Resources
Find the latest news & updates on AWS

Cloudtech Has Earned AWS Advanced Tier Partner Status
We’re honored to announce that Cloudtech has officially secured AWS Advanced Tier Partner status within the Amazon Web Services (AWS) Partner Network!
We’re honored to announce that Cloudtech has officially secured AWS Advanced Tier Partner status within the Amazon Web Services (AWS) Partner Network! This significant achievement highlights our expertise in AWS cloud modernization and reinforces our commitment to delivering transformative solutions for our clients.
As an AWS Advanced Tier Partner, Cloudtech has been recognized for its exceptional capabilities in cloud data, application, and infrastructure modernization. This milestone underscores our dedication to excellence and our proven ability to leverage AWS technologies for outstanding results.
A Message from Our CEO
“Achieving AWS Advanced Tier Partner status is a pivotal moment for Cloudtech,” said Kamran Adil, CEO. “This recognition not only validates our expertise in delivering advanced cloud solutions but also reflects the hard work and dedication of our team in harnessing the power of AWS services.”
What This Means for Us
To reach Advanced Tier Partner status, Cloudtech demonstrated an in-depth understanding of AWS services and a solid track record of successful, high-quality implementations. This achievement comes with enhanced benefits, including advanced technical support, exclusive training resources, and closer collaboration with AWS sales and marketing teams.
Elevating Our Cloud Offerings
With our new status, Cloudtech is poised to enhance our cloud solutions even further. We provide a range of services, including:
- Data Modernization
- Application Modernization
- Infrastructure and Resiliency Solutions
By utilizing AWS’s cutting-edge tools and services, we equip startups and enterprises with scalable, secure solutions that accelerate digital transformation and optimize operational efficiency.
We're excited to share this news right after the launch of our new website and fresh branding! These updates reflect our commitment to innovation and excellence in the ever-changing cloud landscape. Our new look truly captures our mission: to empower businesses with personalized cloud modernization solutions that drive success. We can't wait for you to explore it all!
Stay tuned as we continue to innovate and drive impactful outcomes for our diverse client portfolio.


Supercharge Your Data Architecture with the Latest AWS Step Functions Integrations
In the rapidly evolving cloud computing landscape, AWS Step Functions has emerged as a cornerstone for developers looking to orchestrate complex, distributed applications seamlessly in serverless implementations. The recent expansion of AWS SDK integrations marks a significant milestone, introducing support for 33 additional AWS services, including cutting-edge tools like Amazon Q, AWS B2B Data Interchange, AWS Bedrock, Amazon Neptune, and Amazon CloudFront KeyValueStore, etc. This enhancement not only broadens the horizon for application development but also opens new avenues for serverless data processing.
Serverless computing has revolutionized the way we build and scale applications, offering a way to execute code in response to events without the need to manage the underlying infrastructure. With the latest updates to AWS Step Functions, developers now have at their disposal a more extensive toolkit for creating serverless workflows that are not only scalable but also cost-efficient and less prone to errors.
In this blog, we will delve into the benefits and practical applications of these new integrations, with a special focus on serverless data processing. Whether you're managing massive datasets, streamlining business processes, or building real-time analytics solutions, the enhanced capabilities of AWS Step Functions can help you achieve more with less code. By leveraging these integrations, you can create workflows that directly invoke over 11,000+ API actions from more than 220 AWS services, simplifying the architecture and accelerating development cycles.
Practical Applications in Data Processing:
This AWS SDK integration with 33 new services not only broadens the scope of potential applications within the AWS ecosystem but also streamlines the execution of a wide range of data processing tasks. These integrations empower businesses with automated AI-driven data processing, streamlined EDI document handling, and enhanced content delivery performance.
Amazon Q Integration: Amazon Q is a generative AI-powered enterprise chat assistant designed to enhance employee productivity in various business operations. The integration of Amazon Q with AWS Step Functions enhances workflow automation by leveraging AI-driven data processing. This integration allows for efficient knowledge discovery, summarization, and content generation across various business operations. It enables quick and intuitive data analysis and visualization, particularly beneficial for business intelligence. In customer service, it provides real-time, data-driven solutions, improving efficiency and accuracy. It also offers insightful responses to complex queries, facilitating data-informed decision-making.
AWS B2B Data Interchange: Integrating AWS B2B Data Interchange with AWS Step Functions streamlines and automates electronic data interchange (EDI) document processing in business workflows. This integration allows for efficient handling of transactions including order fulfillment and claims processing. The low-code approach simplifies EDI onboarding, enabling businesses to utilize processed data in applications and analytics quickly. This results in improved management of trading partner relationships and real-time integration with data lakes, enhancing data accessibility for analysis. The detailed logging feature aids in error detection and provides valuable transaction insights, essential for managing business disruptions and risks.
Amazon CloudFront KeyValueStore: This integration enhances content delivery networks by providing fast, reliable access to data across global networks. It's particularly beneficial for businesses that require quick access to large volumes of data distributed worldwide, ensuring that the data is always available where and when it's needed.
Neptune Data: This integration allows the Processing of graph data in a serverless environment, ideal for applications that require complex relationships and data patterns like social networks, recommendation engines, and knowledge graphs. For instance, Step Functions can orchestrate a series of tasks that ingest data into Neptune, execute graph queries, analyze the results, and then trigger other services based on those results, such as updating a dashboard or triggering alerts.
Amazon Timestream Query & Write: The integration is useful in serverless architectures for analyzing high-volume time-series data in real-time, such as sensor data, application logs, and financial transactions. Step Functions can manage the flow of data from ingestion (using Timestream Write) to analysis (using Timestream Query), including data transformation, anomaly detection, and triggering actions based on analytical insights.
Amazon Bedrock & Bedrock Runtime: AWS Step Functions can orchestrate complex data streaming and processing pipelines that ingest data in real-time, perform transformations, and route data to various analytics tools or storage systems. Step Functions can manage the flow of data across different Bedrock tasks, handling error retries, and parallel processing efficiently
AWS Elemental MediaPackage V2: Step Functions can orchestrate video processing workflows that package, encrypt, and deliver video content, including invoking MediaPackage V2 actions to prepare video streams, monitoring encoding jobs, and updating databases or notification systems upon completion.
AWS Data Exports: With Step Functions, you can sequence tasks such as triggering data export actions, monitoring their progress, and executing subsequent data processing or notification steps upon completion. It can automate data export workflows that aggregate data from various sources, transform it, and then export it to a data lake or warehouse.
Benefits of the New Integrations
The recent integrations within AWS Step Functions bring forth a multitude of benefits that collectively enhance the efficiency, scalability, and reliability of data processing and workflow management systems. These advancements simplify the architectural complexity, reduce the necessity for custom code, and ensure cost efficiency, thereby addressing some of the most pressing challenges in modern data processing practices. Here's a summary of the key benefits:
Simplified Architecture: The new service integrations streamline the architecture of data processing systems, reducing the need for complex orchestration and manual intervention.
Reduced Code Requirement: With a broader range of integrations, less custom code is needed, facilitating faster deployment, lower development costs, and reduced error rates.
Cost Efficiency: By optimizing workflows and reducing the need for additional resources or complex infrastructure, these integrations can lead to significant cost savings.
Enhanced Scalability: The integrations allow systems to easily scale, accommodating increasing data loads and complex processing requirements without the need for extensive reconfiguration.
Improved Data Management: These integrations offer better control and management of data flows, enabling more efficient data processing, storage, and retrieval.
Increased Flexibility: With a wide range of services now integrated with AWS Step Functions, businesses have more options to tailor their workflows to specific needs, increasing overall system flexibility.
Faster Time-to-Insight: The streamlined processes enabled by these integrations allow for quicker data processing, leading to faster time-to-insight and decision-making.
Enhanced Security and Compliance: Integrating with AWS services ensures adherence to high security and compliance standards, which is essential for sensitive data processing and regulatory requirements.
Easier Integration with Existing Systems: These new integrations make it simpler to connect AWS Step Functions with existing systems and services, allowing for smoother digital transformation initiatives.
Global Reach: Services like Amazon CloudFront KeyValueStore enhance global data accessibility, ensuring high performance across geographical locations.
As businesses continue to navigate the challenges of digital transformation, these new AWS Step Functions integrations offer powerful solutions to streamline operations, enhance data processing capabilities, and drive innovation. At Cloudtech, we specialize in serverless data processing and event-driven architectures. Contact us today and ask how you can realize the benefits of these new AWS Step Functions integrations in your data architecture.

