAA compliance isn’t a one-time setup. It requires ongoing monitoring and evidence that security and availability controls are enforced at all times. Continuous visibility helps SMBs detect unauthorized access, configuration drift, or security threats before they impact PHI. Auditability also ensures organizations can demonstrate compliance during regulatory reviews.
How to do this with AWS:
- Enable AWS CloudTrail and AWS Config to track all API activity and resource changes across accounts.
- Use AWS Security Hub and GuardDuty to continuously monitor for misconfigurations, anomalies, or suspicious activities tied to PHI workloads.
- Set up log retention policies in Amazon S3 and Glacier to meet HIPAA’s requirement for forensic investigations and long-term compliance audits.
Use case: A healthcare SMB runs its patient scheduling system on Amazon RDS and EC2. With AWS CloudTrail enabled, every API call is logged, while AWS Config flags non-compliant security group changes. GuardDuty alerts the IT team about unusual login attempts, and all logs are securely stored in Amazon S3 with Object Lock, ensuring immutability for HIPAA audit readiness.
7. Test and validate regularly
A disaster recovery plan is only effective if it works when needed. HIPAA explicitly requires organizations to test and train their workforce on contingency procedures. Regular DR drills not only validate the technical failover process but also prepare teams to respond quickly during real incidents. Documenting results is essential for proving compliance in HIPAA audits.
How to do this with AWS:
- Use AWS Elastic Disaster Recovery (DRS) or CloudEndure to run non-disruptive failover tests without impacting production workloads.
- Leverage AWS Fault Injection Simulator to perform chaos engineering experiments and validate resilience against failures.
- Automate reporting with AWS Systems Manager to capture test outcomes and retain evidence for compliance audits.
Use case: A mid-sized dental practice runs its billing application on Amazon RDS and EC2. Twice a year, the IT team uses AWS DRS to spin up a recovery environment in another Region and measure failover time against the defined RTO. They document the results in AWS Systems Manager runbooks, creating a compliance trail that auditors can review to confirm HIPAA readiness.
8. Update policies and procedures
Disaster recovery is also about people and processes. HIPAA requires that contingency plans be backed by documented policies and workforce training. Updating policies ensures that technical safeguards (like backups, failover, and monitoring) align with organizational procedures for incident response.
Training staff makes sure employees know their roles during an outage, helping maintain the availability, confidentiality, and integrity of PHI.
How to do this with AWS:
- Integrate AWS backup and DR workflows into internal SOPs so staff know when and how to trigger failover or recovery.
- Use AWS Identity and Access Management (IAM) to enforce role-based access policies that map directly to DR responsibilities.
- Leverage AWS Artifact to access HIPAA-related compliance reports and share them with staff during training and audits.
Use case: A regional urgent care provider documents new policies for how its staff should respond if its Electronic Health Record (EHR) system becomes unavailable. The IT team integrates AWS Backup and AWS DRS workflows into the policy playbook and uses IAM roles to define which staff members can initiate recovery.
During quarterly training, employees review these procedures alongside HIPAA guidelines, ensuring both compliance and operational readiness.

Pro tip: Working with an AWS Partner like Cloudtech is highly advisable for HIPAA-relevant disaster recovery because certified partners bring deep expertise in AWS security, compliance, and healthcare workloads.
They understand how to map HIPAA safeguards to AWS services, design resilient multi-Region architectures, and implement proper encryption, monitoring, and audit controls.
See how other SMBs have modernized, scaled, and thrived with Cloudtech’s support →
How does Cloudtech help healthcare SMBs set up HIPAA-compliant disaster recovery?
What sets Cloudtech apart is its deep AWS expertise combined with a human-centric approach tailored for SMBs. Cloudtech focuses exclusively on helping smaller organizations modernize with AWS while staying compliant with complex frameworks like HIPAA.
For healthcare SMBs, this means DR strategies that not only meet technical requirements but also align with regulatory safeguards for PHI protection and availability.
Relevant Cloudtech services for HIPAA-compliant DR:
- Infrastructure & resiliency services: Multi-AZ and multi-Region design, backup automation, and failover orchestration using AWS Elastic Disaster Recovery.
- Data modernization: Secure storage, encryption, and compliant data lake/warehouse strategies for PHI.
- Security & governance: HIPAA-aligned identity management, monitoring with CloudTrail, GuardDuty, and AWS Config, plus audit-ready logging.
- Managed cloud services: Ongoing monitoring, DR drills, and policy alignment to keep systems and staff compliant over time.
By combining these services, Cloudtech ensures healthcare SMBs achieve HIPAA-compliant DR that is resilient, cost-efficient, and continuously audit-ready.

Wrapping up
HIPAA-compliant disaster recovery is a critical safeguard for protecting patient data, maintaining trust, and ensuring uninterrupted operations. For healthcare SMBs, even minor misconfigurations or gaps can have serious regulatory, financial, and reputational consequences.
Partnering with an AWS expert like Cloudtech ensures DR strategies are designed and implemented with precision. With their support, healthcare teams can focus on patient care and growth, confident that critical workloads remain protected and compliant.
Connect with Cloudtech today to build a HIPAA-compliant disaster recovery strategy that safeguards PHI and keeps your operations running smoothly.
FAQs
1. Why is disaster recovery critical for HIPAA compliance in SMBs?
Disaster recovery ensures that Protected Health Information (PHI) remains available, intact, and recoverable during outages, cyberattacks, or human errors. HIPAA mandates that healthcare organizations implement technical safeguards to maintain data availability and integrity, making DR an essential compliance component.
2. Can small healthcare SMBs implement HIPAA-compliant DR without AWS expertise?
While technically possible, doing so is highly challenging. Configuring multi-AZ/Region replication, secure backups, failover orchestration, and audit logging requires deep AWS knowledge. Without it, gaps in compliance or misconfigured systems could expose PHI to risks.
3. How often should SMBs test their HIPAA-compliant DR plans?
HIPAA recommends testing and workforce training at least annually. Frequent testing—quarterly or semi-annual—helps validate that backups, failovers, and alerting mechanisms work correctly, while also familiarizing staff with DR processes to reduce human errors during incidents.
4. What AWS services are most useful for HIPAA-aligned disaster recovery?
AWS offers several critical tools for DR, including AWS Backup, RDS snapshots, Amazon S3 with Object Lock, AWS Elastic Disaster Recovery (DRS), CloudEndure, CloudTrail, AWS Config, Security Hub, and GuardDuty. These services help SMBs automate backups, orchestrate failovers, and maintain audit-ready logs.
5. How does Cloudtech add value beyond standard AWS DR capabilities?
Cloudtech tailors disaster recovery strategies for healthcare SMBs by aligning AWS services with HIPAA requirements. They implement automated backups, replication, and failover, validate recovery objectives, enforce least-privilege access, and provide continuous monitoring and staff training, ensuring DR is compliant, resilient, and fully operational.
Get started on your cloud modernization journey today!
Let Cloudtech build a modern AWS infrastructure that’s right for your business.