Revolutionize Your Search Engine with Amazon Personalize and Amazon OpenSearch Service
In today's digital landscape, user experience is paramount, and search engines play a pivotal role in shaping it. Imagine a world where your search engine not only understands your preferences and needs but anticipates them, delivering results that resonate with you on a personal level. This transformative user experience is made possible by the fusion of Amazon Personalize and Amazon OpenSearch Service.
Understanding Amazon Personalize
Amazon Personalize is a fully-managed machine learning service that empowers businesses to develop and deploy personalized recommendation systems, search engines, and content recommendation engines. It is part of the AWS suite of services and can be seamlessly integrated into web applications, mobile apps, and other digital platforms.
Key components and features of Amazon Personalize include:
Datasets: Users can import their own data, including user interaction data, item data, and demographic data, to train the machine learning models.
Recipes: Recipes are predefined machine learning algorithms and models that are designed for specific use cases, such as personalized product recommendations, personalized search results, or content recommendations.
Customization: Users have the flexibility to fine-tune and customize their machine learning models, allowing them to align the recommendations with their specific business goals and user preferences.
Real-Time Recommendations: Amazon Personalize can generate real-time recommendations for users based on their current behavior and interactions.
Batch Recommendations: Businesses can also generate batch recommendations for users, making it suitable for email campaigns, content recommendations, and more.
Benefits of Amazon Personalize
Amazon Personalize offers a range of benefits for businesses looking to enhance user experiences and drive engagement.
Improved User Engagement: By providing users with personalized content and recommendations, Amazon Personalize can significantly increase user engagement rates.
Higher Conversion Rates: Personalized recommendations often lead to higher conversion rates, as users are more likely to make purchases or engage with desired actions when presented with items or content tailored to their preferences.
Enhanced User Satisfaction: Personalization makes users feel understood and valued, leading to improved satisfaction with your platform. Satisfied users are more likely to become loyal customers.
Better Click-Through Rates (CTR): Personalized recommendations and search results can drive higher CTR as users are drawn to content that aligns with their interests, increasing their likelihood of clicking through to explore further.
Increased Revenue: The improved user engagement and conversion rates driven by Amazon Personalize can help cross-sell and upsell products or services effectively.
Efficient Content Discovery: Users can easily discover relevant content, products, or services, reducing the time and effort required to find what they are looking for.
Data-Driven Decision Making: Amazon Personalize provides valuable insights into user behavior and preferences, enabling businesses to make data-driven decisions and optimize their offerings.
Scalability: As an AWS service, Amazon Personalize is highly-scalable and can accommodate businesses of all sizes, from startups to large enterprises.
Understanding Amazon OpenSearch Service
Amazon OpenSearch Service is a fully managed, open-source search and analytics engine developed to provide fast, scalable, and highly-relevant search results and analytics capabilities. It is based on the open-source Elasticsearch and Kibana projects and is designed to efficiently index, store, and search through vast amounts of data.
Benefits of Amazon OpenSearch Service in Search Enhancement
Amazon OpenSearch Service enhances search functionality in several ways:
High-Performance Search: OpenSearch Service enables organizations to rapidly execute complex queries on large datasets to deliver a responsive and seamless search experience.
Scalability: OpenSearch Service is designed to be horizontally scalable, allowing organizations to expand their search clusters as data and query loads increase, ensuring consistent search performance.
Relevance and Ranking: OpenSearch Service allows developers to customize ranking algorithms to ensure that the most relevant search results are presented to users.
Full-Text Search: OpenSearch Service excels in full-text search, making it well-suited for applications that require searching through text-heavy content such as documents, articles, logs, and more. It supports advanced text analysis and search features, including stemming and synonym matching.
Faceted Search: OpenSearch Service supports faceted search, enabling users to filter search results based on various attributes, categories, or metadata.
Analytics and Insights: Beyond search, OpenSearch Service offers analytics capabilities, allowing organizations to gain valuable insights into user behavior, query performance, and data trends to inform data-driven decisions and optimizations.
Security: OpenSearch Service offers access control, encryption, and authentication mechanisms to safeguard sensitive data and ensure secure search operations.
Open-Source Compatibility: While Amazon OpenSearch Service is a managed service, it remains compatible with open-source Elasticsearch, ensuring that organizations can leverage their existing Elasticsearch skills and applications.
Integration Flexibility: OpenSearch Service can seamlessly integrate with various AWS services and third-party tools, enabling organizations to ingest data from multiple sources and build comprehensive search solutions.
Managed Service: Amazon OpenSearch Service is a fully-managed service, which means AWS handles the operational aspects, such as cluster provisioning, maintenance, and scaling, allowing organizations to focus on developing applications and improving user experiences.
Amazon Personalize and Amazon OpenSearch Service Integration
When you use Amazon Personalize with Amazon OpenSearch Service, Amazon Personalize re-ranks OpenSearch Service results based on a user's past behavior, any metadata about the items, and any metadata about the user. OpenSearch Service then incorporates the re-ranking before returning the search response to your application. You control how much weight OpenSearch Service gives the ranking from Amazon Personalize when applying it to OpenSearch Service results.
With this re-ranking, results can be more engaging and relevant to a user's interests. This can lead to an increase in the click-through rate and conversion rate for your application. For example, you might have an ecommerce application that sells cars. If your user enters a query for Toyota cars and you don't personalize results, OpenSearch Service would return a list of cars made by Toyota based on keywords in your data. This list would be ranked in the same order for all users. However, if you were to use Amazon Personalize, OpenSearch Service would re-rank these cars in order of relevance for the specific user based on their behavior so that the car that the user is most likely to click is ranked first.
When you personalize OpenSearch Service results, you control how much weight (emphasis) OpenSearch Service gives the ranking from Amazon Personalize to deliver the most relevant results. For instance, if a user searches for a specific type of car from a specific year (such as a 2008 Toyota Prius), you might want to put more emphasis on the original ranking from OpenSearch Service than from Personalize. However, for more generic queries that result in a wide range of results (such as a search for all Toyota vehicles), you might put a high emphasis on personalization. This way, the cars at the top of the list are more relevant to the particular user.
How the Amazon Personalize Search Ranking plugin works
The following diagram shows how the Amazon Personalize Search Ranking plugin works.
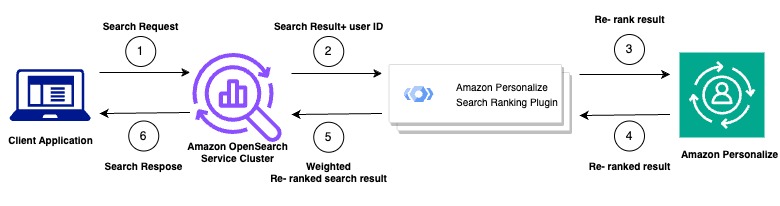
- You submit your customer's query to your Amazon OpenSearch Service Cluster
- OpenSearch Service sends the query response and the user's ID to the Amazon Personalize search ranking plugin.
- The plugin sends the items and user information to your Amazon Personalize campaign for ranking. It uses the recipe and campaign Amazon Resource Name (ARN) values within your search process to generate a personalized ranking for the user. This is done using the GetPersonalizedRanking API operation for recommendations. The user's ID and the items obtained from the OpenSearch Service query are included in the request.
- Amazon Personalize returns the re-ranked results to the plugin.
- The plugin organizes and returns these search results to your OpenSearch Service cluster. It re-ranks the results based on the feedback from your Amazon Personalize campaign and the emphasis on personalization that you've defined during setup.
- Finally, your OpenSearch Service cluster sends the finalized results back to your application.
Benefits of Amazon Personalize and Amazon OpenSearch Service Integration
Combining Amazon Personalize and Amazon OpenSearch Service maximizes user satisfaction through highly personalized search experiences:
Enhanced Relevance: The integration ensures that search results are tailored precisely to individual user preferences and behavior. Users are more likely to find what they are looking for quickly, resulting in a higher level of satisfaction.
Personalized Recommendations: Amazon Personalize's machine learning capabilities enable the generation of personalized recommendations within search results. This feature exposes users to items or content they may not have discovered otherwise, enriching their search experience.
User-Centric Experience: Personalized search results demonstrate that your platform understands and caters to each user's unique needs and preferences. This fosters a sense of appreciation and enhances user satisfaction.
Time Efficiency: Users can efficiently discover relevant content or products, saving time and effort in the search process.
Reduced Information Overload: Personalized search results also filter out irrelevant items to reduce information overload, making decision-making easier and more enjoyable.
Increased Engagement: Users are more likely to engage with content or products that resonate with their interests, leading to longer session durations and a greater likelihood of conversions.
Conclusion
Integrating Amazon Personalize and Amazon OpenSearch Service transforms user experiences, drives user engagement, and unlocks new growth opportunities for your platform or application. By embracing this innovative combination and encouraging its adoption, you can lead the way in delivering exceptional personalized search experiences in the digital age.

Highlighting Serverless Smarts at re:Invent 2023
Quiz-Takers Return Again and Again to Prove Their Serverless Knowledge
This past November, the Cloudtech team attended AWS re:Invent, the premier AWS customer event held in Las Vegas every year. Along with meeting customers and connecting with AWS teams, Cloudtech also sponsored the event with a booth at the re:Invent expo.
With a goal of engaging our re:Invent booth visitors and educating them on our mission to solve data problems with serverless technologies, we created our Serverless Smarts quiz. The quiz, powered by AWS, asked users to answer five questions about AWS serverless technologies, and scored quiz-takers based on accuracy and speed at which they answered the questions. Paired with a claw machine to award quiz-takers with a chance to win prizes, we saw increased interest in our booth from technical attendees ranging from CTOs to DevOps engineers.
But how did we do it? Read more below to see how we developed the quiz, the data we gathered, and key takeaways we’ll build on for re:Invent next year.
What We Built
Designed by our Principal Cloud Solutions Architect, the Serverless Smarts quiz was populated with 250 questions with four possible answers each, ranging in difficulty to assess the quiz-taker’s knowledge of AWS serverless technologies and related solutions. When a user would take the quiz, they would be presented with five questions from the database randomly, given 30 seconds to answer each, and the speed and accuracy of their answers would determine their overall score. This quiz was built in a way that could be adjusted in real-time, meaning we could react to customer feedback and outcomes if the quiz was too difficult or we weren’t seeing enough variance on the leaderboard. Our goal was to continually make improvements to give the quiz-taker the best experience possible.
The quiz application's architecture leveraged serverless technologies for efficiency and scalability. The backend consisted of AWS Lambda functions, orchestrated behind an API Gateway and further secured by CloudFront. The frontend utilized static web pages hosted on S3, also behind CloudFront. DynamoDB served as the serverless database, enabling real-time updates to the leaderboard through WebSocket APIs triggered by DynamoDB streams. The deployment was streamlined using the SAM template.
Please see the Quiz Architecture below:

What We Saw in the Data
As soon as re:Invent wrapped, we dived right into the data to extract insights. Our findings are summarized below:
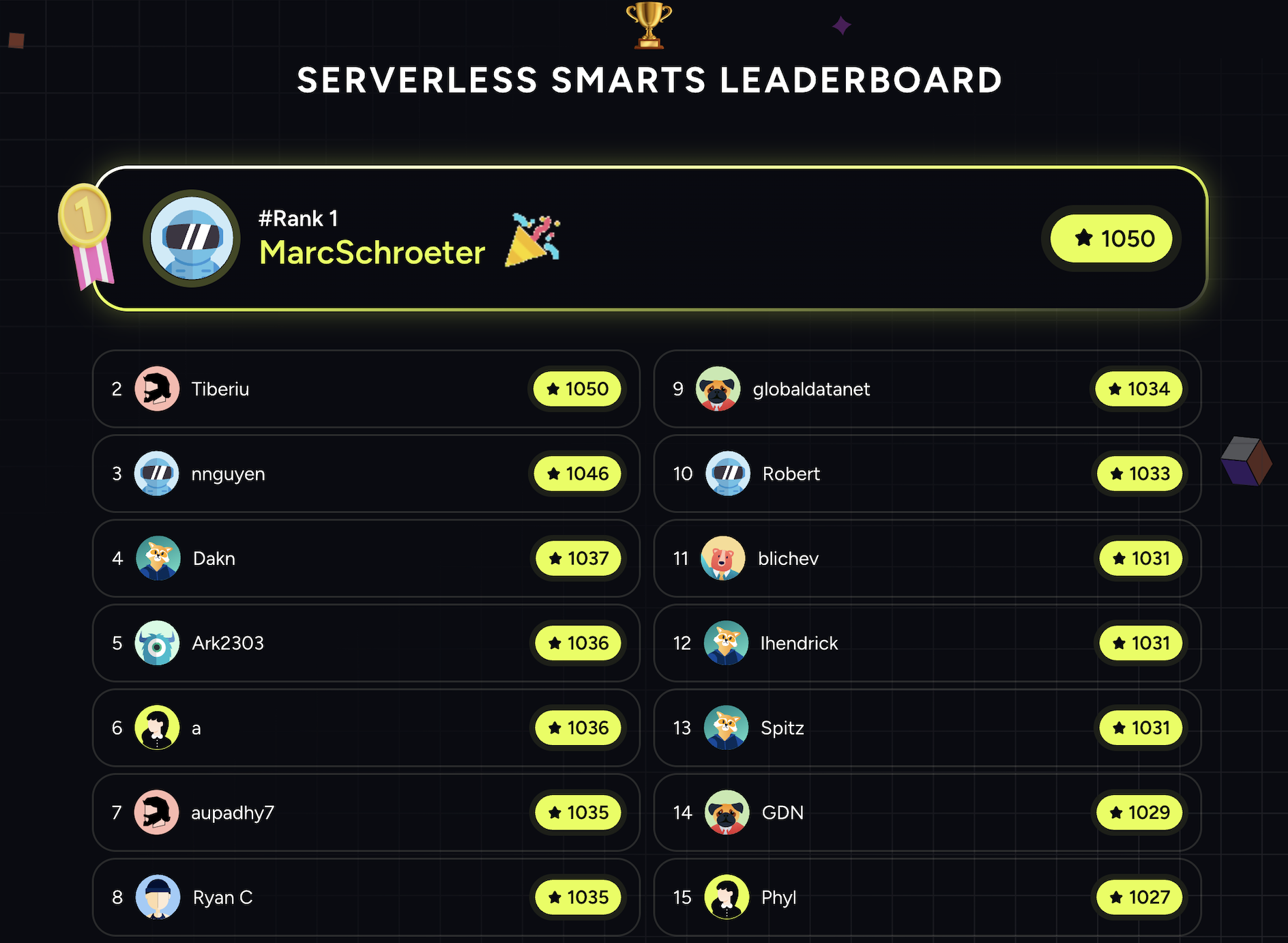
- Quiz and Quiz Again: The quiz was popular with repeat quiz-takers! With a total number of 1,298 unique quiz-takers and 3,627 quizzes completed, we saw an average of 2.75 quiz completions per user. Quiz-takers were intent on beating their score and showing up on the leaderboard, and we often had people at our booth taking the quiz multiple times in one day to try to out-do their past scores. It was so fun to cheer them on throughout the week.
- Everyone's a Winner: Serverless experts battled it out on the leaderboard. After just one day, our leaderboard was full of scores over 1,000, with the highest score at the end of the week being 1,050. We saw an average quiz score of 610, higher than the required 600 score to receive our Serverless Smarts credential badge. And even though we had a handful of quiz-takers score 0, everyone who took the quiz got to play our claw machine, so it was a win all around!
- Speed Matters: We saw quiz-takers soar above the pressure of answering our quiz questions quickly, knowing answers were scored on speed as well as accuracy. The average amount of time it took to complete the quiz was 1-2 minutes. We saw this time speed up as quiz-takers were working hard and fast to make it to the leaderboard, too.
- AWS Proved their Serverless Chops: As leaders in serverless computing and data management, AWS team members showed up in a big way. We had 118 people from AWS take our quiz, with an average score of 636 - 26 points above the average - truly showcasing their knowledge and expertise for their customers.
- We Made A Lot of New Friends: We had quiz-takers representing 794 businesses and organizations - a truly wide-ranging activity connecting with so many re:Invent attendees. Deloitte and IBM showed the most participation outside of AWS - I sure hope you all went back home and compared scores to showcase who reigns serverless supreme in your organizations!
Please see our Serverless Smarts Leaderboard below
What We Learned
Over the course of re:Invent, and our four days at our booth in the expo hall, our team gathered a variety of learnings. We proved (to ourselves) that we can create engaging and fun applications to give customers an experience they want to take with them.
We also learned that challenging our technology team to work together and injecting some fun and creativity into their building process combined with the power of AWS serverless products can deliver results for our customers.
Finally, we learned the value of thinking outside the box to deliver for customers is the key to long term success.
Conclusion
re:Invent 2023 was a success, not only in connecting directly with AWS customers, but also in learning how others in the industry are leveraging serverless technologies. All of this information helps Cloudtech solidify its approach as an exclusive AWS Partner and serverless implementation provider.
If you want to hear more about how Cloudtech helps businesses solve data problems with AWS serverless technologies, please connect with us - we would love to talk with you!
And we can’t wait until re:Invent 2024. See you there!

Enhancing Image Search with the Vector Engine for Amazon OpenSearch Serverless and Amazon Rekognition
Introduction
In today's fast-paced, high-tech landscape, the way businesses handle the discovery and utilization of their digital media assets can have a huge impact on their advertising, e-commerce, and content creation. The importance and demand for intelligent and accurate digital media asset searches is essential and has fueled businesses to be more innovative in how those assets are stored and searched, to meet the needs of their customers. Addressing both customers’ needs, and overall business needs of efficient asset search can be met by leveraging cloud computing and the cutting-edge prowess of artificial intelligence (AI) technologies.
Use Case Scenario
Now, let's dive right into a real-life scenario. An asset management company has an extensive library of digital image assets. Currently, their clients have no easy way to search for images based on embedded objects and content in the images. The company’s main objective is to provide an intelligent and accurate retrieval solution which will allow their clients to search based on embedded objects and content. So, to satisfy this objective, we introduce a formidable duo: the vector engine for Amazon OpenSearch Serverless, along with Amazon Rekognition. The combined strengths of Amazon Rekognition and OpenSearch Serverless will provide intelligent and accurate digital image search capabilities that will meet the company’s objective.
Architecture
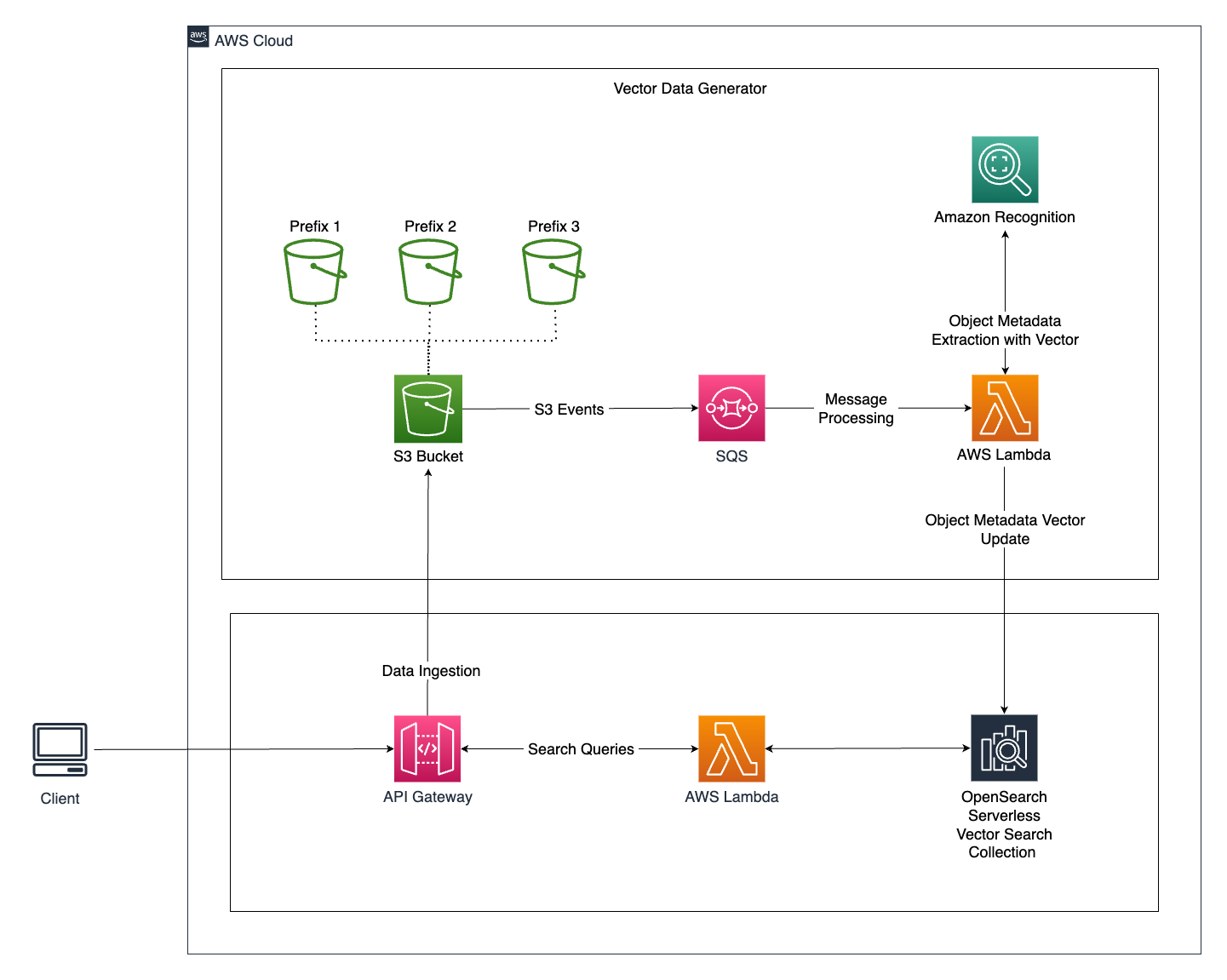
Architecture Overview
The architecture for this intelligent image search system consists of several key components that work together to deliver a smooth and responsive user experience. Let's take a closer look:
Vector engine for Amazon OpenSearch Serverless:
- The vector engine for OpenSearch Serverless serves as the core component for vector data storage and retrieval, allowing for highly efficient and scalable search operations.
Vector Data Generation:
- When a user uploads a new image to the application, the image is stored in an Amazon S3 Bucket.
- S3 event notifications are used to send events to an SQS Queue, which acts as a message processing system.
- The SQS Queue triggers a Lambda Function, which handles further processing. This approach ensures system resilience during traffic spikes by moderating the traffic to the Lambda function.
- The Lambda Function performs the following operations:
- Extracts metadata from images using Amazon Rekognition's `detect_labels` API call.
- Creates vector embeddings for the labels extracted from the image.
- Stores the vector data embeddings into the OpenSearch Vector Search Collection in a serverless manner.
- Labels are identified and marked as tags, which are then assigned to .jpeg formatted images.
Query the Search Engine:
- Users search for digital images within the application by specifying query parameters.
- The application queries the OpenSearch Vector Search Collection with these parameters.
- The Lambda Function then performs the search operation within the OpenSearch Vector Search Collection, retrieving images based on the entities used as metadata.
Advantages of Using the Vector Engine for Amazon OpenSearch Serverless
The choice to utilize the OpenSearch Vector Search Collection as a vector database for this use case offers significant advantages:
- Usability: Amazon OpenSearch Service provides a user-friendly experience, making it easier to set up and manage the vector search system.
- Scalability: The serverless architecture allows the system to scale automatically based on demand. This means that during high-traffic periods, the system can seamlessly handle increased loads without manual intervention.
- Availability: The managed AI/ML services provided by AWS ensure high availability, reducing the risk of service interruptions.
- Interoperability: OpenSearch's search features enhance the overall search experience by providing flexible query capabilities.
- Security: Leveraging AWS services ensures robust security protocols, helping protect sensitive data.
- Operational Efficiency: The serverless approach eliminates the need for manual provisioning, configuration, and tuning of clusters, streamlining operations.
- Flexible Pricing: The pay-as-you-go pricing model is cost-effective, as you only pay for the resources you consume, making it an economical choice for businesses.
Conclusion
The combined strengths of the vector engine for Amazon OpenSearch Serverless and Amazon Rekognition mark a new era of efficiency, cost-effectiveness, and heightened user satisfaction in intelligent and accurate digital media asset searches. This solution equips businesses with the tools to explore new possibilities, establishing itself as a vital asset for industries reliant on robust image management systems.
The benefits of this solution have been measured in these key areas:
- First, search efficiency has seen a remarkable 60% improvement. This translates into significantly enhanced user experiences, with clients and staff gaining swift and accurate access to the right images.
- Furthermore, the automated image metadata generation feature has slashed manual tagging efforts by a staggering 75%, resulting in substantial cost savings and freeing up valuable human resources. This not only guarantees data identification accuracy but also fosters consistency in asset management.
- In addition, the solution’s scalability has led to a 40% reduction in infrastructure costs. The serverless architecture permits cost-effective, on-demand scaling without the need for hefty hardware investments.
In summary, the fusion of the vector engine for Amazon OpenSearch Serverless and Amazon Rekognition for intelligent and accurate digital image search capabilities has proven to be a game-changer for businesses, especially for businesses seeking to leverage this type of solution to streamline and improve the utilization of their image repository for advertising, e-commerce, and content creation.
If you’re looking to modernize your cloud journey with AWS, and want to learn more about the serverless capabilities of Amazon OpenSearch Service, the vector engine, and other technologies, please contact us.
10 proven AWS migration strategies every SMB should know in 2025
For many small and medium-sized businesses (SMBs), moving to the cloud is no longer a question of if; it’s a matter of when and how. The challenge isn’t just about adopting the cloud, but choosing the right AWS migration strategy that fits business goals, budgets, and timelines.
AWS offers multiple migration paths, each designed for different needs and levels of cloud readiness, whether it’s reducing on-premise maintenance costs, improving performance, or building a more scalable foundation for growth.
This blog will break down 10 proven AWS migration strategies that help SMBs move smarter and get the most out of their modernization projects.
Key takeaways:
- Strategic AWS migration helps SMBs cut costs, boost scalability, and modernize operations for long-term business growth.
- AWS tools like Control Tower, MGN, and Redshift streamline governance, migration, and data optimization for SMBs.
- Building automation, resilience, and compliance into AWS migration ensures minimal downtime and maximum ROI.
- Continuous modernization post-migration keeps cloud environments agile, secure, and ready for future innovation.
- Cloudtech enables SMBs to migrate, modernize, and scale efficiently with AWS-based, business-aligned cloud solutions.
Why is strategic AWS migration essential for SMBs?
A strategic AWS migration can be a significant business enabler for SMBs. It helps SMBs modernize infrastructure, enhance agility, and optimize costs without the overhead of traditional IT systems.
Rather than lifting and shifting everything at once, a well-planned migration aligns cloud adoption with business goals, ensuring minimal disruption and maximum ROI.
Here’s why a strategic approach matters:
- Cost efficiency with purpose: Instead of overprovisioning resources, AWS allows SMBs to pay only for what they use, reducing waste and improving financial predictability.
- Business continuity and resilience: AWS ensures uptime through built-in redundancy, automated backups, and multi-AZ (Availability Zone) deployments.
- Scalability that grows with you: SMBs can scale workloads instantly to meet demand spikes, whether during patient data surges, sales peaks, or seasonal fluctuations.
- Enhanced innovation and competitiveness: By freeing teams from infrastructure maintenance, businesses can focus on innovation, product development, and better customer experiences.
A strategic AWS migration helps SMBs build a secure, scalable foundation that supports growth, accelerates innovation, and keeps operations resilient, setting the stage for long-term success in a digital-first world.
Suggested Read: Best practices for AWS resiliency: Building reliable clouds

10 essential AWS migration strategies for growing businesses
Migrating to the AWS Cloud isn’t a one-size-fits-all process. Every business has unique workloads, dependencies, and goals, which means choosing the right AWS migration strategy is critical to success. For growing SMBs, applying these strategies with AWS tools ensures better scalability, security, and long-term cost optimization.
Below are 10 AWS migration strategies, each with a practical AWS implementation path and the resulting business impact:
1. Define a clear cloud migration roadmap
A migration roadmap ensures every decision supports business priorities. It clarifies dependencies, timelines, and success metrics, minimizing surprises during implementation.
For SMBs, this structured approach simplifies planning and keeps teams aligned on outcomes like faster deployment, improved uptime, and measurable ROI from every phase of the cloud journey.
How to implement:
- Use AWS Migration Hub to track and visualize migration progress.
- Apply the AWS Cloud Adoption Framework (CAF) for readiness assessment.
- Prioritize workloads based on business value and technical complexity.
Outcome: SMBs gain a focused, step-by-step strategy that reduces uncertainty, avoids costly rework, and accelerates time-to-value. A defined roadmap transforms migration from a technical project into a strategic business enabler that drives confidence and alignment across teams.
2. Assess and prioritize workloads
Migrating everything at once can overwhelm small IT teams. A thorough assessment helps determine which applications deliver the fastest benefits post-migration and which require modernization.
This ensures the most critical systems, like customer data platforms or billing, receive the focus needed for security, performance, and reliability from day one.
How to implement:
- Use AWS Application Discovery Service to map dependencies.
- Evaluate workloads on cost, performance, and compliance needs.
- Sequence migrations starting with low-risk, high-value applications.
Outcome: A prioritized migration minimizes complexity, reduces disruption, and accelerates adoption. SMBs can achieve early wins, gain stakeholder confidence, and progressively migrate more complex systems with a clear understanding of risks and benefits.
3. Strengthen cloud security and compliance from day one
Embedding security at every stage of migration ensures protection for sensitive workloads and customer data. For SMBs handling regulated information, like healthcare or financial data, this approach prevents breaches, ensures compliance, and reduces remediation costs. A security-first mindset creates lasting trust and operational resilience in the cloud.
How to implement:
- Manage access using AWS IAM and AWS Organizations.
- Enable encryption with AWS KMS and threat detection via GuardDuty.
- Continuously audit environments with AWS Config and Audit Manager.
Outcome: Security and compliance become continuous, automated processes, not one-time checks. SMBs maintain full visibility, meet regulatory requirements, and operate confidently knowing data, systems, and customer privacy are protected.
4. Automate migration workflows
Automation simplifies migration, reduces downtime, and removes human error. For SMBs with limited teams, automation ensures workloads are deployed consistently and tested thoroughly.
By integrating Infrastructure as Code (IaC) and CI/CD pipelines, organizations can scale operations faster and adapt to changing business needs with minimal disruption.
How to implement:
- Automate workload migration using AWS Application Migration Service (MGN).
- Deploy infrastructure via AWS CloudFormation or Terraform.
- Integrate testing and deployment through AWS CodePipeline.
Outcome: Automation delivers faster, error-free migrations and repeatable processes. SMBs achieve shorter timelines, consistent environments, and higher confidence in post-migration stability, freeing teams to focus on innovation instead of manual maintenance.
5. Optimize data migration and storage
Data is the lifeblood of modern businesses. Efficient, secure migration ensures minimal disruption and zero data loss. For SMBs, optimizing storage means balancing performance and cost, whether migrating transactional databases, analytics platforms, or file archives. This sets the stage for better insights and faster decision-making.
How to implement:
- Transfer large datasets using AWS DataSync or AWS Snowball.
- Migrate databases seamlessly with AWS Database Migration Service (DMS).
- Store and archive efficiently using Amazon S3 and S3 Glacier.
Outcome: A smooth data migration ensures high data integrity, minimal downtime, and predictable costs. SMBs gain flexible access to reliable, scalable storage that supports analytics, compliance, and future AI initiatives.
6. Enable observability and performance monitoring
Once workloads are live, visibility is critical. Proactive monitoring helps SMBs identify issues early, optimize performance, and ensure predictable user experiences. Continuous observability also strengthens compliance, enabling teams to maintain operational excellence with fewer resources and greater agility.
How to implement:
- Track system metrics using Amazon CloudWatch.
- Maintain audit trails with AWS CloudTrail.
- Use AWS X-Ray and Trusted Advisor for performance insights.
Outcome: Full visibility into cloud environments reduces downtime and improves responsiveness. SMBs can resolve issues faster, maintain compliance, and enhance end-user satisfaction with reliable and transparent cloud operations.
7. Build for resilience and disaster recovery
Disaster recovery isn’t just for large enterprises. For SMBs, even a short outage can lead to data loss or financial impact. Building resilience into AWS architecture through redundancy, automation, and failover planning ensures systems remain available even in the face of unexpected failures or disasters.
How to implement:
- Use multi-AZ deployments for fault tolerance.
- Implement backups using AWS Backup and Amazon RDS snapshots.
- Configure failover routing through Amazon Route 53.
Outcome: Business continuity becomes part of everyday operations. SMBs can recover faster, minimize downtime, and maintain customer trust by ensuring critical systems remain accessible and secure during disruptions.
8. Focus on cost management and optimization
Without governance, cloud costs can escalate quickly. Cost optimization strategies allow SMBs to scale efficiently while staying within budget. By monitoring usage, right-sizing resources, and automating cost controls, businesses can ensure they pay only for what delivers measurable value.
How to implement:
- Track spending with AWS Cost Explorer and Budgets.
- Use Savings Plans or Reserved Instances for steady workloads.
- Identify waste through AWS Trusted Advisor recommendations.
Outcome: Predictable, optimized costs free SMBs from financial surprises. Every dollar spent on AWS contributes directly to performance, innovation, and growth.
9. Upskill teams and foster a cloud-first culture
Technology adoption fails without skilled teams. Training staff ensures migration success and long-term cloud maturity. When teams understand AWS tools and best practices, they make faster, better decisions—turning the cloud into a strategic asset rather than a technical dependency.
How to implement:
- Offer training via AWS Skill Builder or Cloud Practitioner Essentials.
- Host AWS Immersion Days for practical learning.
- Build internal “cloud champions” for peer enablement.
Outcome: Empowered teams confidently manage and optimize cloud operations. This independence reduces reliance on external support and fosters innovation across departments.
10. Continuously optimize and modernize post-migration
Migration isn’t a finish line; it’s the beginning of continuous improvement. Post-migration optimization helps SMBs refine performance, reduce costs, and adapt architectures as business needs evolve. Modernization ensures that the cloud environment remains scalable, secure, and aligned with long-term strategic goals.
How to implement:
- Use the AWS Well-Architected Tool for regular architecture reviews.
- Modernize workloads using AWS Lambda, Amazon ECS, or Fargate.
- Enable AI and analytics through Amazon Q Business or Redshift.
Outcome: An optimized cloud environment delivers sustained value, including better performance, lower operational overhead, and readiness for future technologies. SMBs stay agile, competitive, and future-proof.
AWS migration success depends on strategy, not speed. By focusing on planning, automation, governance, and continuous optimization, SMBs can build a future-ready AWS environment that supports innovation, resilience, and measurable business growth, without overextending budgets or teams.
Also Read: AWS cost optimization strategies and best practices.

How does Cloudtech help SMBs implement AWS migration strategies?
For most SMBs, AWS migration is about building a secure, efficient, and future-ready foundation. Cloudtech simplifies this process through an AWS-based, SMB-first approach focused on modernization, resiliency, and measurable business outcomes.
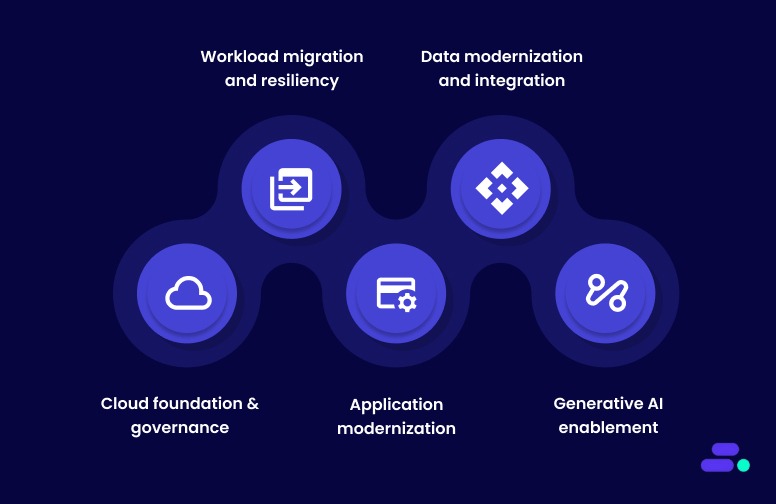
Here’s how Cloudtech enables successful AWS migration for growing businesses:
- Cloud foundation and governance: Cloudtech establishes secure AWS multi-account environments using AWS Control Tower, AWS Organizations, and AWS IAM. This ensures strong governance, identity management, and cost visibility from the start of the migration journey.
- Workload migration and resiliency: Using AWS Application Migration Service, AWS Backup, and Amazon Route 53, Cloudtech delivers structured migration plans with built-in disaster recovery, ensuring low disruption and high availability across critical workloads.
- Application modernization: Cloudtech modernizes legacy applications into scalable, serverless architectures using AWS Lambda, Amazon ECS, and Amazon EventBridge. This improves performance, reduces operational overhead, and enhances agility for faster innovation.
- Data modernization and integration: Through Amazon S3, AWS Glue, and Amazon Redshift, Cloudtech builds unified, cloud-native data foundations that support analytics, reporting, and intelligent automation across business functions.
- Generative AI enablement: Cloudtech helps SMBs unlock new capabilities using Amazon Q Business, Amazon Bedrock, and AWS data services, enabling practical AI solutions such as intelligent document processing and conversational analytics.
Cloudtech’s proven AWS migration methodology ensures SMBs don’t just move to the cloud; they modernize, optimize, and scale securely. The result is an AWS environment built for efficiency, compliance, and long-term business growth.
See how other SMBs have modernized, scaled, and thrived with Cloudtech’s support →
Also Read: Common security pitfalls during cloud migration, and how to avoid them

Conclusion
AWS cloud migration strategies offer businesses the flexibility to choose the right approach based on their unique needs, goals, and existing infrastructure. Whether opting for a quick "Lift and Shift" or a more involved "Re-architect" strategy, businesses can unlock enhanced scalability, security, and cost savings. The right migration strategy can set the foundation for future growth and efficiency.
For SMBs looking to fully utilize their cloud services, a partner like Cloudtech provides personalized AWS solutions, including infrastructure optimization, data management, and application modernization. Cloudtech’s expertise ensures businesses maximize the potential of their cloud environment, helping them scale and stay ahead in today’s competitive landscape.
Schedule a call with Cloudtech today to see how they can drive growth through secure, high-performing cloud solutions.
FAQs
1. What is the most common AWS cloud migration strategy for small businesses?
A: For small businesses, the "Rehost" (Lift and Shift) strategy is often the most common. It allows for quick migration to the cloud with minimal changes to existing applications, making it a cost-effective and straightforward option.
2. How do I know which AWS migration strategy is right for my business?
A: The right strategy depends on the business’s needs, current infrastructure, and long-term goals. If businesses need a quick move, "Rehost" may be ideal, while "Refactor" could be better to fully optimize for the cloud. Working with a cloud consultant can help determine the best fit.
3. How does the "Repurchase" strategy work?
A: "Repurchase" involves moving to a new, cloud-native application by switching to a software-as-a-service (SaaS) solution, rather than maintaining legacy systems. This strategy is ideal for businesses seeking modern, out-of-the-box cloud solutions with less complexity.
4. How can Cloudtech help my business with AWS cloud migration?
A: Cloudtech specializes in AWS infrastructure optimization, data management, and application modernization. Their tailored solutions can streamline operations, improve scalability, and ensure high security for industries like healthcare and fintech.
5. Can businesses retain certain applications on-premise while migrating others to the cloud?
A: Yes, the "Retain" (Revisit) strategy allows businesses to keep specific applications on-premise due to compliance, security, or other business-specific reasons, while migrating other workloads to the cloud for efficiency and growth.

A Guide to Conversational AI in Healthcare
A busy physician on morning rounds, speaking into their phone for just 30-45 seconds about a patient's condition. By the time they move to the next room, a complete progress note is ready for their EMR, detailed and written in their own style. No hours spent on documentation after shift. No administrative burden cutting into patient care time.
This is now a reality.
In August 2025, Pieces Technologies launched "Pieces in your Pocket," an AI-powered assistant that's reducing documentation time for inpatient physicians by 50%. The tool doesn't simply transcribe words, but understands context, learns from prior notes, and adapts to each physician's documentation style to generate clinical-quality records from brief voice interactions.
This innovation represents a broader shift happening across healthcare, driven by Conversational AI. Virtual assistants and voice agents are increasingly taking on essential roles, from clinical documentation and decision support to patient follow-ups and care coordination, fundamentally changing how healthcare is delivered.
This guide explores how Conversational AI is transforming healthcare, the technologies powering this change, and the real-world benefits for patients, providers, and healthcare organizations.
Quick Glance
- Conversational AI in healthcare refers to AI systems that enable human-like interactions between patients and healthcare providers, improving engagement and operational efficiency.
- Key use cases include 24/7 patient support, symptom triage, appointment scheduling, medication management, and remote patient monitoring.
- Challenges in implementing Conversational AI include ensuring data privacy and security, integration with existing systems, and maintaining high response accuracy.
- Cloudtech offers tailored Conversational AI solutions for healthcare, helping providers implement AI-driven tools that streamline operations and improve patient care.
- The future of Conversational AI in healthcare includes proactive health monitoring, personalized medicine, enhanced virtual assistants, and seamless integration with EHRs.
What is Conversational AI in healthcare?
Conversational AI in healthcare refers to the use of AI technologies to facilitate human-like interactions between patients and healthcare systems.
It can understand and respond to both text and voice inputs using tools like Natural Language Processing (NLP), speech recognition, and machine learning. This makes it a crucial technology for automating a wide range of healthcare processes, reducing human workload, and providing patients with personalized, 24/7 assistance.
In essence, Conversational AI helps healthcare providers offer interactive, efficient, and scalable services without human intervention. It enhances the overall patient experience by providing quick, accurate answers to common queries and streamlining a variety of operational tasks. Whether it's helping patients schedule appointments, manage medications, or get immediate health advice, Conversational AI is transforming how healthcare systems interact with both patients and providers.
Now that we have a clear understanding of what Conversational AI entails, let’s check out a few use cases that reveal the massive potential of this technology.
Key use cases of Conversational AI in healthcare
Conversational AI is making a profound impact across the healthcare sector, addressing various challenges by improving patient engagement, streamlining processes, and enhancing decision-making. Below are some key use cases where Conversational AI is being applied effectively:
1. 24/7 patient support and virtual assistants
AI-powered virtual assistants offer patients real-time, on-demand responses to common queries, such as symptoms, medication information, and appointment scheduling. These assistants work around the clock, providing patients with immediate access to vital information, improving overall satisfaction of the patients.
- Benefits:
- Round-the-clock availability.
- Instant access to healthcare information.
- Reduced workload for administrative staff.
2. Appointment scheduling and reminders
Scheduling appointments in a healthcare setting can be cumbersome and time-consuming for both patients and providers. Conversational AI simplifies this process by allowing patients to book, reschedule, and cancel appointments. It is as simple as having a conversation with a personal assistant. Additionally, the AI system can send reminders and follow-up notifications to reduce no-shows and ensure that appointments run on time.
- Benefits:
- Improved appointment booking efficiency.
- Reduced no-show rates.
- Automated reminders and follow-ups.
3. Symptom triage and guidance
Conversational AI can assist with symptom triage, guiding patients through a series of questions to assess their symptoms. It can also determine whether the patients need immediate medical attention or a visit to the doctor. By analyzing the responses, AI-powered systems can provide initial guidance, such as suggesting over-the-counter treatments, booking a doctor’s appointment, or advising the patient to seek urgent care.
- Benefits:
- Faster symptom assessment.
- Reduces unnecessary visits to the hospital or clinic.
- Enhances early detection and intervention.
4. Medication management
AI-powered systems help manage patients' medication schedules by reminding them when to take their medication, offering dosage information, and tracking adherence. These systems can also alert patients about potential side effects and offer guidance on medication management.
- Benefits:
- Improved medication adherence.
- Reduces the risk of medication errors.
- Personalized reminders and alerts.
5. Remote patient monitoring and chronic care management
For patients with chronic conditions, ongoing monitoring is essential. Conversational AI, integrated with remote monitoring tools, can keep track of patients’ health data, such as blood pressure, glucose levels, or heart rate, and send real-time updates to both patients and healthcare providers. This proactive approach to care ensures timely interventions and reduces hospital readmissions.
- Benefits:
- Continuous monitoring of chronic conditions.
- Early detection of potential issues.
- Better management of long-term health conditions.
Want to give your patients interactions that feel human, not robotic, while saving your team hours? Discover Cloudtech’s AI Voice Calling today.
Now, Let’s take a closer look at some real-world examples where Conversational AI has already made a significant impact, and see how it continues to shape the future of healthcare delivery.
Real-world applications of Conversational AI in healthcare
The integration of Conversational AI in healthcare has led to transformative outcomes, as evidenced by various case studies and industry analyses.
For example, when the COVID-19 pandemic accelerated the adoption of digital health solutions, 72.5% of patients utilized front-end conversational AI voice agents or symptom checkers during virtual visits. This led to an increase in AI-driven patient engagement platforms in modern healthcare delivery.
Here is another example:
To enhance patient engagement and streamline administrative tasks, a prominent healthcare provider implemented an AI-driven voice agent system. This system was designed to handle a variety of patient interactions, including appointment scheduling, medication reminders, and general inquiries.
The AI voice agent utilizes advanced Natural Language Processing (NLP) and Machine Learning (ML) algorithms to understand and respond to patient queries in real-time. Integrated with the healthcare provider's Electronic Health Record (EHR) system, the voice agent can access patient information to provide personalized responses and schedule appointments accordingly.
Additionally, the system is capable of sending automated reminders for upcoming appointments and medication refills, thereby improving patient adherence to treatment plans. The voice agent also assists in triaging patient inquiries, directing them to the appropriate department or healthcare professional when necessary.
Results and Benefits
- Improved Patient Access: The AI voice agent operates 24/7, allowing patients to access information and services at their convenience, reducing wait times and enhancing satisfaction.
- Operational Efficiency: By automating routine tasks, the healthcare provider has freed up staff to focus on more complex patient needs, leading to improved workflow efficiency.
- Enhanced Patient Adherence: Automated reminders have contributed to better patient adherence to appointments and medication regimens, potentially leading to improved health outcomes.
- Cost Savings: The implementation of the AI voice agent has resulted in cost savings by reducing the need for additional administrative staff and minimizing scheduling errors.
While the integration of voice AI in healthcare presents numerous advantages, challenges such as ensuring data privacy, maintaining system accuracy, and achieving seamless integration with existing EHR systems remain. Addressing these challenges is crucial for the successful adoption and sustained impact of AI voice agents in healthcare settings.
Challenges and considerations for implementing Conversational AI in healthcare
While the advantages of Conversational AI in healthcare are significant, the implementation of such technology comes with its own set of challenges and considerations. Healthcare organizations must carefully assess these challenges to ensure a smooth and successful integration of Conversational AI into their operations. Below are some key challenges and factors that healthcare providers need to keep in mind when adopting Conversational AI solutions:
1. Data privacy and security concerns
The sensitive nature of healthcare data demands data privacy and security when implementing Conversational AI systems. Patient information is protected by strict regulations such as HIPAA (Health Insurance Portability and Accountability Act) in the U.S., and non-compliance can lead to severe consequences.
AI systems must adhere to these regulatory standards to safeguard patient data and maintain confidentiality. Additionally, AI-powered tools that process health data need robust encryption protocols, secure access controls, and frequent audits to prevent unauthorized access.
Considerations:
- Work with trusted vendors that provide compliant AI systems.
- Ensure data encryption, role-based access control, and regular security audits.
- Design AI systems with built-in privacy by design to mitigate risks.
2. Integration with existing healthcare systems
Integrating Conversational AI with existing healthcare IT systems, such as EHRs (Electronic Health Records), EMRs (Electronic Medical Records), practice management systems, and other clinical applications, can be a complex process. A lack of seamless integration could lead to workflow disruptions, inefficiencies, and system conflicts. For instance, a virtual assistant may struggle to pull up patient data from an outdated system or fail to update records in real-time, causing discrepancies in patient information.
Considerations:
- Choose AI solutions that offer robust API integrations with existing systems.
- Ensure smooth data synchronization between Conversational AI and backend systems.
- Collaborate with IT teams to ensure proper configuration and testing before deployment.
3. High Initial Setup Costs and ROI Concerns
The initial investment in Conversational AI technology can be substantial, especially when considering development costs, system integration, and customization for specific healthcare needs. While AI systems can ultimately lead to cost savings through automation and operational efficiency, the return on investment (ROI) may take time to materialize. Healthcare organizations must assess whether they have the budget for such a project and whether the potential benefits justify the upfront costs.
Considerations:
- Perform a cost-benefit analysis to understand potential savings and improvements in patient care.
- Start with pilot projects to test AI capabilities before full-scale deployment.
- Look for AI solutions with scalable pricing models to reduce initial costs.
4. Training and Adoption by Healthcare Staff
For Conversational AI to function optimally, healthcare providers need to ensure their staff are properly trained to work alongside the new system. This includes training on how to interact with AI tools, how to escalate complex cases to human agents, and how to leverage AI to enhance patient care. Resistance from staff or lack of training can lead to underutilization of the technology and hinder its effectiveness.
Considerations:
- Invest in comprehensive training for healthcare professionals and administrative staff.
- Highlight the benefits of AI such as reduced workloads and improved patient outcomes to encourage adoption.
- Implement feedback mechanisms to gather input from staff on AI performance and usability.
5. Ensuring Accuracy and Quality of AI Responses
While Conversational AI can handle many types of queries, it is still an evolving technology, and AI systems are not infallible. The accuracy of responses is critical, especially in healthcare, where providing incorrect information can lead to adverse outcomes.
Considerations:
- Use AI systems that are regularly updated and trained on the latest medical knowledge and terminology.
- Implement human oversight to review AI responses, especially in critical healthcare situations.
- Use machine learning algorithms to refine AI understanding based on real-world data and patient feedback.
6. Ethical and Legal Concerns
The implementation of Conversational AI in healthcare raises several ethical and legal concerns, especially around patient privacy, consent, and accountability. For example, if an AI system provides incorrect advice that leads to harm, who is liable—the healthcare provider, the AI vendor, or the system itself? Addressing these questions is essential to avoid potential legal complications and ensure that AI tools are being used responsibly and ethically.
Considerations:
- Establish clear guidelines around the use of AI in patient care, ensuring that human oversight is maintained in critical cases.
- Connect with legal teams to ensure compliance with healthcare regulations (e.g., HIPAA).
- Adopt transparent AI policies that respect patient privacy and consent.
7. Continuous Monitoring and Improvement
Conversational AI is not a “set it and forget it” solution. It requires continuous monitoring and fine-tuning to ensure it evolves with changing patient needs, healthcare regulations, and medical advances. Regular updates and retraining are essential to ensure that the system remains effective, efficient, and accurate over time.
Considerations:
- Set up a dedicated team to monitor AI performance and handle updates.
- Establish metrics for AI performance to track improvements and address any deficiencies.
- Schedule regular audits of the AI system to ensure compliance with healthcare standards.
Want to overcome the challenges of Conversational AI implementation in healthcare? Connect with Cloudtech today to explore tailored solutions that address these challenges and unlock the potential of AI-powered patient engagement.
As we look ahead, the future of Conversational AI in healthcare holds immense promise.
The future of Conversational AI in healthcare
Conversational AI in healthcare is filled with possibilities that can revolutionize patient care and improve operational efficiency. As AI continues to advance, its role in healthcare will only grow, bringing even more sophisticated solutions to address the evolving needs of patients and providers alike.
Here’s a look at the key trends and emerging examples that will shape the future of Conversational AI in healthcare:
1. Proactive health monitoring and preventive care
One of the most exciting advancements in Conversational AI is the potential for proactive health monitoring. In the future, AI systems will not just respond to patient queries but will take a proactive role in predicting health issues before they arise. By integrating AI with wearable devices, sensors, and health apps, Conversational AI can offer real-time health monitoring, flagging potential issues based on a patient’s vitals or behavior patterns.
Example: AI-powered systems, integrated with wearables like fitness trackers or smartwatches, could monitor vital signs such as heart rate, blood pressure, or blood sugar levels. If the system detects abnormal readings, it could send notifications to the patient or even alert healthcare providers to take preventative action. For instance, an AI assistant could remind a diabetic patient to adjust their insulin levels based on real-time glucose measurements.
Impact: This proactive approach can help in the early detection of chronic conditions, preventing complications and improving patient outcomes.
2. AI-driven personalized medicine
As personalized medicine gains more prominence, Conversational AI will play a significant role in delivering individualized care. By leveraging genetic data, patient history, and real-time health data, AI systems will provide tailored treatment plans that consider each patient's unique health profile.
Example: Imagine an AI assistant integrated into a cancer care center’s workflow. The system could analyze a patient’s genomic data along with previous treatment responses to recommend personalized cancer treatments. It could suggest specific medications or therapy regimens that have shown the highest likelihood of success based on the patient’s unique genetic makeup and past medical history.
Impact: Personalized treatment plans that factor in the specific biology of the patient can increase the effectiveness of treatments and reduce the risk of adverse reactions, offering more precise care for complex health conditions.
3. Enhanced virtual health assistants and voice agents
In the near future, virtual health assistants powered by Conversational AI will be able to conduct more sophisticated medical conversations. These assistants will go beyond basic symptom triage or appointment scheduling and will evolve to provide continuous, holistic health guidance across multiple touchpoints.
Example: AI health assistants could monitor patients' symptoms over time, keeping track of ongoing concerns and making suggestions based on the patient’s evolving condition. For example, an AI-powered assistant for managing mental health might ask about a user’s mood, suggest coping strategies, and recommend professional therapy sessions if necessary.
Impact: Such systems will not only make healthcare more accessible and convenient but also reduce the burden on medical staff by automating routine interactions. This allows providers to focus on more difficult patient care tasks.
4. AI in remote care and telemedicine
As telemedicine becomes more widely adopted, Conversational AI will play a crucial role in facilitating patient interactions and ensuring that consultations are efficient and comprehensive. AI assistants will enable remote consultations, help with administrative tasks, and provide immediate responses to basic health concerns, improving the efficiency of virtual healthcare delivery.
Example: In a telemedicine consultation, an AI assistant could handle pre-consultation processes, such as collecting patient history, validating insurance information, and analyzing symptoms. During the consultation, AI can assist healthcare providers by suggesting potential diagnoses based on the patient’s input and medical records, making the consultation process faster and more accurate.
Impact: Telemedicine platforms that integrate Conversational AI will offer seamless, 24/7 virtual care and improve access to healthcare in underserved areas.
5. Multilingual support for global healthcare access
As healthcare becomes more globalized, multilingual support powered by Conversational AI will be essential to ensuring that patients from different linguistic backgrounds can access healthcare services without barriers.
Example: A global health network could deploy AI-powered systems that can speak multiple languages. For instance, a patient from Spain could interact with an AI assistant in Spanish to book an appointment with an English-speaking doctor. The AI could seamlessly translate between the patient and the healthcare provider, ensuring there are no communication barriers.
Impact: This will greatly improve the accessibility of healthcare services for non-English-speaking populations, ensuring equitable access to care worldwide.
6. Seamless integration with EHRs and other healthcare systems
In the future, Conversational AI will be able to seamlessly integrate with Electronic Health Records (EHRs), practice management systems, and healthcare workflows. This integration will ensure that patient data flows smoothly between the AI system and the healthcare provider’s backend systems, enabling better coordination of care.
Example: A patient reaches out to an AI assistant for a prescription refill. The assistant can pull up the patient’s EHR, confirm the current medication, and even notify the healthcare provider of the refill request. The AI can automatically request approval from the doctor’s office and send the prescription to the pharmacy, all without human intervention.
Impact: This will streamline administrative workflows and ensure data consistency across systems, enabling healthcare providers to offer more coordinated and effective care.
7. AI for healthcare fraud detection and compliance
With growing concerns over fraud and compliance in healthcare, Conversational AI will become an important tool for identifying suspicious activities and ensuring adherence to regulatory standards. AI-powered systems can flag unusual billing patterns, monitor claims for discrepancies, and ensure that providers follow compliance guidelines.
Example: An AI system could monitor insurance claims and detect discrepancies in real-time, alerting healthcare organizations about potential fraud. It can also help with HIPAA compliance by ensuring that patient data is handled securely during AI interactions, preventing unauthorized access or misuse.
Impact: Conversational AI will enhance fraud prevention and streamline compliance processes, helping healthcare organizations reduce risk and protect patient data.
8. AI-Powered medical research assistance
AI-driven systems can assist researchers in data mining, reviewing literature, and identifying potential clinical trials that match patient profiles.
Example: An AI assistant could help oncologists by quickly reviewing the latest cancer research and suggesting new treatment options based on recent breakthroughs. It could also match patients with ongoing clinical trials based on their medical history and eligibility criteria.
Impact: Conversational AI will accelerate research efforts, improve the accuracy of findings, and ensure that the most up-to-date medical knowledge is readily available to healthcare professionals.
Conclusion
The healthcare industry is at the cusp of a major transformation, and Conversational AI is leading the charge. By enabling smarter, more efficient interactions, it not only enhances patient engagement but also streamlines administrative workflows, helping healthcare providers focus more on patient care. Whether it’s assisting patients with appointment scheduling, providing medication reminders, or offering 24/7 support, Conversational AI is proving to be a game-changer.
Cloudtech is committed to helping healthcare providers integrate Conversational AI solutions that enhance patient care, improve operational efficiency, and ensure compliance with industry standards. With deep expertise in AI and healthcare systems, Cloudtech offers tailored solutions that help your organization unlock the full potential of Conversational AI.
Ready to elevate your healthcare experience with Conversational AI?
Connect with Cloudtech and start building the future of customer experience.
Frequently Asked Questions (FAQs)
1. What is Conversational AI in healthcare?
Conversational AI in healthcare refers to the use of AI technologies to facilitate human-like interactions between patients and healthcare systems, enabling tasks such as appointment scheduling, medication reminders, and symptom triage.
2. How can Conversational AI improve patient care?
By providing instant, personalized responses, Conversational AI enhances patient engagement, ensures timely information delivery, and supports better health outcomes.
3. Is Conversational AI secure for handling patient data?
Yes, when implemented with proper security measures and compliance with regulations like HIPAA, Conversational AI can securely handle patient data.
4. Can Conversational AI integrate with existing healthcare systems?
Absolutely. Conversational AI solutions can be integrated with healthcare systems like Electronic Health Records (EHR) to streamline workflows and improve efficiency.
Get started on your cloud modernization journey today!
Let Cloudtech build a modern AWS infrastructure that’s right for your business.